二十一、Java输入输出流
二十二、java注解
Java 流相关的类都封装在 java.io 包中,而且每个数据流都是一个对象。所有输入流类都是 InputStream 抽象类(字节输入流)和 Reader 抽象类(字符输入流)的子类。其中 InputStream 类是字节输入流的抽象类,是所有字节输入流的父类
InputStream 类中所有方法遇到错误时都会引发 IOException 异常。如下是该类中包含的常用方法。
| 名称 | 作用 |
|---|---|
| int read() | 从输入流读入一个 8 字节的数据,将它转换成一个 0~ 255 的整数,返回一个整数,如果遇到输入流的结尾返回 -1 |
| int read(byte[] b) | 从输入流读取若干字节的数据保存到参数 b 指定的字节数组中,返回的字节数表示读取的字节数,如果遇到输入流的结尾返回 -1 |
| int read(byte[] b,int off,int len) | 从输入流读取若干字节的数据保存到参数 b 指定的字节数组中,其中 off 是指在数组中开始保存数据位置的起始下标,len 是指读取字节的位数。返回的是实际读取的字节数,如果遇到输入流的结尾则返回 -1 |
| void close() | 关闭数据流,当完成对数据流的操作之后需要关闭数据流 |
| int available() | 返回可以从数据源读取的数据流的位数。 |
| skip(long n) | 从输入流跳过参数 n 指定的字节数目 |
| boolean markSupported() | 判断输入流是否可以重复读取,如果可以就返回 true |
| void mark(int readLimit) | 如果输入流可以被重复读取,从流的当前位置开始设置标记,readLimit 指定可以设置标记的字节数 |
| void reset() | 使输入流重新定位到刚才被标记的位置,这样可以重新读取标记过的数据 |
上述最后 3 个方法一般会结合在一起使用,首先使用 markSupported() 判断,如果可以重复读取,则使用 mark(int readLimit) 方法进行标记,标记完成之后可以使用 read() 方法读取标记范围内的字节数,最后使用 reset() 方法使输入流重新定位到标记的位置,继而完成重复读取操作。
Java 中的字符是 Unicode 编码,即双字节的,而 InputerStream 是用来处理单字节的,在处理字符文本时不是很方便。这时可以使用 Java 的文本输入流 Reader 类,该类是字符输入流的抽象类,即所有字符输入流的实现都是它的子类,该类的方法与 InputerSteam 类的方法类似,这里不再介绍。
在 Java 中所有输出流类都是 OutputStream 抽象类(字节输出流)和 Writer 抽象类(字符输出流)的子类。其中 OutputStream 类是字节输出流的抽象类,是所有字节输出流的父类
OutputStream 类是所有字节输出流的超类,用于以二进制的形式将数据写入目标设备,该类是抽象类,不能被实例化。OutputStream 类提供了一系列跟数据输出有关的方法,如下所示。
| 名称 | 作用 |
|---|---|
| int write(b) | 将指定字节的数据写入到输出流 |
| int write (byte[] b) | 将指定字节数组的内容写入输出流 |
| int write (byte[] b,int off,int len) | 将指定字节数组从 off 位置开始的 len 字节的内容写入输出流 |
| close() | 关闭数据流,当完成对数据流的操作之后需要关闭数据流 |
| flush() | 刷新输出流,强行将缓冲区的内容写入输出流 |
java程序运行时都带有一个系统流,系统流对应的类为 java.lang.System。Sytem 类封装了 Java 程序运行时的 3 个系统流,分别通过 in、out 和 err 变量来引用。这 3 个系统流如下所示:
以上变量的作用域为 public 和 static,因此在程序的任何部分都不需引用 System 对象就可以使用它们。
Java 中常见编码说明如下:
在程序中如果处理不好字符编码,就有可能出现乱码问题。例如现在本机的默认编码是 GBK,但在程序中使用了 ISO8859-1 编码,则就会出现字符的乱码问题。就像两个人交谈,一个人说中文,另外一个人说英语,语言不同就无法沟通。为了避免产生乱码,程序编码应与本地的默认编码保持一致。
本地的默认编码可以使用 System 类查看。Java 中 System 类可以取得与系统有关的信息,所以直接使用此类可以找到系统的默认编码。方法如下所示:
public static Properties getProperty()
使用上述方法可以查看 JVM 的默认编码,代码如下:
public static void main(String[] args) {
// 获取当前系统编码
System.out.println("系统默认编码:" + System.getProperty("file.encoding"));
}
运行结果如下:
系统默认编码:GBK
可以看出,现在操作系统的默认编码是 GBK。
下面通过一个示例讲解乱码的产生。现在本地的默认编码是 GBK,下面通过 ISO8859-1 编码对文字进行编码转换。如果要实现编码的转换可以使用 String 类中的 getBytes(String charset) 方法,此方法可以设置指定的编码,该方法的格式如下:
public byte[] getBytes(String charset);
File 类不能访问文件内容本身,如果需要访问文件内容本身,则需要使用输入/输出流。
File 类提供了如下三种形式构造方法。
使用任意一个构造方法都可以创建一个 File 对象,然后调用其提供的方法对文件进行操作。在表 1 中列出了 File 类的常用方法及说明。
| 方法名称 | 说明 |
|---|---|
| boolean canRead() | 测试应用程序是否能从指定的文件中进行读取 |
| boolean canWrite() | 测试应用程序是否能写当前文件 |
| boolean delete() | 删除当前对象指定的文件 |
| boolean exists() | 测试当前 File 是否存在 |
| String getAbsolutePath() | 返回由该对象表示的文件的绝对路径名 |
| String getName() | 返回表示当前对象的文件名或路径名(如果是路径,则返回最后一级子路径名) |
| String getParent() | 返回当前 File 对象所对应目录(最后一级子目录)的父目录名 |
| boolean isAbsolute() | 测试当前 File 对象表示的文件是否为一个绝对路径名。该方法消除了不同平台的差异,可以直接判断 file 对象是否为绝对路径。在 UNIX/Linux/BSD 等系统上,如果路径名开头是一条斜线/,则表明该 File 对象对应一个绝对路径;在 Windows 等系统上,如果路径开头是盘符,则说明它是一个绝对路径。 |
| boolean isDirectory() | 测试当前 File 对象表示的文件是否为一个路径 |
| boolean isFile() | 测试当前 File 对象表示的文件是否为一个“普通”文件 |
| long lastModified() | 返回当前 File 对象表示的文件最后修改的时间 |
| long length() | 返回当前 File 对象表示的文件长度 |
| String[] list() | 返回当前 File 对象指定的路径文件列表 |
| String[] list(FilenameFilter) | 返回当前 File 对象指定的目录中满足指定过滤器的文件列表。假设希望只列出目录下的某些文件,这就需要调用带过滤器参数的 list() 方法。首先需要创建文件过滤器,该过滤器必须实现 java.io.FilenameFilter 接口,并在 accept() 方法中指定允许的文件类型。 |
| boolean mkdir() | 创建一个目录,它的路径名由当前 File 对象指定 |
| boolean mkdirs() | 创建一个目录,它的路径名由当前 File 对象指定 |
| boolean renameTo(File) | 将当前 File 对象指定的文件更名为给定参数 File 指定的路径名 |
File 类中有以下两个常用常量:
;。例如 java -cp test.jar;abc.jar HelloWorld。/。例如 C:/Program Files/Common Files。注意:可以看到 File 类的常量定义的命名规则不符合标准命名规则,常量名没有全部大写,这是因为 Java 的发展经过了一段相当长的时间,而命名规范也是逐步形成的,File 类出现较早,所以当时并没有对命名规范有严格的要求,这些都属于 Java 的历史遗留问题。
Windows 的路径分隔符使用反斜线“\”,而 Java 程序中的反斜线表示转义字符,所以如果需要在 Windows 的路径下包括反斜线,则应该使用两条反斜线或直接使用斜线“/”也可以。Java 程序支持将斜线当成平台无关的路径分隔符。
假设在 Windows 操作系统中有一文件 D:\javaspace\hello.java,在 Java 中使用的时候,其路径的写法应该为 D:/javaspace/hello.java 或者 D:\\javaspace\\hello.java。
Windows 中使用反斜杠\表示目录的分隔符。
Linux 中使用正斜杠/表示目录的分隔符。
注意:在操作文件时一定要使用 File.separator 表示分隔符。在程序的开发中,往往会使用 Windows 开发环境,因为在 Windows 操作系统中支持的开发工具较多,使用方便,而在程序发布时往往是直接在 Linux 或其它操作系统上部署,所以这时如果不使用 File.separator,则程序运行就有可能存在问题。关于这一点我们在以后的开发中一定要有所警惕。
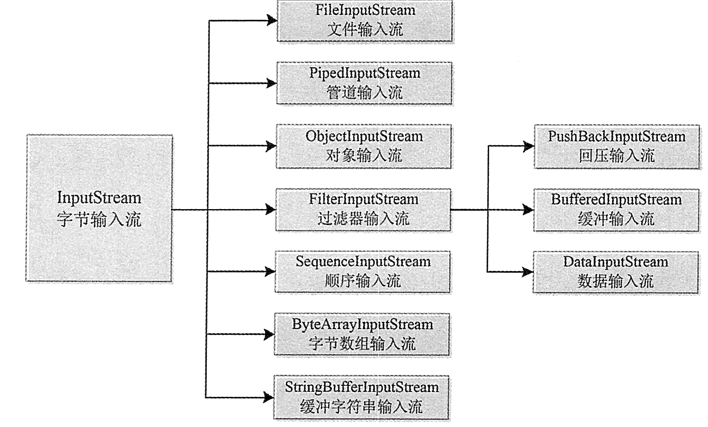
InputStream 类及其子类的对象表示字节输入流,InputStream 类的常用子类如下。
使用 InputStream 类的方法可以从流中读取一个或一批字节。表 1 列出了 InputStream 类的常用方法。
| 方法名及返回值类型 | 说明 |
|---|---|
| int read() | 从输入流中读取一个 8 位的字节,并把它转换为 0~255 的整数,最后返回整数。 如果返回 -1,则表示已经到了输入流的末尾。为了提高 I/O 操作的效率,建议尽量 使用 read() 方法的另外两种形式 |
| int read(byte[] b) | 从输入流中读取若干字节,并把它们保存到参数 b 指定的字节数组中。 该方法返回 读取的字节数。如果返回 -1,则表示已经到了输入流的末尾 |
| int read(byte[] b, int off, int len) | 从输入流中读取若干字节,并把它们保存到参数 b 指定的字节数组中。其中,off 指 定在字节数组中开始保存数据的起始下标;len 指定读取的字节数。该方法返回实际 读取的字节数。如果返回 -1,则表示已经到了输入流的末尾 |
| void close() | 关闭输入流。在读操作完成后,应该关闭输入流,系统将会释放与这个输入流相关 的资源。注意,InputStream 类本身的 close() 方法不执行任何操作,但是它的许多 子类重写了 close() 方法 |
| int available() | 返回可以从输入流中读取的字节数 |
| long skip(long n) | 从输入流中跳过参数 n 指定数目的字节。该方法返回跳过的字节数 |
| void mark(int readLimit) | 在输入流的当前位置开始设置标记,参数 readLimit 则指定了最多被设置标记的字 节数 |
| boolean markSupported() | 判断当前输入流是否允许设置标记,是则返回 true,否则返回 false |
| void reset() | 将输入流的指针返回到设置标记的起始处 |
注意:在使用 mark() 方法和 reset() 方法之前,需要判断该文件系统是否支持这两个方法,以避免对程序造成影响。
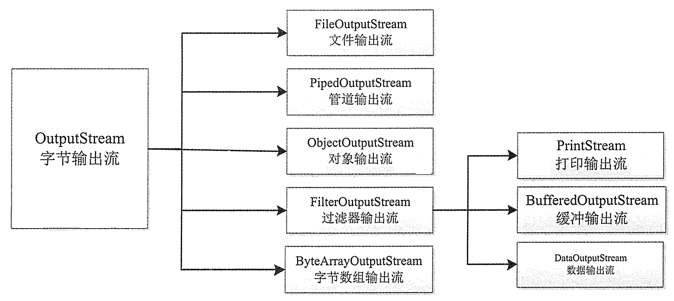
OutputStream 类及其子类的对象表示一个字节输出流。OutputStream 类的常用子类如下。
利用 OutputStream 类的方法可以从流中写入一个或一批字节。表 2 列出了 OutputStream 类的常用方法。
| 方法名及返回值类型 | 说明 |
|---|---|
| void write(int b) | 向输出流写入一个字节。这里的参数是 int 类型,但是它允许使用表达式, 而不用强制转换成 byte 类型。为了提高 I/O 操作的效率,建议尽量使用 write() 方法的另外两种形式 |
| void write(byte[] b) | 把参数 b 指定的字节数组中的所有字节写到输出流中 |
| void write(byte[] b,int off,int len) | 把参数 b 指定的字节数组中的若干字节写到输出流中。其中,off 指定字节 数组中的起始下标,len 表示元素个数 |
| void close() | 关闭输出流。写操作完成后,应该关闭输出流。系统将会释放与这个输出 流相关的资源。注意,OutputStream 类本身的 close() 方法不执行任何操 作,但是它的许多子类重写了 close() 方法 |
| void flush() | 为了提高效率,在向输出流中写入数据时,数据一般会先保存到内存缓冲 区中,只有当缓冲区中的数据达到一定程度时,缓冲区中的数据才会被写 入输出流中。使用 flush() 方法则可以强制将缓冲区中的数据写入输出流, 并清空缓冲区 |
ByteArrayInputStream 类可以从内存的字节数组中读取数据,该类有如下两种构造方法重载形式。
字节类型的数据 -1 和 -22 转换成 int 类型的数据后变成了 255 和 234,对这种结果的解释如下:
可见,从字节类型的数转换成 int 类型的数时,如果是正数,则数值不变;如果是负数,则由于转换后,二进制形式前面直接补了 24 个 0,这样就改变了原来表示负数的二进制补码形式,所以数值发生了变化,即变成了正数。
提示:负数的二进制形式以补码形式存在,例如 -1,其二进制形式是这样得来的:首先获取 1 的原码 00000001,然后进行反码操作,1 变成 0,0 变成 1,这样就得到 11111110,最后进行补码操作,就是在反码的末尾位加 1,这样就变成了 11111111。
ByteArrayOutputStream 类可以向内存的字节数组中写入数据,该类的构造方法有如下两种重载形式。
ByteArrayOutputStream 类中除了有前面介绍的字节输出流中的常用方法以外,还有如下两个方法。
FileInputStream 是 Java 流中比较常用的一种,它表示从文件系统的某个文件中获取输入字节。通过使用 FileInputStream 可以访问文件中的一个字节、一批字节或整个文件。
在创建 FileInputStream 类的对象时,如果找不到指定的文件将拋出 FileNotFoundException 异常,该异常必须捕获或声明拋出。
FileInputStream 常用的构造方法主要有如下两种重载形式。
注意:FileInputStream 类重写了父类 InputStream 中的 read() 方法、skip() 方法、available() 方法和 close() 方法,不支持 mark() 方法和 reset() 方法。
FileOutputStream 类继承自 OutputStream 类,重写和实现了父类中的所有方法。FileOutputStream 类的对象表示一个文件字节输出流,可以向流中写入一个字节或一批字节。在创建 FileOutputStream 类的对象时,如果指定的文件不存在,则创建一个新文件;如果文件已存在,则清除原文件的内容重新写入。
FileOutputStream 类的构造方法主要有如下 4 种重载形式。
注意:使用构造方法 FileOutputStream(String name,boolean append) 创建一个文件输出流对象,它将数据附加在现有文件的末尾。该字符串 name 指明了原文件,如果只是为了附加数据而不是重写任何已有的数据,布尔类型参数 append 的值应为 true。
对文件输出流有如下四点说明:
技巧:在创建 FileOutputStream 对象时,如果将 append 参数设置为 true,则可以在目标文件的内容末尾添加数据,此时目标文件仍然可以暂不存在。
Reader 类是所有字符流输入类的父类,该类定义了许多方法,这些方法对所有子类都是有效的。
Reader 类的常用子类如下。
与 InputStream 类相同,在 Reader 类中也包含 close()、mark()、skip() 和 reset() 等方法,这些方法可以参考 InputStream 类的方法。下面主要介绍 Reader 类中的 read() 方法,如表 1 所示。
| 方法名及返回值类型 | 说明 |
|---|---|
| int read() | 从输入流中读取一个字符,并把它转换为 0~65535 的整数。如果返回 -1, 则表示 已经到了输入流的末尾。为了提高 I/O 操作的效率,建议尽量使用下面两种 read() 方法 |
| int read(char[] cbuf) | 从输入流中读取若干个字符,并把它们保存到参数 cbuf 指定的字符数组中。 该方 法返回读取的字符数,如果返回 -1,则表示已经到了输入流的末尾 |
| int read(char[] cbuf,int off,int len) | 从输入流中读取若干个字符,并把它们保存到参数 cbuf 指定的字符数组中。其中, off 指定在字符数组中开始保存数据的起始下标,len 指定读取的字符数。该方法返 回实际读取的字符数,如果返回 -1,则表示已经到了输入流的末尾 |
与 Reader 类相反,Writer 类是所有字符输出流的父类,该类中有许多方法,这些方法对继承该类的所有子类都是有效的。
Writer 类的常用子类如下。
与 OutputStream 类相同,Writer 类也包含 close()、flush() 等方法,这些方法可以参考 OutputStream 类的方法。下面主要介绍 Writer 类中的 write() 方法和 append() 方法,如表 2 所示。
| 方法名及返回值类型 | 说明 |
|---|---|
| void write(int c) | 向输出流中写入一个字符 |
| void write(char[] cbuf) | 把参数 cbuf 指定的字符数组中的所有字符写到输出流中 |
| void write(char[] cbuf,int off,int len) | 把参数 cbuf 指定的字符数组中的若干字符写到输出流中。其中,off 指定 字符数组中的起始下标,len 表示元素个数 |
| void write(String str) | 向输出流中写入一个字符串 |
| void write(String str, int off,int len) | 向输出流中写入一个字符串中的部分字符。其中,off 指定字符串中的起 始偏移量,len 表示字符个数 |
| append(char c) | 将参数 c 指定的字符添加到输出流中 |
| append(charSequence esq) | 将参数 esq 指定的字符序列添加到输出流中 |
| append(charSequence esq,int start,int end) | 将参数 esq 指定的字符序列的子序列添加到输出流中。其中,start 指定 子序列的第一个字符的索引,end 指定子序列中最后一个字符后面的字符 的索引,也就是说子序列的内容包含 start 索引处的字符,但不包括 end 索引处的字符 |
注意:Writer 类所有的方法在出错的情况下都会引发 IOException 异常。关闭一个流后,再对其进行任何操作都会产生错误。
为了读取方便,Java 提供了用来读取字符文件的便捷类——FileReader。该类的构造方法有如下两种重载形式。
在用该类的构造方法创建 FileReader 读取对象时,默认的字符编码及字节缓冲区大小都是由系统设定的。要自己指定这些值,可以在 FilelnputStream 上构造一个 InputStreamReader。
注意:在创建 FileReader 对象时可能会引发一个 FileNotFoundException 异常,因此需要使用 try catch 语句捕获该异常。
字符流和字节流的操作步骤相同,都是首先创建输入流或输出流对象,即建立连接管道,建立完成后进行读或写操作,最后关闭输入/输出流通道。
Java 提供了写入字符文件的便捷类——FileWriter,该类的构造方法有如下 4 种重载形式。
在创建 FileWriter 对象时,默认字符编码和默认字节缓冲区大小都是由系统设定的。要自己指定这些值,可以在 FileOutputStream 上构造一个 OutputStreamWriter 对象。
FileWriter 类的创建不依赖于文件存在与否,如果关联文件不存在,则会自动生成一个新的文件。在创建文件之前,FileWriter 将在创建对象时打开它作为输出。如果试图打开一个只读文件,将引发一个 IOException 异常。
注意:在创建 FileWriter 对象时可能会引发 IOException 或 SecurityException 异常,因此需要使用 try catch 语句捕获该异常。
BufferedReader 类主要用于辅助其他字符输入流,它带有缓冲区,可以先将一批数据读到内存缓冲区。接下来的读操作就可以直接从缓冲区中获取数据,而不需要每次都从数据源读取数据并进行字符编码转换,这样就可以提高数据的读取效率。
BufferedReader 类的构造方法有如下两种重载形式。
除了可以为字符输入流提供缓冲区以外,BufferedReader 还提供了 readLine() 方法,该方法返回包含该行内容的字符串,但该字符串中不包含任何终止符,如果已到达流末尾,则返回 null。readLine() 方法表示每次读取一行文本内容,当遇到换行(\n)、回车(\r)或回车后直接跟着换行标记符即可认为某行已终止。
BufferedWriter 类主要用于辅助其他字符输出流,它同样带有缓冲区,可以先将一批数据写入缓冲区,当缓冲区满了以后,再将缓冲区的数据一次性写到字符输出流,其目的是为了提高数据的写效率。
BufferedWriter 类的构造方法有如下两种重载形式。
该类除了可以给字符输出流提供缓冲区之外,还提供了一个新的方法 newLine(),该方法用于写入一个行分隔符。行分隔符字符串由系统属性 line.separator 定义,并且不一定是单个新行(\n)符。
提示:BufferedWriter 类的使用与 FileWriter 类相同,这里不再重述。
元数据:注解可以元数据这个词来描述,即一种描述数据的数据。所以可以说注解就是源代码的元数据
注解常见的作用有以下几种:
无论是哪一种注解,本质上都一种数据类型,是一种接口类型。到 Java 8 为止 Java SE 提供了 11 个内置注解。其中有 5 个是基本注解,它们来自于 java.lang 包。有 6 个是元注解,它们来自于 java.lang.annotation 包,自定义注解会用到元注解。
元注解:就是负责注解其他的注解。
基本注解包括:@Override、@Deprecated、@SuppressWarnings、@SafeVarargs 和 @FunctionalInterface。
基本注解,5个:
@Override
@Deprecated
@SuppressWarnings
@SuppressWarnings 注解指示被该注解修饰的程序元素(以及该程序元素中的所有子元素)取消显示指定的编译器警告,且会一直作用于该程序元素的所有子元素。例如,使用 @SuppressWarnings 修饰某个类取消显示某个编译器警告,同时又修饰该类里的某个方法取消显示另一个编译器警告,那么该方法将会同时取消显示这两个编译器警告。
注解的使用有以下三种:
抑制警告的关键字如下表所示。
| 关键字 | 用途 |
|---|---|
| all | 抑制所有警告 |
| boxing | 抑制装箱、拆箱操作时候的警告 |
| cast | 抑制映射相关的警告 |
| dep-ann | 抑制启用注释的警告 |
| deprecation | 抑制过期方法警告 |
| fallthrough | 抑制在 switch 中缺失 breaks 的警告 |
| finally | 抑制 finally 模块没有返回的警告 |
| hiding | 抑制相对于隐藏变量的局部变量的警告 |
| incomplete-switch | 忽略不完整的 switch 语句 |
| nls | 忽略非 nls 格式的字符 |
| null | 忽略对 null 的操作 |
| rawtypes | 使用 generics 时忽略没有指定相应的类型 |
| restriction | 抑制禁止使用劝阻或禁止引用的警告 |
| serial | 忽略在 serializable 类中没有声明 serialVersionUID 变量 |
| static-access | 抑制不正确的静态访问方式警告 |
| synthetic-access | 抑制子类没有按最优方法访问内部类的警告 |
| unchecked | 抑制没有进行类型检查操作的警告 |
| unqualified-field-access | 抑制没有权限访问的域的警告 |
| unused | 抑制没被使用过的代码的警告 |
@SafeVarargs
@FunctionalInterface
元注解,6个:
@Documented:
@Documented 是一个标记注解,没有成员变量。用 @Documented 注解修饰的注解类会被 JavaDoc 工具提取成文档。默认情况下,JavaDoc 是不包括注解的,但如果声明注解时指定了 @Documented,就会被 JavaDoc 之类的工具处理,所以注解类型信息就会被包括在生成的帮助文档中。
@Target:
@Target 注解用来指定一个注解的使用范围,即被 @Target 修饰的注解可以用在什么地方。@Target 注解有一个成员变量(value)用来设置适用目标,value 是 java.lang.annotation.ElementType 枚举类型的数组,下表为 ElementType 常用的枚举常量。
| 名称 | 说明 |
|---|---|
| CONSTRUCTOR | 用于构造方法 |
| FIELD | 用于成员变量(包括枚举常量) |
| LOCAL_VARIABLE | 用于局部变量 |
| METHOD | 用于方法 |
| PACKAGE | 用于包 |
| PARAMETER | 用于类型参数(JDK 1.8新增) |
| TYPE | 用于类、接口(包括注解类型)或 enum 声明 |
@Retention:
@Retention 用于描述注解的生命周期,也就是该注解被保留的时间长短。@Retention 注解中的成员变量(value)用来设置保留策略,value 是 java.lang.annotation.RetentionPolicy 枚举类型,RetentionPolicy 有 3 个枚举常量,如下所示。
生命周期大小排序为 SOURCE < CLASS < RUNTIME,前者能使用的地方后者一定也能使用。如果需要在运行时去动态获取注解信息,那只能用 RUNTIME 注解;如果要在编译时进行一些预处理操作,比如生成一些辅助代码(如 ButterKnife),就用 CLASS 注解;如果只是做一些检查性的操作,比如 @Override 和 @SuppressWarnings,则可选用 SOURCE 注解。
@Inherited:
@Inherited 是一个标记注解,用来指定该注解可以被继承。使用 @Inherited 注解的 Class 类,表示这个注解可以被用于该 Class 类的子类。就是说如果某个类使用了被 @Inherited 修饰的注解,则其子类将自动具有该注解。
@Repeatable:
@Repeatable 注解是 Java 8 新增加的,它允许在相同的程序元素中重复注解,在需要对同一种注解多次使用时,往往需要借助 @Repeatable 注解。Java 8 版本以前,同一个程序元素前最多只能有一个相同类型的注解,如果需要在同一个元素前使用多个相同类型的注解,则必须使用注解“容器”。
@Native:
使用 @Native 注解修饰成员变量,则表示这个变量可以被本地代码引用,常常被代码生成工具使用。对于 @Native 注解不常使用,了解即可。
自定义注解:
声明自定义注解使用 @interface 关键字(interface 关键字前加 @ 符号)实现。定义注解与定义接口非常像,如下代码可定义一个简单形式的注解类型。
// 定义一个简单的注解类型
public @interface Test {
}
上述代码声明了一个 Test 注解。默认情况下,注解可以在程序的任何地方使用,通常用于修饰类、接口、方法和变量等。
定义注解和定义类相似,注解前面的访问修饰符和类一样有两种,分别是公有访问权限(public)和默认访问权限(默认不写)。一个源程序文件中可以声明多个注解,但只能有一个是公有访问权限的注解。且源程序文件命名和公有访问权限的注解名一致。
不包含任何成员变量的注解称为标记注解,例如上面声明的 Test 注解以及基本注解中的 @Override 注解都属于标记注解。根据需要,注解中可以定义成员变量,成员变量以无形参的方法形式来声明,其方法名和返回值定义了该成员变量的名字和类型。代码如下所示:
public @interface MyTag {
// 定义带两个成员变量的注解
// 注解中的成员变量以方法的形式来定义
String name();
int age();
}
以上代码中声明了一个 MyTag 注解,定义了两个成员变量,分别是 name 和 age。成员变量也可以有访问权限修饰符,但是只能有公有权限和默认权限。
如果在注解里定义了成员变量,那么使用该注解时就应该为它的成员变量指定值,如下代码所示。
public class Test {
// 使用带成员变量的注解时,需要为成员变量赋值
@MyTag(name="xx", age=6)
public void info() {
...
}
...
}
注解中的成员变量也可以有默认值,可使用 default 关键字。如下代码定义了 @MyTag 注解,该注解里包含了 name 和 age 两个成员变量。
public @interface MyTag {
// 定义了两个成员变量的注解
// 使用default为两个成员变量指定初始值
String name() default "C语言中文网";
int age() default 7;
}
如果为注解的成员变量指定了默认值,那么使用该注解时就可以不为这些成员变量赋值,而是直接使用默认值。
public class Test {
// 使用带成员变量的注解
// MyTag注释的成员变量有默认值,所以可以不为它的成员变量赋值
@MyTag
public void info() {
...
}
...
}
当然也可以在使用 MyTag 注解时为成员变量指定值,如果为 MyTag 的成员变量指定了值,则默认值不会起作用。
根据注解是否包含成员变量,可以分为如下两类。
通过反射获取注解信息:
自定义几个注解用于测试
@MyAnnotation01
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface MyAnnotation01 {
String[] value();
}
@Range
@Target(value = ElementType.FIELD)
@Retention(value = RetentionPolicy.RUNTIME)
public @interface Range {
int max();
int min();
}
@Table
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface Table {
String value();
}
定义一个实体类Studnet
package com.lee.myAnnotation;
@Table("student_info")
@MyAnnotation01(value = "Student")
public class Student {
public Student() {
}
public Student(int id, String name, int age) {
super();
this.id = id;
this.name = name;
this.age = age;
}
private int id;
private String name;
@Range(max = 100, min = 0)
private int age;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
测试类
package com.lee.myAnnotation;
import java.lang.annotation.Annotation;
import java.lang.reflect.Field;
/**
*
* @author Lee
*/
public class Test {
public static void main(String[] args) {
try {
Class c = Class.forName("com.lee.myAnnotation.Student");//获得类对象引用
//获取类的注解
Annotation[] annotations01 = c.getAnnotations();
for (Annotation annotation : annotations01) {
System.out.println(annotation);
}
//获取属性的注解
Field f1 = c.getDeclaredField("age");
Annotation[] annotations02 = f1.getAnnotations();
for (Annotation annotation : annotations02) {
System.out.println(annotation);
}
//获取指定的注解
Table table = (Table) c.getAnnotation(Table.class);
System.out.println(table);
//获取注解里的信息
Field f2 = c.getDeclaredField("age");
Range r = f2.getAnnotation(Range.class);
System.out.println("最大值:"+r.max() +"\n最小值:"+r.min());
} catch (Exception e) {
e.printStackTrace();
}
}
}

原文:https://www.cnblogs.com/namusangga/p/14613681.html