相比于英文分词:
常用分词规范:
现代汉语预料库加工规范:切分规范;切分和标识相结合的规范;标识规范
一般的分词准则:
根据使用资源不同可以分为:
| 非语料库 | 语料库 | |
|---|---|---|
| 词典 | 机械分词 | 混合分词 |
| 非词典 | 自分割切词 | 统计分词(基于统计或者机器学习) |
传统分词方法:基于词典的机械分词
基于统计/机器学习的分词方法:
构造词典,需要从以下三个方面考虑:
机械分词的算法:
用MAXL表示最大词长,按照从左到右的顺序,首先从汉字串中取长度为MAXL的子串查词典。若词典中存在这个词,则切分出该子串,指针后移 MAXL 个汉字后继续切分,否则,子串长度减一,再与词典匹配。若长度为2的子串还不能在词典中查到,则取当前汉字为词(单字词),指针后移一个汉字继续匹配。
他们明天来上海
他们明天 -> 他们明 -> 他们 :查询到
明天来上海 -> 明天来上 -> ....
与前者区别在于抽取顺序,从汉字串尾端开始抽取

按照从左到右的顺序,首先从汉字串中取长度为2的子串查词典。若词典中存在这个词,则切分出该子串,指针后移2个汉字,否则,子串长度逐次加一继续匹配。若一直到长度为MAXL的子串仍无法匹配,则切分出当前汉字。
与前者区别在于抽取顺序,从汉字串尾端开始抽取
正向最小匹配过程 :
他们 明天 来上 来上海 来 上海
来上海已经是当前最长的字串,无法匹配。切分最左端的汉字为单字
逆向最小匹配过程:
上海 天来 明天来 们明天来 来 明天 他们

设待切分中文字串\(C_0C_1...C_{n-1}\),根据\(C_0C_1\)得到所有以此为首的词条集合\(W\)(如果\(C_0C_1\)存在,也属于这个集合)。如果\(W\)为空,则将\(C_0\)切分出来,否则切出满足\(W\)集合中匹配文本的最长字串。
再将剩余子串作为新的待切分串进行同样的处理。
本质上是改进的正向最大匹配,以降低时间复杂度。
举例:
词典片段:为了 为此 奥运 奥运会 健儿 加油 加油站
待分串:为奥运会健儿加油啊

设待分中文字串\(C_1C_2...C_n\),建立建立一个结点数为n+1的切分有向无环图G,各结点编号依次为\(V_0,V_1...V_{n}\),通过以下两种方式建立所有可能的词边:
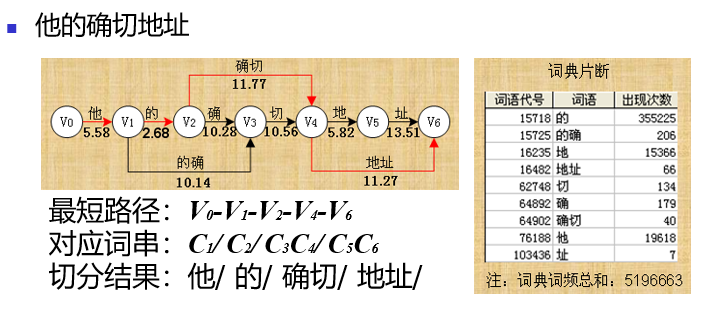
为什么机械分词几种方法间相似,却需要这么多分词方法:
为了发现歧义。多种分词结果对比,如果相同则说明没有歧义。
原文:https://www.cnblogs.com/tlam/p/14610263.html