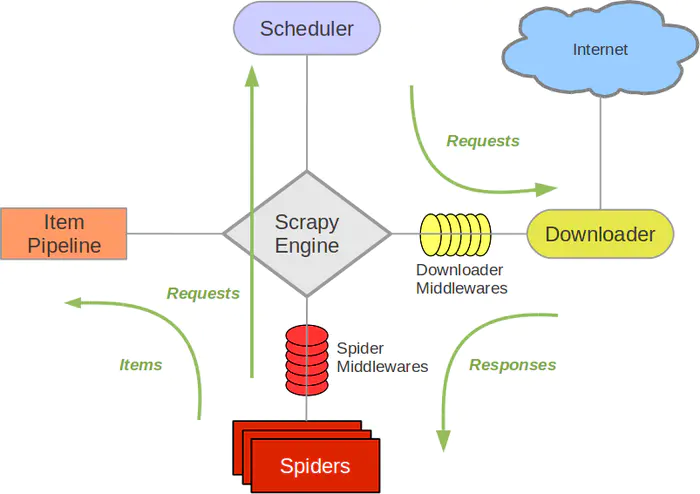
写一个爬虫,需要做很多的事情。比如:发送网络请求、数据解析、数据存储、反反爬虫机制(更换ip代理、设置请求头等)、异步请求等。这些工作如果每次都要自己从零开始写的话,比较浪费时间。因此Scrapy把一些基础的东西封装好了,在他上面写爬虫可以变的更加的高效(爬取效率和开发效率)。因此真正在公司里,一些上了量的爬虫,都是使用Scrapy框架来解决。
在命令行中,进入到项目所在的路径。然后:
scrapy shell 链接
在这个里面,可以先去写提取的规则,没有问题后,就可以把代码拷贝到项目中。方便写代码。
scrapy shell https://www.zhipin.com/nanjing/?sid=sem_pz_bdpc_dasou_title
加入请求头:
scrapy shell -s USER_AGENT=‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.2261 SLBChan/25‘ https://www.zhipin.com/nanjing/?sid=sem_pz_bdpc_dasou_title
用extract方法提取节点内容:
response.xpath(‘//ul[@class=class="cur"]/li/div/a/div/p/text()‘).extract()
scrapy startproject [项目名称].cd到项目中->scrapy genspider [爬虫名称] [域名].settings.py:用来配置爬虫的。middlewares.py:用来定义中间件。items.py:用来提前定义好需要下载的数据字段。pipelines.py:用来保存数据。scrapy.cfg:用来配置项目的。定义Item类。
import scrapy
class DangdangSpiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
author = scrapy.Field()
introduction = scrapy.Field()
编写spider类。
import scrapy
from DangdangSpider.items import DangdangSpiderItem
class DangdangSpider(scrapy.Spider):
name = ‘dangdang‘
allowed_domains = [‘dangdang.com‘]
start_urls = [‘http://book.dangdang.com/‘]
#该方法负责提取response包含的信息
#response代表下载器从start_urls中每个下载得到的响应
def parse(self, response):
for book in response.xpath(‘//ul[@class="list_aa"]/li‘):
item = DangdangSpiderItem()
for bookbook in book.xpath(‘./ul/li‘):
item[‘name‘] = bookbook.xpath(‘./p[1]/a/text()‘).extract()
item[‘author‘] = bookbook.xpath(‘./p[2]/text()‘).extract()
p = bookbook.xpath(‘./p[3]/span[1]//span//text()‘).extract()
item[‘price‘] = ‘‘.join(p)
yield item
编写pipelines.py文件。
这里可以保存到json文件中,也可以保存在数据库中。
import json
class DangdangspiderPipeline:
def __init__(self):
self.json_file = open("dangdang.json","wb+")
self.json_file.write(‘[\n‘.encode("utf-8"))
def close_spider(self,spider):
print(‘---------关闭文件-----‘)
# 后退两个字符,去掉最后一条记录之后的换行符和逗号
self.json_file.seek(-2,1)
self.json_file.write(‘\n]‘.encode("utf-8"))
self.json_file.close()
def process_item(self, item, spider):
text = json.dumps(dict(item),ensure_ascii=False) + ",\n"
self.json_file.write(text.encode("utf-8"))
# 导入访问MySQL的模块
import pymysql
class DangdangspiderPipeline(object):
def __init__(self):
# 连接MySQL数据库
self.connect = pymysql.connect(host=‘localhost‘, user=‘root‘, password=‘1234‘, db=‘python‘, port=3306)
self.cursor = self.connect.cursor()
def process_item(self, item, spider):
# 往数据库里面写入数据
self.cursor.execute(
‘insert into dangdangbook(name,author,price) VALUES ("{}","{}","{}")‘.format(item[‘name‘], item[‘author‘], item[‘price‘]))
self.connect.commit()
return item
# 关闭数据库
def close_spider(self, spider):
self.cursor.close()
self.connect.close()
修改settings文件。
增加请求头;修改Robots协议;配置使用pipeline。
使用shell调试工具分析目标站点:
scrapy shell https://usplash.com/
找出动态请求的网址:
scrapy shell https://unsplash.com/napi/photos?page=1&per_page=10&order_by=latest
服务器返回了一段json数据:
import json
>>>len(json.loads(response.text))
10 # 包含10个元素
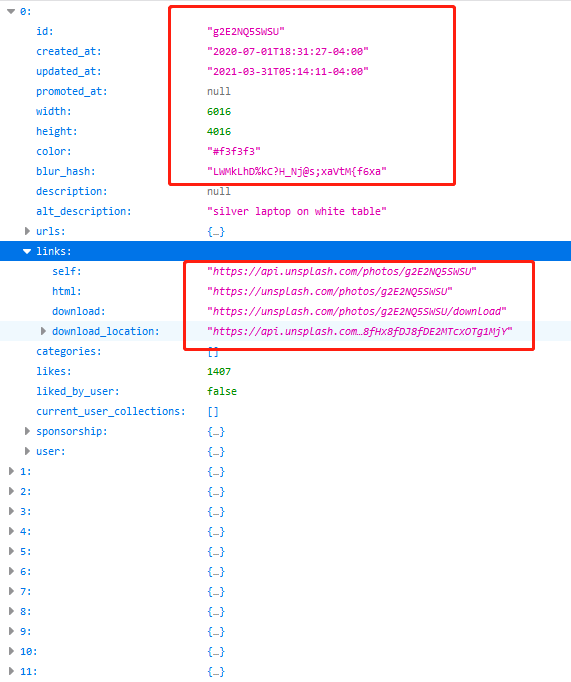
可以看出每张图片包含id、创建时间、更新时间、宽度、高度、links属性,该属性值是一个对象,转换之后对应于python的dict,包含了self、html、download、download_location属性,self代表浏览网页图片的url;download是要下载的高清图片的url。
尝试用shell查看第一张图片的下载URL:
>>> json.loads(response.text)[0][‘links‘][‘download‘]
‘https://unsplash.com/photos/g2E2NQ5SWSU/download‘
由此得出结论:该网页加载时会自动向 https://unsplash.com/napi/photos?page=N&per_page=N&order_by=latest发送请求,然后根据服务器响应的json数据动态加载图片。
该网页是瀑布流设计,在滚动时可以在调试控制台看到再次发送了请求,只是page参数发生了改变,由此只要改变参数即可。
scrapy爬取高清图片
创建项目:scrapy startproject UnsplashImageSpider;scrapy genspider unsplash_image ‘unsplash.com‘
定义item类:
import scrapy
class ImageItem(scrapy.Item):
# 保存图片id
image_id = scrapy.Field()
# 保存图片下载地址
download = scrapy.Field()
开发spider:
import scrapy, json
from UnsplashImageSpider.items import ImageItem
class UnsplashImageSpider(scrapy.Spider):
# 定义Spider的名称
name = ‘unsplash_image‘
allowed_domains = [‘unsplash.com‘]
# 定义起始页面
start_urls = [‘https://unsplash.com/napi/photos?page=1&per_page=12&order_by=latest‘]
def __init__ (self):
self.page_index = 1
def parse(self, response):
# 解析服务器响应的JSON字符串
photo_list = json.loads(response.text) # ①
# 遍历每张图片
for photo in photo_list:
item = ImageItem()
item[‘image_id‘] = photo[‘id‘]
item[‘download‘] = photo[‘links‘][‘download‘]
yield item
self.page_index += 1
# 获取下一页的链接
next_link = ‘https://unsplash.com/napi/photos?page=‘ + str(self.page_index) + ‘&per_page=12&order_by=latest‘
# 继续获取下一页的图片
yield scrapy.Request(next_link, callback=self.parse)
开发pipeline:
爬取到图片url后可以导入专门的下载工具,也可以直接下载,下面用urllib.request包直接下载:
from urllib.request import *
class UnsplashimagespiderPipeline(object):
def process_item(self, item, spider):
# 每个item代表一个要下载的图片
print(‘----------‘ + item[‘image_id‘])
real_url = item[‘download‘]
try:
pass
# 打开URL对应的资源
with urlopen(real_url) as result:
# 读取图片数据
data = result.read()
# 打开图片文件
with open("images/" + item[‘image_id‘] + ‘.jpg‘, ‘wb+‘) as f:
# 写入读取的数据
f.write(data)
except:
print(‘下载图片出现错误‘ % item[‘image_id‘])
设置settings。
IP地址验证
有些网站会使用IP地址验证进行反爬虫处理,程序会检查客户端的IP地址,如果发现同一个IP地址的客户端频繁地请求数据,该网站就会认定是爬虫。
所以要让scrapy不断更换代理服务器的IP地址,可以定义一个下载中间件。
打开中间件文件,增加以下类:
class RandomProxyMiddleware(object):
# 动态设置代理服务器的IP地址
def process_request(self,request,spider):
# get_random_proxy()函数随机返回代理服务器的IP地址和端口
request.meta["proxy"] = get_random_proxy()
应该事先准备好一些代理服务器。
配置下载中间件:
DOWNLOADER_MIDDLEWARES = {
‘ZhipinSpider.middlewares.RandomProxyMiddleware‘:543
}
ROBOTSTXT_OBEY = False
限制访问频率
在settings中取消以下注释:
# 开启访问频率限制
#AUTOTHROTTLE_ENABLED = True
# 设置访问开始的延迟
#AUTOTHROTTLE_START_DELAY = 5
# 设置访问之间的最大延迟
#AUTOTHROTTLE_MAX_DELAY = 60
# 设置scrapy并行发给每台远程服务器的请求数量
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# 设置下载之后的自动延迟
#DOWNLOAD_DELAY=3
图片验证码
登录网站有两种方法:
import scrapy
from selenium import webdriver
import time
class WbSpiderSpider(scrapy.Spider):
name = ‘wb_spider‘
allowed_domains = [‘weibo.com‘]
start_urls = [‘http://weibo.com/‘]
def __init__(self):
# 定义保存登录成功之后的cookie的变量
self.login_cookies = []
# 定义发送请求的请求头
headers = {
"Referer": "https://weibo.com/login/",
‘User-Agent‘: "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0"
}
def get_cookies(self):
‘‘‘使用Selenium模拟浏览器登录并获取cookies‘‘‘
cookies = []
browser = webdriver.Chrome()
# 等待3秒,用于等待浏览器启动完成,否则可能报错
time.sleep(2)
browser.get("https://weibo.com/login/") #①
# 获取输入用户名的文本框
elem_user = browser.find_element_by_xpath(‘//input[@id="loginname"]‘)
# 模拟输入用户名
elem_user.send_keys(‘17367077624‘) #②
# 获取输入密码的文本框
elem_pwd = browser.find_element_by_xpath(‘//input[@type="password"]‘)
# 模拟输入密码
elem_pwd.send_keys(‘zzdzzd993‘) #③
# 获取提交按钮
commit = browser.find_element_by_xpath(‘//a[@node-type="submitBtn"]‘)
# 模拟单击提交按钮
commit.click() #④
# 暂停10秒,等待浏览器登录完成
time.sleep(20)
#登录成功后获取cookie
if "微博-随时随地发现新鲜事" in browser.title:
self.login_cookies = browser.get_cookies()
else:
print("登录失败!")
# start_requests方法会在parse方法之前执行,该方法可用于处理登录逻辑。
def start_requests(self):
self.get_cookies()
print(‘=====================‘, self.login_cookies)
# 开始访问登录后的内容
return [scrapy.Request(‘https://weibo.com/lgjava/home‘,
headers=self.headers,
cookies=self.login_cookies,
callback=self.parse)]
# 解析服务器相应的内容
def parse(self, response):
print(‘~~~~~~~parse~~~~~‘)
print("是否解析成功:", ‘疯狂软件李刚‘ in response.text)
# 猎云网爬虫
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ..items import LywItem
class LywSpiderSpider(CrawlSpider):
name = ‘lyw_spider‘
allowed_domains = [‘lieyunwang.com‘]
start_urls = [‘https://www.lieyunwang.com/latest/p1.html‘]
rules = (
Rule(LinkExtractor(allow=r‘/latest/p\d+\.html‘), follow=True),
Rule(LinkExtractor(allow=r‘/archives/\d+‘),callback="parse_detail", follow=False),
)
def parse_detail(self, response):
title_list = response.xpath("//h1[@class=‘lyw-article-title‘]/text()").getall()
title = "".join(title_list).strip()
pub_time = response.xpath("//h1[@class=‘lyw-article-title‘]/span/text()").get()
author = response.xpath("//a[contains(@class,‘author-name‘)]/text()").get()
content = response.xpath("//div[@class=‘main-text‘]").get()
origin = response.url
item = LywItem(title=title,pub_time=pub_time,author=author,content=content,origin=origin)
return item
def __init__(self,mysql_config):
self.dbpool = adbapi.ConnectionPool(
mysql_config[‘DRIVER‘],
host=mysql_config[‘HOST‘],
port=mysql_config[‘PORT‘],
user=mysql_config[‘USER‘],
password=mysql_config[‘PASSWORD‘],
db=mysql_config[‘DATABASE‘],
charset=‘utf8‘
)
@classmethod
def from_crawler(cls,crawler):
# 只要重写了from_crawler方法,那么以后创建对象的时候,就会调用这个方法来获取pipline对象
mysql_config = crawler.settings[‘MYSQL_CONFIG‘]
return cls(mysql_config)
runInteraction来运行真正执行sql语句的函数。示例代码如下:def process_item(self, item, spider):
# runInteraction中除了传运行sql的函数,还可以传递参数给回调函数使用
result = self.dbpool.runInteraction(self.insert_item,item)
# 如果出现了错误,会执行self.insert_error函数
result.addErrback(self.insert_error)
return item
def insert_item(self,cursor,item):
sql = "insert into article(id,title,author,pub_time,content,origin) values(null,%s,%s,%s,%s,%s)"
args = (item[‘title‘],item[‘author‘],item[‘pub_time‘],item[‘content‘],item[‘origin‘])
cursor.execute(sql,args)
def insert_error(self,failure):
print("="*30)
print(failure)
print("="*30)
解析图片的链接。
定义一个item,上面有两个字段,一个是image_urls,一个是images。其中image_urls是用来存储图片的链接,由开发者把数据爬取下来后添加的。
使用scrapy.pipelines.images.ImagesPipeline来作为数据保存的pipeline。
在settings.py中设置IMAGES_SOTRE来定义图片下载的路径。
如果想要有更复杂的图片保存的路径需求,可以重写ImagePipeline的file_path方法,这个方法用来返回每个图片的保存路径。
而file_path方法没有item对象,所以我们还需要重写get_media_requests方法,来把item绑定到request上。示例代码如下:
在创建文件夹的时候,要注意一些特殊字符是不允许作为文件夹的名字而存在的,那么我们就可以通过正则表达式来删掉。r‘[\\/:\*\?"<>\|]‘。
import scrapy
from scrapy.spiders.crawl import CrawlSpider,Rule
from scrapy.linkextractors import LinkExtractor
from ..items import ImagedownloadItem
class ZcoolSpider(CrawlSpider):
name = ‘zcool‘
allowed_domains = [‘zcool.com.cn‘]
# start_urls = [‘http://zcool.com.cn/‘]
start_urls = [‘https://www.zcool.com.cn/home?p=1#tab_anchor‘]
rules = (
# 翻页的url
Rule(LinkExtractor(allow=r"https://www.zcool.com.cn/home?p=\d+#tab_anchor"),follow=True),
# 详情页面的url
Rule(LinkExtractor(allow=r".+/work/.+html"),follow=False,callback="parse_detail")
)
def parse_detail(self, response):
image_urls = response.xpath("//div[@class=‘photo-information-content‘]//img/@src").getall()
title_list = response.xpath("//div[@class=‘details-contitle-box‘]/h2/text()").getall()
title = "".join(title_list).strip()
item = ImagedownloadItem(title=title,image_urls=image_urls)
yield item
import scrapy
class ImagedownloadItem(scrapy.Item):
title = scrapy.Field()
# image_urls:是用来保存这个item上的图片的链接的
image_urls = scrapy.Field()
# images:是后期图片下载完成后形成image对象再保存到这个上面
images = scrapy.Field()
from scrapy.pipelines.images import ImagesPipeline
from imagedownload import settings
import os
import re
class ImagedownloadPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
media_requests = super(ImagedownloadPipeline, self).get_media_requests(item,info)
for media_request in media_requests:
media_request.item = item
return media_requests
def file_path(self, request, response=None, info=None):
origin_path = super(ImagedownloadPipeline, self).file_path(request,response,info)
title = request.item[‘title‘]
title = re.sub(r‘[\\/:\*\?"<>\|]‘,"",title)
save_path = os.path.join(settings.IMAGES_STORE,title)
if not os.path.exists(save_path):
os.mkdir(save_path)
image_name = origin_path.replace("full/","")
return os.path.join(save_path,image_name)
# settings里添加:
IMAGES_STORE = os.path.join(os.path.dirname(os.path.dirname(__file__)),‘images‘)
ITEM_PIPELINES = {
‘imagedownload.pipelines.ImagedownloadPipeline‘: 300,
# ‘scrapy.pipelines.images.ImagesPipeline‘: 1
}
下载器中间件是引擎和下载器之间通信的中间件。在这个中间件中我们可以设置代理、更换请求头等来达到反反爬虫的目的。要写下载器中间件,可以在下载器中实现两个方法。一个是process_request(self,request,spider),这个方法是在请求发送之前会执行,还有一个是process_response(self,request,response,spider),这个方法是数据下载到引擎之前执行。
process_request(self,request,spider)方法:
这个方法是下载器在发送请求之前会执行的。一般可以在这个里面设置随机代理ip等。
process_response(self,request,response,spider)方法:
这个是下载器下载的数据到引擎中间会执行的方法。
设置普通代理:
class IPProxyDownloadMiddleware(object):
PROXIES = [
"5.196.189.50:8080",
]
def process_request(self,request,spider):
proxy = random.choice(self.PROXIES)
print(‘被选中的代理:%s‘ % proxy)
request.meta[‘proxy‘] = "http://" + proxy
设置独享代理:
class IPProxyDownloadMiddleware(object):
def process_request(self,request,spider):
proxy = ‘121.199.6.124:16816‘
user_password = "970138074:rcdj35xx"
request.meta[‘proxy‘] = proxy
# bytes
b64_user_password = base64.b64encode(user_password.encode(‘utf-8‘))
request.headers[‘Proxy-Authorization‘] = ‘Basic ‘ + b64_user_password.decode(‘utf-8‘)
代理服务商:
bind 192.168.175.129 127.0.0.1
useradd命令来创建一个普通用户。后期方便通过xshell来连接。ubuntu不允许外面直接用root用户链接,那么我们可以先用普通用户连接,然后再切换到root用户。pip3 install scrapyd。/usr/local/lib/python3.5/dist-packages/scrapyd下拷贝出default_scrapyd.conf放到/etc/scrapyd/scrapyd.conf。/etc/scrapyd/scrapyd.conf中的bind_address为自己的IP地址。twisted:pip uninstall twisted
pip install twisted==18.9.0
pip install scrapyd-client。python/Script/scrapyd-deploy为scrapyd-deploy.pyscrapy.cfg,然后配置如下:[settings]
default = lianjia.settings
[deploy]
# 下面这个url要取消注释
url = http://服务器的IP地址:6800/
project = lianjia
scrapyd-deploy。如果一次性想要把代码上传到多个服务器,那么可以修改scrapy.cfg为如下:[settings]
default = lianjia.settings
[deploy:服务器1]
# 下面这个url要取消注释
url = http://服务器1的IP地址:6800/
project = lianjia
[deploy:服务器2]
# 下面这个url要取消注释
url = http://服务器2的IP地址:6800/
project = lianjia
scrapyd-deploy -a就可以全部上传了。https://curl.haxx.se/windows/,解压后双击打开bin/curl.exe即可在cmd中使用了。curl http://服务器IP地址:6800/schedule.json -d project=lianjia -d spider=house
原文:https://www.cnblogs.com/zzdshidashuaige/p/14614354.html