Kafka就是一个缓存,可以解耦,可以承载很多数据,性能好。
Redis也可以做缓存
Kafka 是开源消息系统,可以处理实时数据,高通量、低等待的平台。
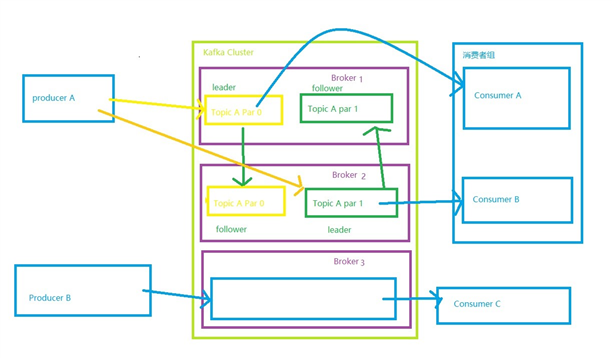
是一个分布式消息队列,根须topic来归类。发送消息的叫Producer,接收到 Consumer。
Kafka集群中有多个kafka实例组成,每个实例叫做broker
无论是kafka集群,还是producer、consumer 都依赖于 zookeeper 保存元信息,来保证系统可用性
1、Producer 消息生产者,往kafka中发消息的客户端
2、consumer 消息消费者,从kafka中取消息的客户端
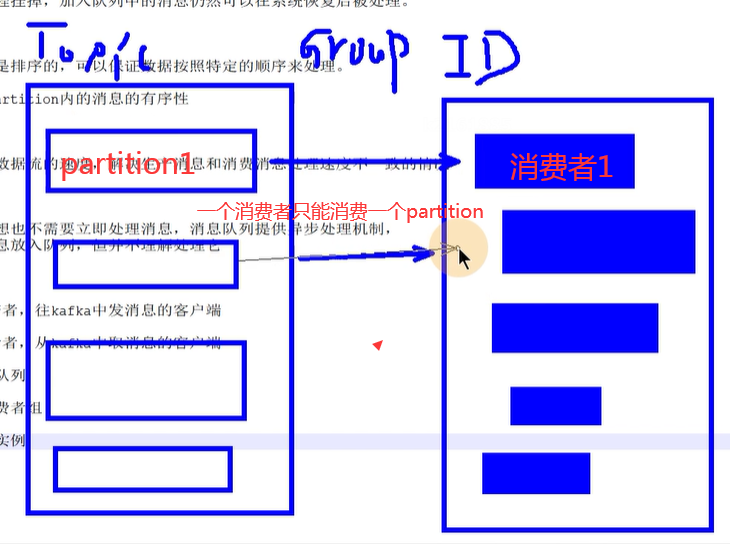
3、Topic 可以理解为队列
4、Consumer Group 消费者组
组内有多个消费者实例,他们共享一个公共的ID,即groupID
组内所以消费者协调在一起,消费topic
每个分区,只能有同一个消费者组内的一个consumer消费
5、broker
一个kafka服务器就是一个broker
6、partition :一个topic可以分为多个partition
每个partition都是一个有序队列
kafka保证按一个partition中的顺序,将消息发送给consumer
不能保证topic整体有序
7、offset:
kafka的存储文件都是按照offset.kafka来命名。
用offset做名字的好处是方便查找。
例如:找2049的位置,只要找到2048.kafka。
1、点对点模式:一对一
特点:发送到队列中的消息,只有一个接受者处理
2、发布、订阅模式:类似于公众号,一对多
数据产生后,推送给所有订阅者。
1、解耦
允许你独立扩展或者修改两边的处理过程
2、冗余
消息队列把数据进行持久化直到他们被完全处理。规避数据丢失风险。
3、扩展性
消息队列解耦了处理过程,增大入队和处理的频率很容易,只要增加处理过程即可。
4、灵活、峰值处理能力
访问量突增的情况下,应用依旧要持续发挥作用,但是这样的突发流量不常见。
如果以处理峰值来投入资源随时待命,无疑是巨大的浪费。
消息队列可以顶住突发的访问压力,而且不会造成突发请求超负荷崩溃情况。
5、可恢复性
系统的一部分组件失效时,不会影响整个系统。
即使一个消费者进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
6、顺序保证
大部分的消息队列是排序的,可以保证数据按照特定的顺序来处理。
kafka只保证一个partition内的消息的有序性
7、缓冲
有助于控制和优化数据流的速度,解决生产消息和消费消息处理速度不一致的情况
8、异步通信
很多时候,用户不想也不需要立即处理消息,消息队列提供异步处理机制,
允许用户把一个消息放入队列,但并不理解处理它
副本,主从,,往leader里面写,出也是,但是我们不用管,这是内部实现的。
查看当前kafka中所有topic
./bin/kafka-topics.sh --zookeeper node3:2181 --list
创建topic
./bin/kafka-topics.sh --zookeeper node3:2181 --create --replication-factor 2 --partitions 1 --topic topic1122
删除topic
./bin/kafka-topics.sh --zookeeper node3:2181 --delete --topic topic0908
发送消息
./bin/kafka-console-producer.sh --broker-list node3:9092 --topic topic1122
接收消息
./bin/kafka-console-consumer.sh --bootstrap-server node3:9092 --from-beginning --topic topic1122
消费者组
修改consumer.properties文件
启动消费者
./bin/kafka-console-consumer.sh --bootstrap-server node3:9092 --topic topic1122 --consumer.config config/consumer.properties
原文:https://www.cnblogs.com/ming-michelle/p/14609148.html