例如:当集群中的某一个主机节点异常宕机导致告警NodeDown被触发,同时在告警规则中定义了告警级别severity=critical。由于主机异常宕机,该主机上部署的所有服务,中间件会不可用并触发报警。根据抑制规则的定义,如果有新的告警级别为severity=critical,并且告警中标签node的值与NodeDown告警的相同,则说明新的告警是由NodeDown导致的,则启动抑制机制停止向接收器发送通知。
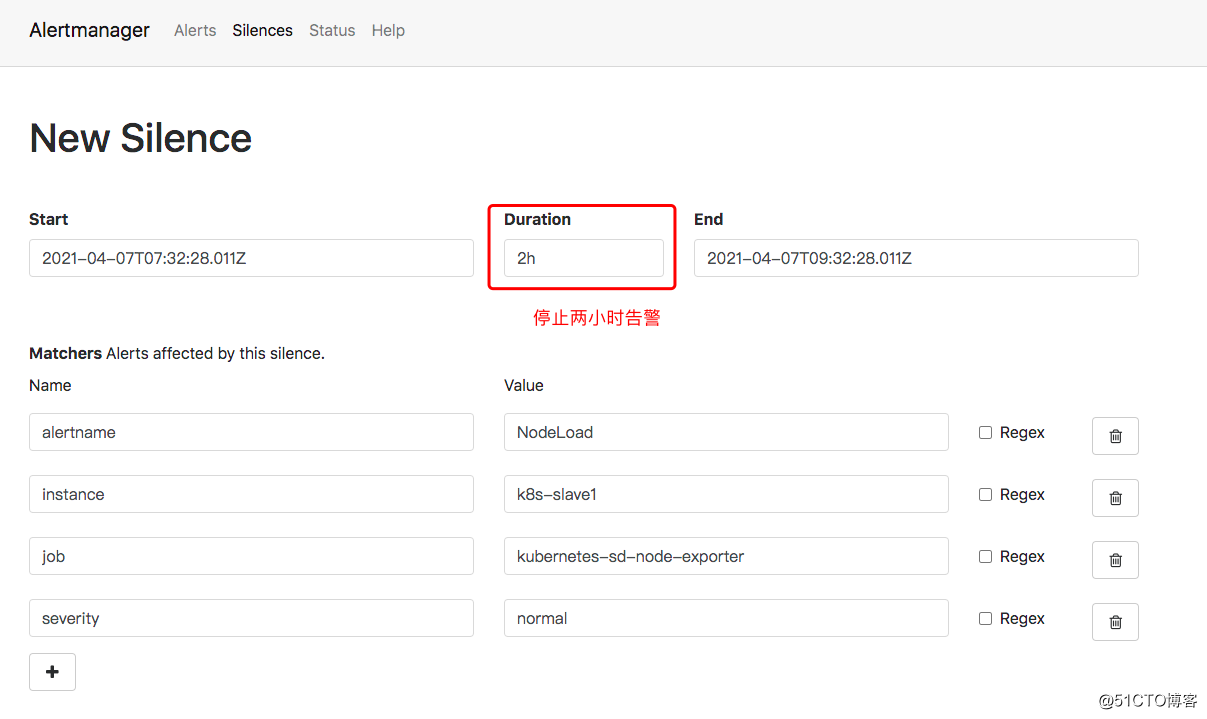
- source_match:
alertname: NodeDown
severity: critical
target_match:
severity: critical
equal:
- node inhibit_rules:
- source_match:
alertname: NodeMemoryUsage
severity: critical
target_match:
severity: normal
equal:
- instance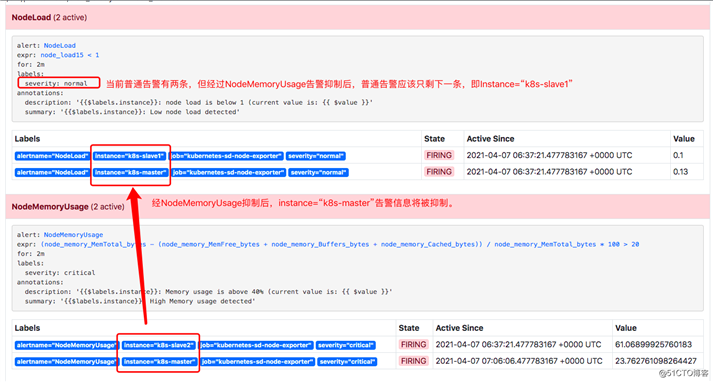

apiVersion: v1
data:
config.yml: |
global:
# 当alertmanager持续多长时间未接收到告警后标记告警状态为 resolved
resolve_timeout: 5m
# 配置邮件发送信息
smtp_smarthost: ‘smtp.163.com:25‘
smtp_from: ‘ibm.chick@163.com‘
smtp_auth_username: ‘ibm.chick@163.com‘
smtp_auth_password: ‘zmkang830316‘
smtp_require_tls: false
######################告警抑制内容#############################
inhibit_rules:
- source_match:
alertname: NodeMemoryUsage
severity: critical
target_match:
severity: normal
equal:
- instance
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
# 接收到的报警信息里面有许多alertname=NodeLoadHigh 这样的标签的报警信息将会批量被聚合到一个分组里面
group_by: [‘alertname‘]
# 当一个新的报警分组被创建后,需要等待至少 group_wait 时间来初始化通知,如果在等待时间内当前group接收到了新的告警,这些告警将会合并为一个通知向receiver发送
group_wait: 30s
# 相同的group发送告警通知的时间间隔
group_interval: 30s
# 如果一个报警信息已经发送成功了,等待 repeat_interval 时间来重新发送
repeat_interval: 1m
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: default
# 上面所有的属性都由所有子路由继承,并且可以在每个子路由上进行覆盖。
routes:
- receiver: critical_alerts
group_wait: 10s
match:
severity: critical
- receiver: normal_alerts
group_wait: 10s
match_re:
severity: normal|middle
# 配置告警接收者的信息
receivers:
- name: ‘default‘
email_configs:
- to: ‘345619885@qq.com‘
send_resolved: true
- name: ‘critical_alerts‘ #严重告警级别发送给ibm.chick@163.com
email_configs:
- to: ‘ibm.chick@163.com‘
send_resolved: true
- name: ‘normal_alerts‘ #普通告警级别发送给zhoumingkang@cedarhd.com
email_configs:
- to: ‘zhoumingkang@cedarhd.com‘
send_resolved: true #接受告警恢复的通知
kind: ConfigMap
metadata:
name: alertmanager
namespace: monitor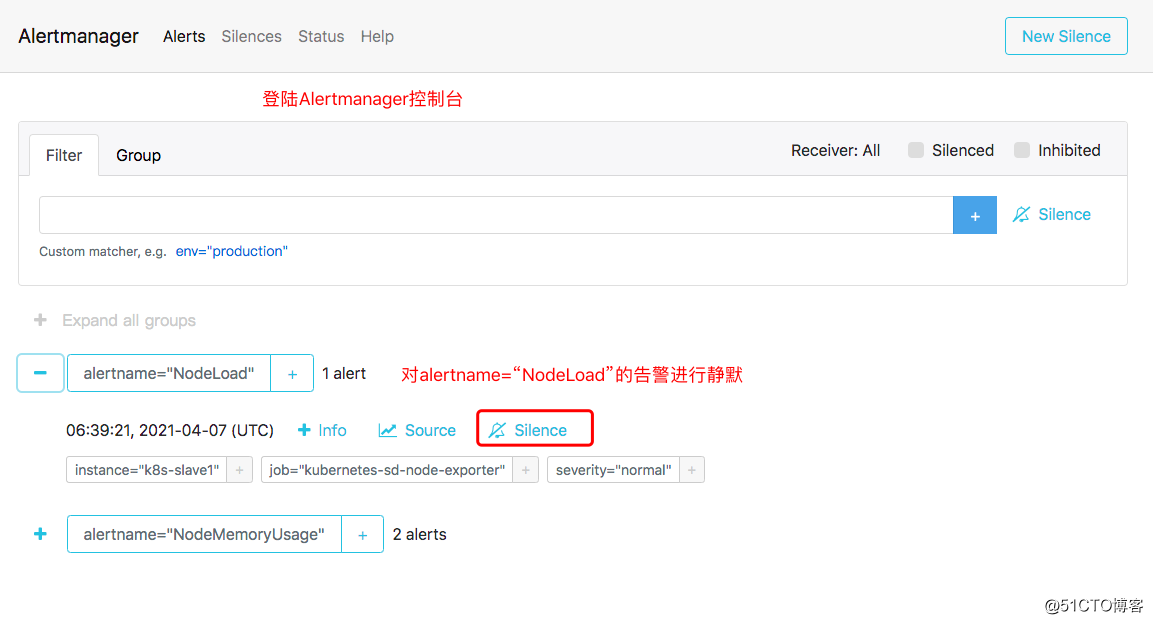
Prometheus 之 Alertmanager告警抑制与静默
原文:https://blog.51cto.com/12965094/2690336