一、词频统计:
1.读文本文件生成RDD lines
lines=sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")
lines.foreach(print)

2.将一行一行的文本分割成单词 words flatmap()
words=lines.flatMap(lambda line:line.split())
words.foreach(print)
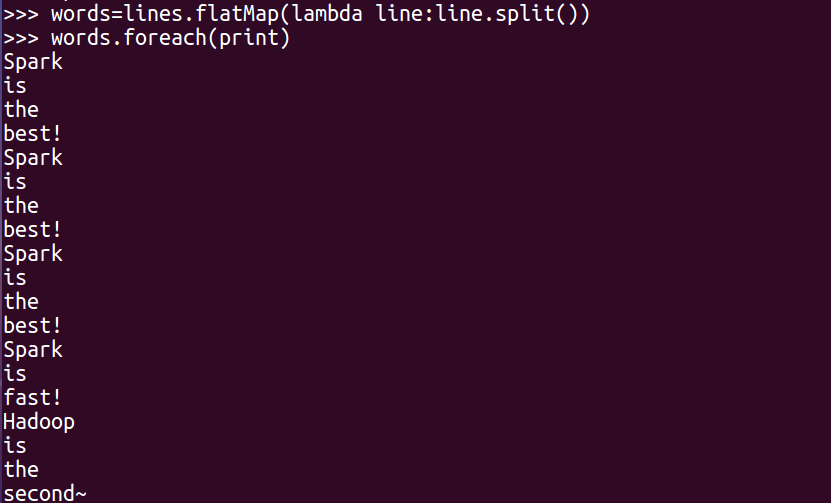
3.全部转换为小写 lower()
words1=lines.map(lambda word:word.lower())
words1.foreach(print)
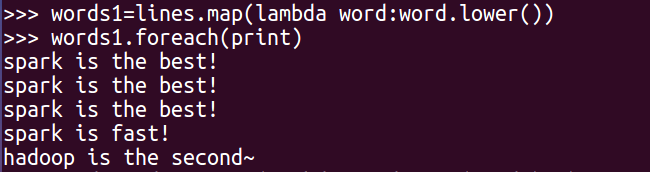
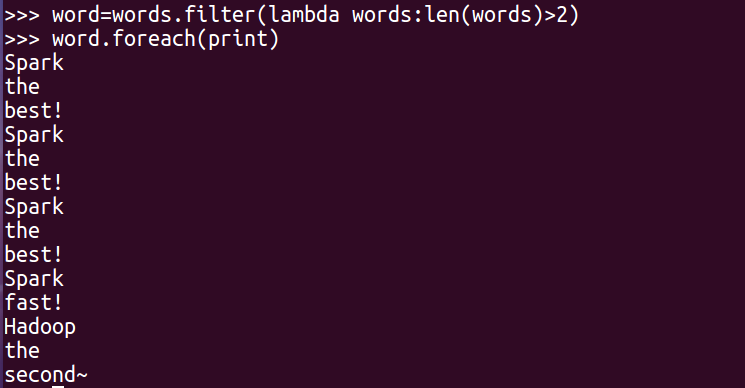
4.去掉长度小于3的单词 filter()
word=words.filter(lambda words:len(words)>2)
words.foreach(print)
5.去掉停用词
with open("/usr/local/spark/mycode/rdd/stopwords.txt") as f:
stops=f.read().split()
lines.flatMap(lambda line:line.split()).filter(lambda word:word not in stops).collect()

6.转换成键值对 map()
words.map(lambda word:(word,1)).collect()

7.统计词频 reduceByKey()
words.map(lambda word:(word,1)).reduceByKey(lambda a,b:a+b).collect()

二、学生课程分数 groupByKey()
-- 按课程汇总全总学生和分数
1. 分解出字段 map()
2. 生成键值对 map()
3. 按键分组
4. 输出汇总结果
lines=sc.textFile("file:///usr/local/spark/mycode/rdd/chapter4-data01.txt")
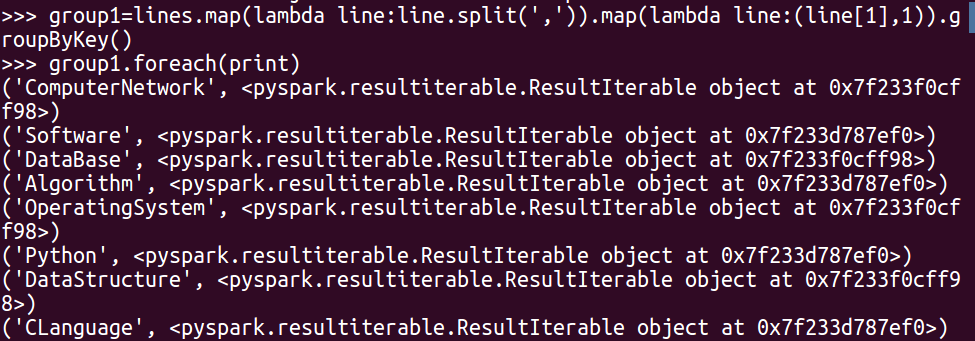
group1=lines.map(lambda line:line.split(‘,‘)).map(lambda line:(line[1],1)).groupByKey()
group1.foreach(print)

三、学生课程分数 reduceByKey()
-- 每门课程的选修人数
lines=sc.textFile("file:///usr/local/spark/mycode/rdd/chapter4-data01.txt")
groupNum=lines.map(lambda line:line.split(‘,‘)).map(lambda line:(line[1],1)).reduceByKey(lambda a,b:a+b)
groupNum.foreach(print)
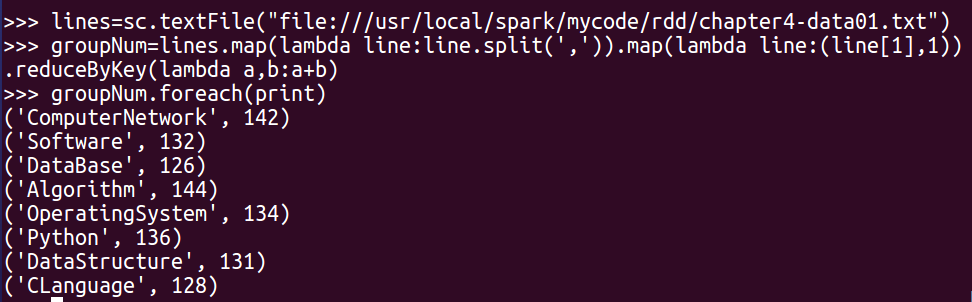
-- 每个学生的选修课程数
groupNum1=lines.map(lambda line:line.split(‘,‘)).map(lambda line:(line[0],1)).reduceByKey(lambda a,b:a+b)
groupNum1.foreach(print)
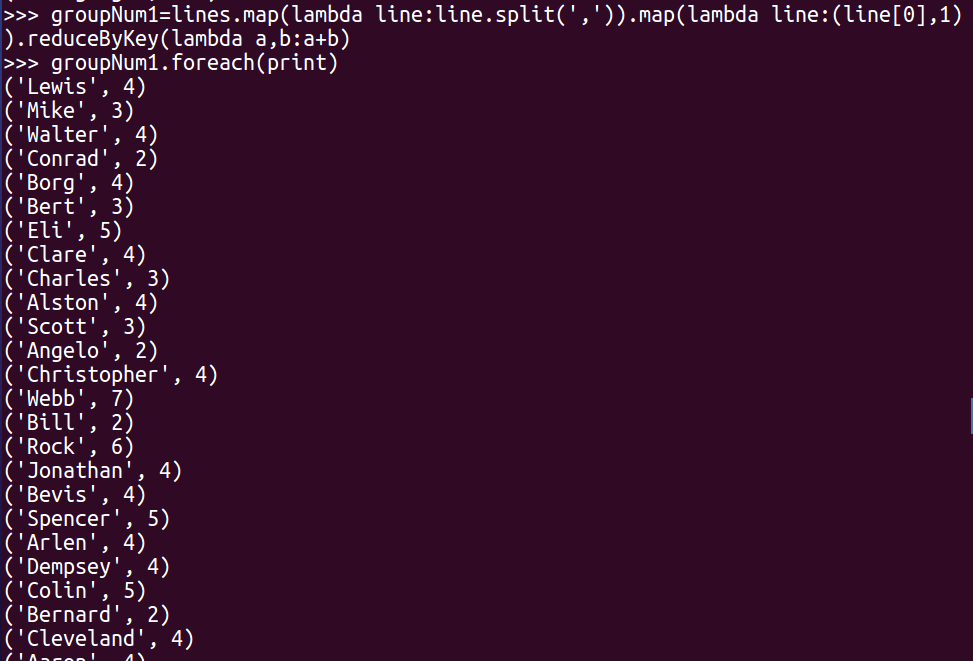
原文:https://www.cnblogs.com/DongDongQiangg/p/14619381.html