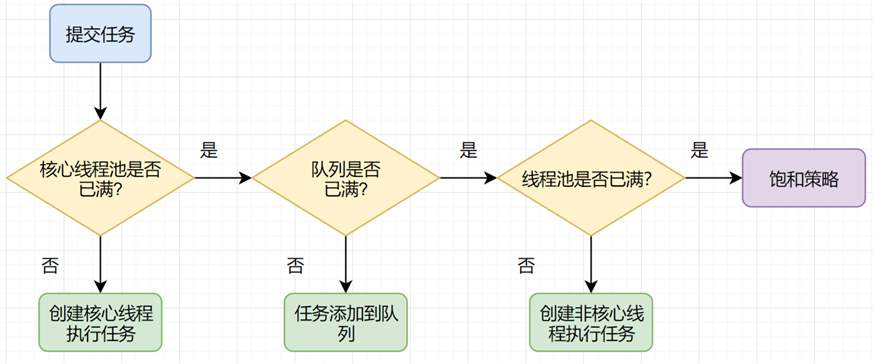
当一个任务通过execute(Runnable)方法欲添加到线程池时:
1、如果此时线程池中的数量小于corePoolSize,即使线程池中的线程都处于空闲状态,也要创建新的线程来处理被添加的任务。
2、如果此时线程池中的数量等于 corePoolSize,但是缓冲队列 workQueue未满,那么任务被放入缓冲队列workQueue中,等待线程池中线程调度执行。
3、如果此时线程池中的数量大于corePoolSize,缓冲队列workQueue满,并且线程池中的数量小于maximumPoolSize,建新的线程来处理被添加的任务。
4、当线程池中的线程执行完任务空闲时,会尝试从workQueue中取头结点任务执行。
5、如果此时线程池中的数量大于corePoolSize,缓冲队列workQueue满,并且线程池中的数量等于maximumPoolSize,那么通过 handler所指定的策略来处理此任务。也就是:处理任务的优先级为:核心线程corePoolSize、任务队列workQueue、最大线程maximumPoolSize,如果三者都满了,使用handler处理被拒绝的任务。
6、当线程池中线程数超过corePoolSize,并且配置allowCoreThreadTimeOut=true,空闲时间超过keepAliveTime的线程会被销毁,保持线程池中线程数为corePoolSize。(注:销毁空闲线程,保持线程数为corePoolSize,不是销毁corePoolSize中的线程。)
再看看源码java.util.concurrent.ThreadPoolExecutor.java
public void execute(Runnable command) { if (command == null) throw new NullPointerException(); int c = ctl.get(); //判断当前活跃线程数是否小于corePoolSize if (workerCountOf(c) < corePoolSize) { //如果小于,则调用addWorker创建线程执行任务 if (addWorker(command, true)) return; c = ctl.get(); } //如果大于等于corePoolSize,则将任务添加到workQueue队列 if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get(); if (! isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0) addWorker(null, false); } //如果放入workQueue队列失败,则创建非核心线程执行任务 else if (!addWorker(command, false)) reject(command); }
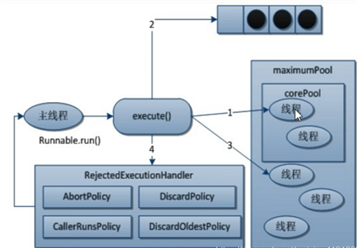
附一个线程池底层示意图:
创建线程池对象,强烈建议通过使用ThreadPoolExecutor的构造方法创建,不要使用Executors
阿里《Java开发手册》中的一段描述。
【强制】线程池不允许使用Executors创建,建议通过ThreadPoolExecutor的方式创建,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
说明:Executors返回的线程池对象的弊端如下:
1.FixedThreadPool和SingleThreadPool: 允许的请求队列长度为Integet.MAX_VALUE,可能会堆积大量的请求从而导致OOM;
2.CachedThreadPool: 允许创建线程数量为Integet.MAX_VALUE,可能会创建大量的线程,从而导致OOM.
使用自定义线程工厂:当项目规模逐渐扩展,各系统中线程池也不断增多,当发生线程执行问题时,通过自定义线程工厂创建的线程设置有意义的线程名称可快速追踪异常原因,高效、快速的定位问题。
使用自定义拒绝策略:虽然,JDK给我们提供了一些默认的拒绝策略,但我们可以根据项目需求的需要,或者是用户体验的需要,定制拒绝策略,完成特殊需求。
线程池划分隔离:不同业务、执行效率不同的分不同线程池,避免因某些异常导致整个线程池利用率下降或直接不可用,进而影响整个系统或其它系统的正常运行。
合理配置线程池
分两种情况:
CPU密集
CPU密集的意思是该任务需要大量的运算,而没有阻塞,CPU一直全速运行。
CPU密集任务只有在真正的多核CPU上才可能得到加速(通过多线程),而在单核CPU上,无论你开几个模拟的多线程,该任务都不可能得到加速,因为CPU总的运算能力就那些。
IO密集
IO密集型,即该任务需要大量的IO,即大量的阻塞。在单线程上运行IO密集型的任务会导致浪费大量的CPU运算能力浪费在等待。所以在IO密集型任务中使用多线程可以大大的加速程序运行,即时在单核CPU上,这种加速主要就是利用了被浪费掉的阻塞时间。
要想合理的配置线程池的大小,首先得分析任务的特性,可以从以下几个角度分析:
任务的性质:CPU密集型任务、IO密集型任务、混合型任务。
任务的优先级:高、中、低。
任务的执行时间:长、中、短。
任务的依赖性:是否依赖其他系统资源,如数据库连接等。
性质不同的任务可以交给不同规模的线程池执行:
CPU密集型任务应配置尽可能小的线程,如配置CPU个数+1的线程数,
IO密集型任务应配置尽可能多的线程,因为IO操作不占用CPU,不要让CPU闲下来,应加大线程数量,如配置两倍CPU个数+1,
对于混合型的任务,如果可以拆分,拆分成IO密集型和CPU密集型分别处理,前提是两者运行的时间是差不多的,如果处理时间相差很大,则没必要拆分了。
若任务对其他系统资源有依赖,如某个任务依赖数据库的连接返回的结果,这时候等待的时间越长,则CPU空闲的时间越长,那么线程数量应设置得越大,才能更好的利用CPU。
当然具体合理线程池值大小,需要结合系统实际情况,在大量的尝试下比较才能得出,以上只是前人总结的规律。
参考:https://blog.csdn.net/qq_35448985/article/details/108096021
原文:https://www.cnblogs.com/duanxz/p/14606559.html