内容简介:
利用随机森林方法训练数据集,预测泰坦尼克号哪些人可以获救,主要过程如下:
代码在jupyter notebook中 实现。
本节学习内容来自:https://space.bilibili.com/474347248/channel/detail?cid=143235,所用数据均来源于该网站。
#加载必要的库 import sys import pandas as pd import numpy as np import sklearn #机器学习库 import random import time
print(sys.version) #查看python 版本
3.8.3 (default, Jul 2 2020, 17:28:51) [MSC v.1916 32 bit (Intel)]
from sklearn import ensemble from sklearn.preprocessing import LabelEncoder from sklearn import feature_selection from sklearn import model_selection from sklearn import metrics import matplotlib as mpl import matplotlib.pyplot as plt import seaborn as sns #基于matplotlib 开发的库
#在jupyter notebook 中显示画的图 %matplotlib inline
mpl.style.use("ggplot") # 设置matplotlib 的绘图风格
data_raw = pd.read_csv("train.csv") data_val = pd.read_csv("test.csv")
#显示部分数据 data_raw.head() #默认读取前5行;可以加参数:data_raw.head(3) 读取前三行

data_val.head()

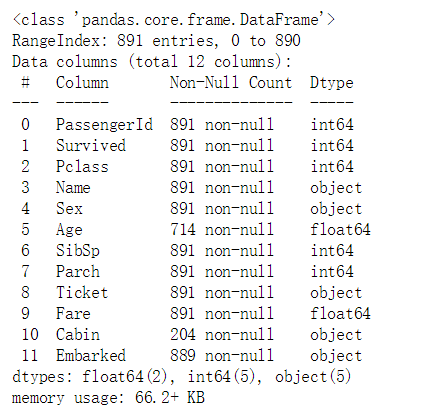
#查看表的信息 data_raw.info()
#列名称转换为小写格式 data_raw.columns = data_raw.columns.str.lower() data_val.columns = data_val.columns.str.lower()
data_raw.head()

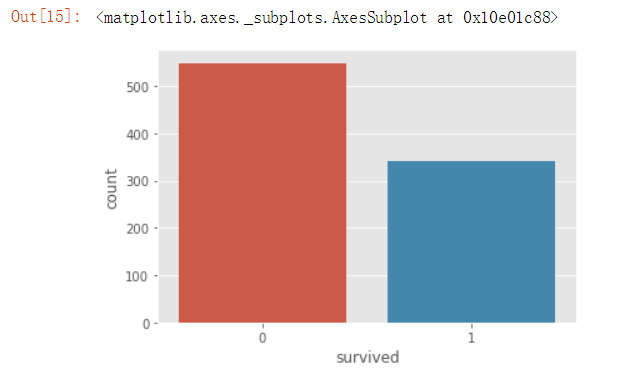
#绘制图形 sns.countplot(data_raw["survived"])
# 合并两个数据集,进行统一的清洗 data_all = [data_raw, data_val]
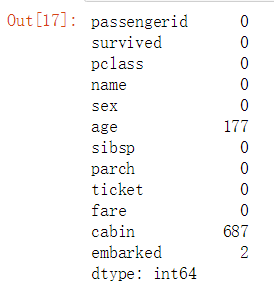
#查看一下每一列有多少空值 data_raw.isnull().sum()
data_val.isnull().sum()
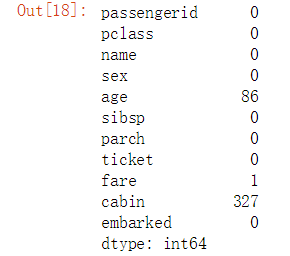
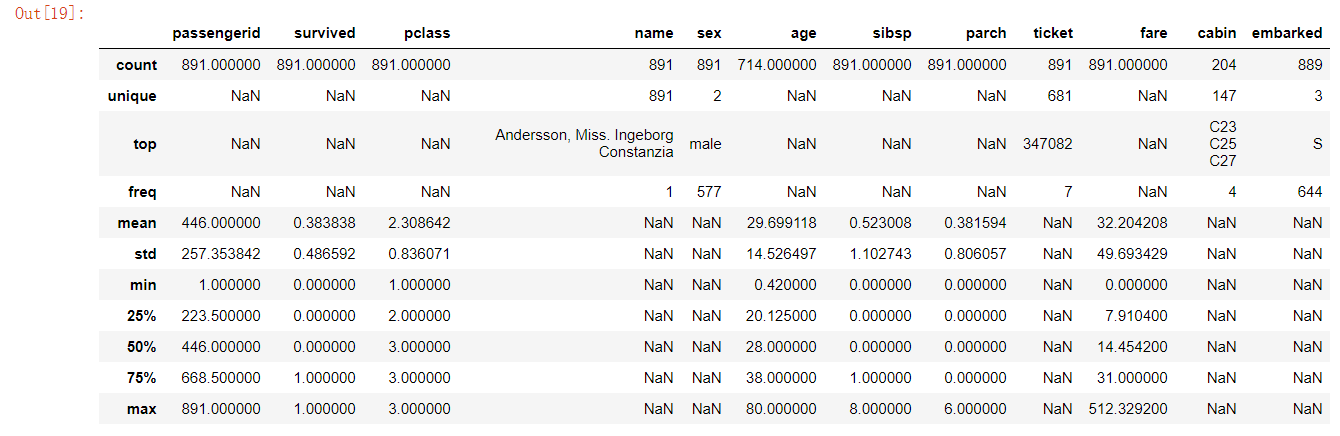
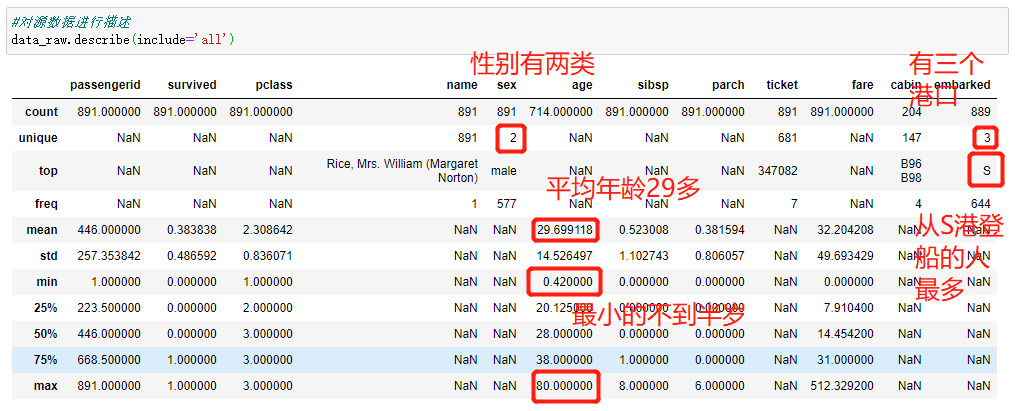
#对源数据进行描述 data_raw.describe(include=‘all‘)
# 对原始数据集(训练集和验证集)进行清理 for dataset in data_all: #补足空缺值 dataset[‘age‘].fillna(dataset[‘age‘].median(), inplace=True) #inplace=True:在原表中补齐,为False则会生成一个新表返回 dataset[‘fare‘].fillna(dataset[‘fare‘].median(), inplace=True) dataset[‘embarked‘].fillna(dataset[‘embarked‘].mode()[0], inplace=True) #mode()返回的出现次数最多的几个字符串,然后[0]代表取第一个 #dataset[‘embarked‘].fillna(dataset[‘embarked‘].median(), inplace=True) 这里要注意港口是字符串类型,没有中值,不能这样写
#删除一些字段(cabin 空缺太多,对数据分析没有太大的意义 drop_columns = ["cabin","passengerid","ticket"] data_raw.drop(drop_columns, axis = 1, inplace = True) #asxis = 1代表整列删除 inplace = True代表在原始数据上操作 data_val.drop(drop_columns, axis = 1, inplace = True)
data_raw.isnull().sum()
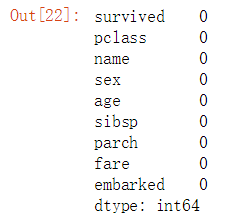
data_raw.info()
data_val.isnull().sum()
for dataset in data_all: #1)构建新的字段:family_size 家庭规模 (sibsp和parch相加) dataset["family_size" ] = dataset[‘sibsp‘] + dataset[‘parch‘] + 1 #1表示加自己 #2)构建新的字段:single 单身, 1:单身; 0:非单身 dataset[‘single‘] = 1 #初始化为1 dataset[‘single‘].loc[dataset[‘family_size‘]>1] = 0 #loc[]表格的每一行,判断家庭规模大于1的为非单身 #3)构建新的字段:身份 title ,从name字段 ;Braund, Mr. Owen Harris :以逗号,点号分割 dataset[‘title‘] = dataset[‘name‘].str.split(‘, ‘, expand = True)[1] #pandas中split默认expand = False返回的是series,expand = True返回dataframe;分割之后拿到第一个字段,也就是上一行的逗号后面的; dataset[‘title‘] = dataset[‘title‘].str.split(‘.‘, expand = True)[0] #拿到点号之前的,也就是上面两行的Mr, 这一行可以和上面一行合并为一行 #dataset[‘title‘] = dataset[‘name‘].str.split(‘, ‘, expand = True)[1].str.split(‘.‘, expand = True)[0] #上面这一行代码可以用apply代替 #dataset[‘title‘] = dataset[‘name‘].apply(lambda x : x.split(‘,‘)[1]).apply(lambda x : x.split(‘.‘)[0]) #4)构建新的字段:票价 fare_bin ,从fare字段,(因为票价大小差距太多,可以分组) dataset[‘fare_bin‘] = pd.qcut(dataset[‘fare‘], 4) #根据票价,分成四组,每一组个数相等 #cut():分组,每一组个数不一定相等,qcut():分组,每一组个数相等 #data_raw[‘age‘].tolist() #把age这一列拿出来 #5)构建新的字段:age_bin dataset[‘age_bin‘] = pd.cut(dataset[‘age‘].astype(int), 5) #根据年龄分组。分成5组(每组的元素不一致)
dataset.head()
#根据不同的title 统计人数 data_raw[‘title‘].value_counts()
#判断人数少于10人的再归为一类 title_names = (data_raw[‘title‘].value_counts()<10)
title_names
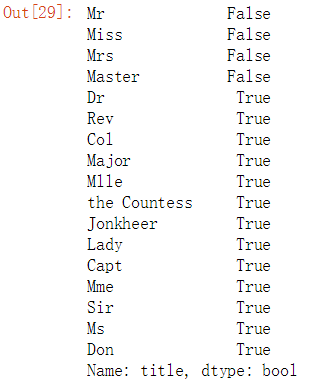
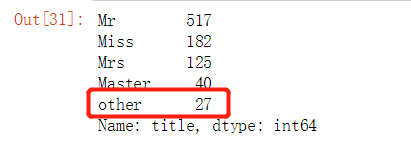
#判断人数少于10人的再归为一类:other data_raw[‘title‘] = data_raw[‘title‘].apply(lambda x : ‘other‘ if title_names[x] else x) #title_names[x]为TRUE的归为other,为FALSE的保持不动
data_raw[‘title‘].value_counts()
data_raw[‘survived‘].groupby(data_raw[‘title‘]).mean() #不同的title 被获救的概率

data_raw.head()
#像上面embarked等字段是字母,不适合数据分析
label = LabelEncoder()
for dataset in data_all: #1)新字段:sex_code dataset[‘sex_code‘] = label.fit_transform(dataset[‘sex‘]) #male female 重新编码为0 和1 #2)新字段:embarked_code dataset[‘embarked_code‘] = label.fit_transform(dataset[‘embarked‘]) #3)新字段:title_code dataset[‘title_code‘] = label.fit_transform(dataset[‘title‘]) #上面年龄和票价进行了分组,我们也要重新编码 #4)新字段:age_bin_code dataset[‘age_bin_code‘] = label.fit_transform(dataset[‘age_bin‘]) #5)新字段:fare_bin_code dataset[‘fare_bin_code‘] = label.fit_transform(dataset[‘fare_bin‘])
data_raw.head()
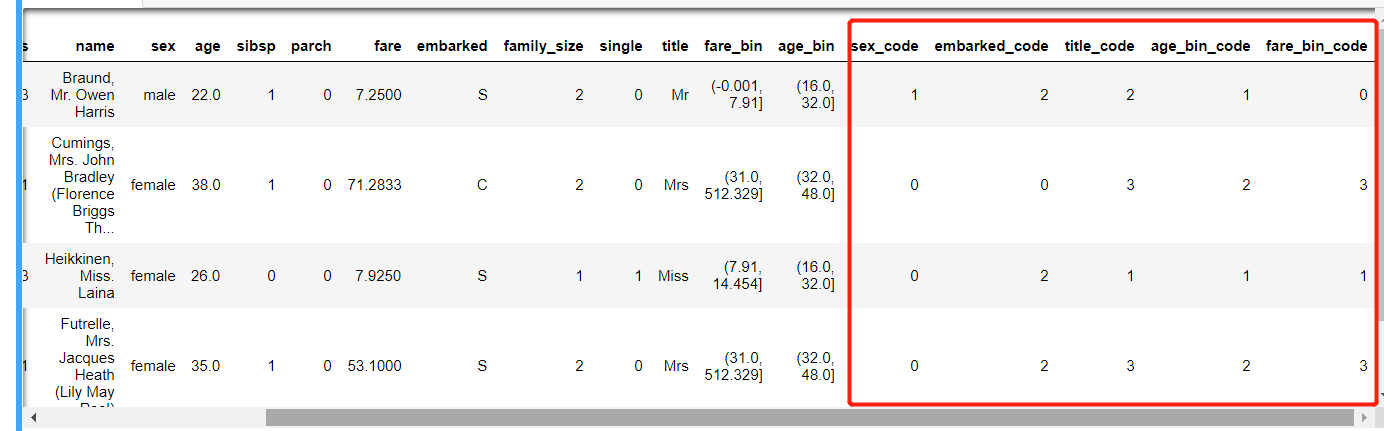
#查看所有列的字段 data_raw.columns.tolist()

###以上字段并不是都适合作为训练的字段,我们要选择合适的字段进行训练
并不是所有的字段都有训练的意义,我们通常会选择一些字段进行训练
方式1:
Target = [‘survived‘] #定义标签 data_columns_one = [‘sex‘, ‘pclass‘, ‘embarked‘, ‘title‘, ‘sibsp‘, ‘parch‘, ‘age‘, ‘fare‘, ‘family_size‘, ‘single‘] #选择要训练的字段 columns_one = Target + data_columns_one
方式2:
data_columns_two = [‘sex_code‘, ‘pclass‘, ‘embarked_code‘, ‘title_code‘, ‘sibsp‘, ‘parch‘, ‘age‘, ‘fare‘] #选择要训练的字段 columns_two = Target + data_columns_two
方式3:
data_columns_three = [‘sex_code‘, ‘pclass‘, ‘embarked_code‘, ‘title_code‘, ‘family_size‘, ‘age_bin_code‘, ‘fare_bin_code‘] #选择要训练的字段 columns_three = Target + data_columns_three
#通过pandas 中的get_dummies()进行编码(功能类似于LabelEncoder()) data_one_dummy = pd.get_dummies(data_raw[data_columns_one])
data_one_dummy_list = data_one_dummy.columns.tolist() #以列表形式查看编码后的字段 data_one_dummy_list

对应上面的三种方式
方式1:
x_train_one, x_test_one, y_train_one, y_test_one = model_selection.train_test_split(data_one_dummy[data_one_dummy_list],
data_raw[Target],
random_state = 0)
# random_state = 0保证每次运行的结果是一样的
x_train_one.shape #查看一下
x_test_one.shape
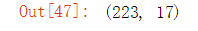
方式2:
x_train_two, x_test_two, y_train_two, y_test_two = model_selection.train_test_split(data_raw[data_columns_two],
data_raw[Target],
random_state = 0) # random_state = 0保证每次运行的结果是一样的
x_train_two.shape #查看一下

x_test_two.shape

方式3:
x_train_three, x_test_three, y_train_three, y_test_three = model_selection.train_test_split(data_raw[data_columns_three], data_raw[Target], random_state = 0) # random_state = 0保证每次运行的结果是一样的
x_train_three.shape #查看一下
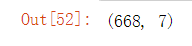
x_test_three.shape
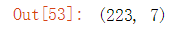
from sklearn.model_selection import GridSearchCV from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(max_features=‘auto‘, random_state=1, n_jobs=-1) #n_jobs=-1 多线程
param_gird = { ‘criterion‘ : [‘gini‘, ‘entropy‘], #两个模型 ‘min_samples_leaf‘ : [1, 5, 10], ‘min_samples_split‘ : [2, 4, 10, 12, 16], ‘n_estimators‘ : [50, 100, 400, 700, 1000] }
gs = GridSearchCV(estimator=rf, param_grid=param_gird, scoring= ‘accuracy‘, cv=3, n_jobs=-1)
gs = gs.fit(x_train_one, y_train_one) # fit 训练,可能需要一会儿
print(gs.best_score_) #准确性
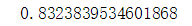
print(gs.best_params_)#查看训练选择的参数
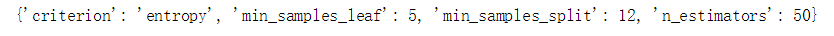
#创建一个对象,用上面的参数继续训练 rf2 = RandomForestClassifier(criterion=‘entropy‘, min_samples_leaf=5, min_samples_split=12, n_estimators=50, n_jobs=-1, random_state=1)
rf2.fit(x_train_one, y_train_one)

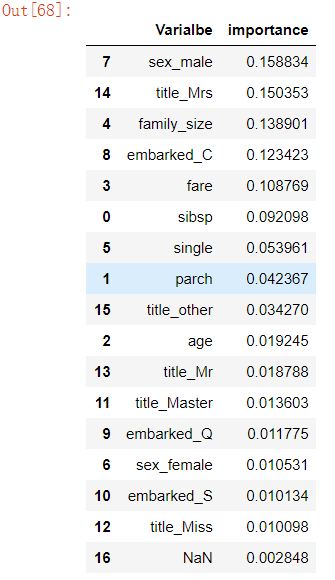
#根据特征根的重要性排序 pd.concat((pd.DataFrame(x_train_one.iloc[:, 1:].columns, columns=[‘Varialbe‘]), pd.DataFrame(rf2.feature_importances_, columns=[‘importance‘])), axis=1 ).sort_values(by=‘importance‘, ascending=False)
pred = rf2.predict(x_test_one) pred_df = pd.DataFrame(pred, columns=[‘survived‘]) pred_df.head()
原文:https://www.cnblogs.com/bltstop/p/14593157.html
