当有了测试数据之后,就需要一个执行的类来执行case,就需要定义执行的主体
1、获取要执行的用例
2、通过用例步骤里面的开关判断对应步骤是否要执行,如果要执行,则对该步骤的数据进行处理和组装
3、通过关键字执行对应的步骤
4、对失败用例进行及错误进行捕获
使用pytest提供的pytest.mark.parametrize参数化方法,对需要进行操作的用例获取,

由于涉及用例的新增和删除,所以尽量将代码和数据分离,就使用yaml文件来管理需要执行用例内容,然后提取yaml文件的内容,实现参数的入参
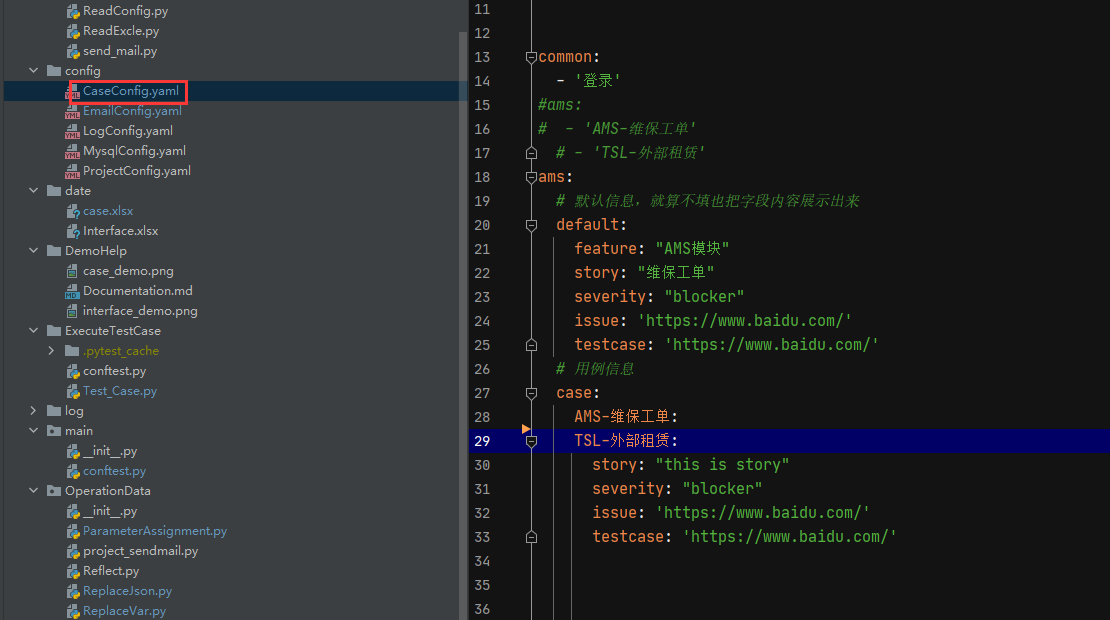
通过yaml的格式可以直接了当的知道哪些用例要被执行,哪些不需要执行,不需要后面更改代码的东西
在runcase类中通过入参的用例名称获取对应的信息

通过判断开关,然后对数据进行处理组装,达到可以进行执行的数据
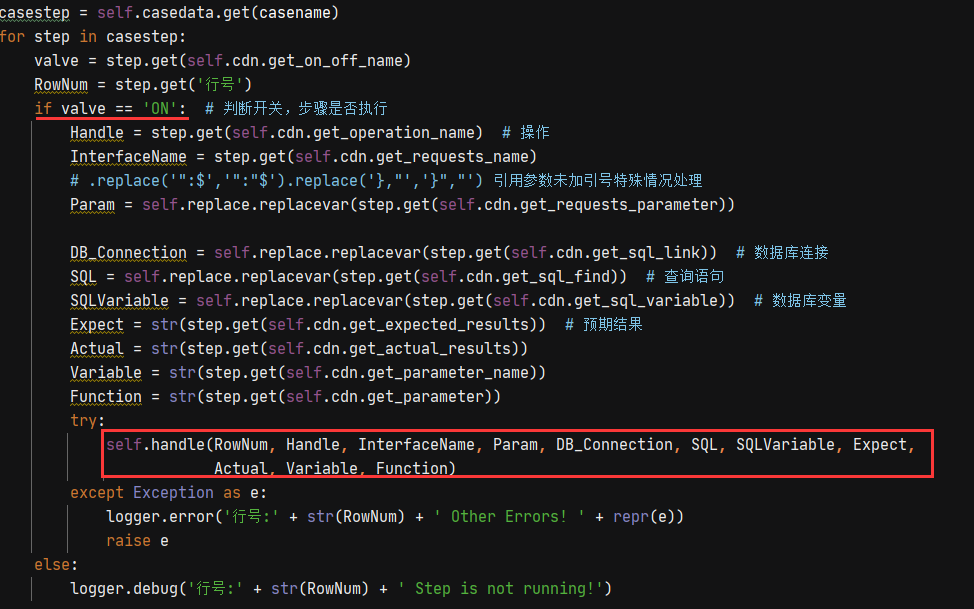
获取到要执行的用例之后,就可以通过用例中的关键字进行用例的步骤执行。通过循环来实现对操作步骤的遍历
目前基于业务中常用的操作,仅定义的4个操作步骤
分别为:发送请求,参数赋值,执行SQL,执行用例
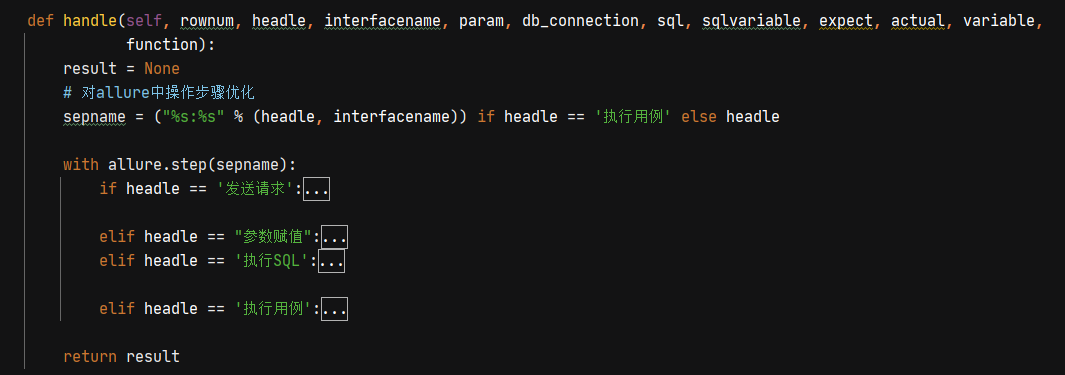
1、关键字为【发送请求】时,需要将接口中对应的数据进行提取和处理,组成发送接口数据需要的格式,目前针对的是json格式的请求体
【由于是excle中读取的数据,有可能会出现空行,换行符,还又变量等内容,需要在获取到接口数据之后进行处理 处理方法后续说】
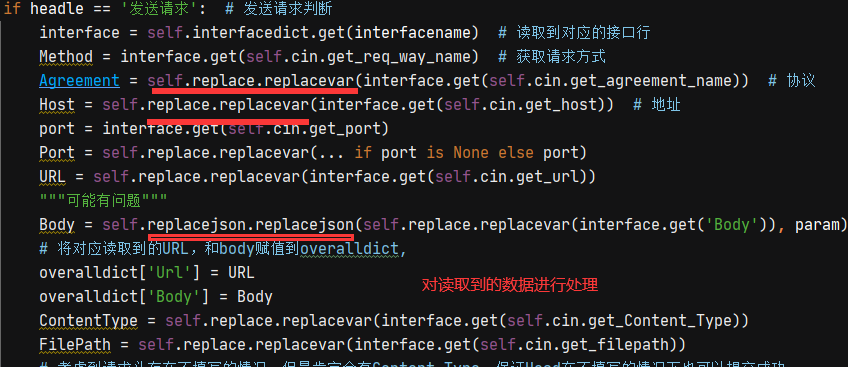
2、请求接口中需要对是否是文件传输进行判断。目前使用的是对请求接口的请求头判断是否是文件的传输。
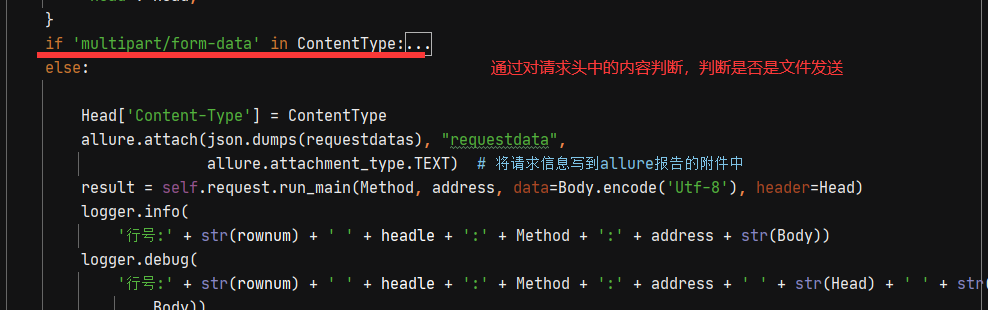
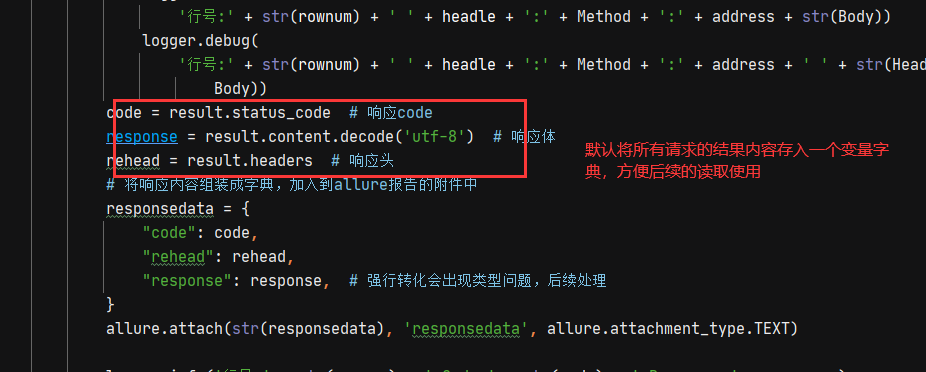
3、请求发送之后,默认储存【响应头,响应体,响应状态码】,方便后续的参数提取
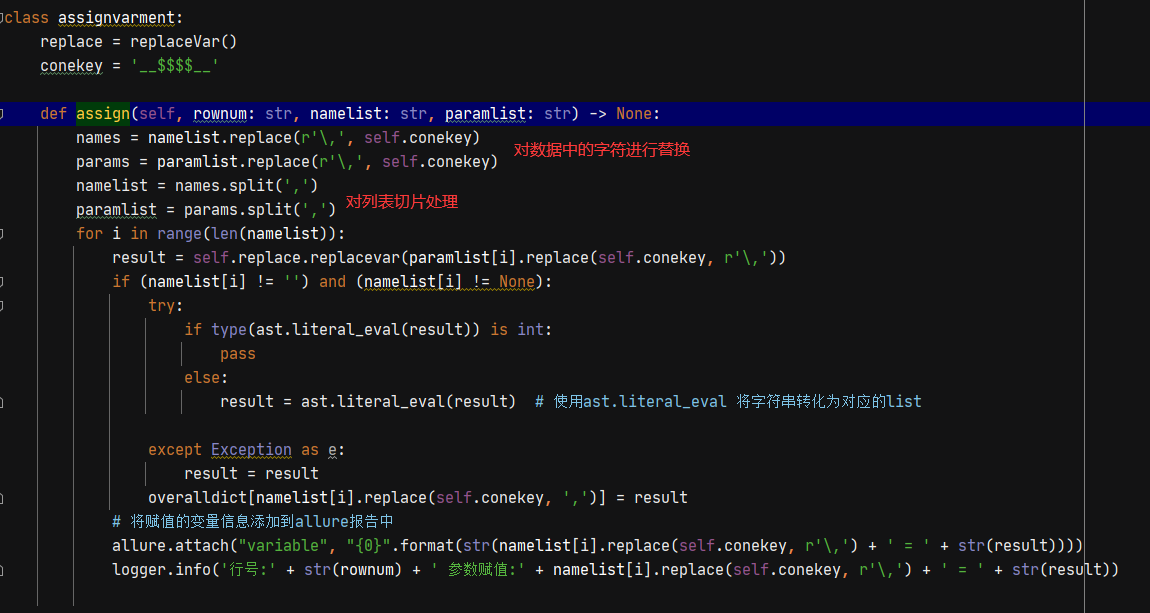
1、关键字为【参数赋值】时,针对是对变量的赋值,参照的方法类似于jmeter的方式,主要是针对于给变量定值
2、需要考虑多个变量的切片对应处理。

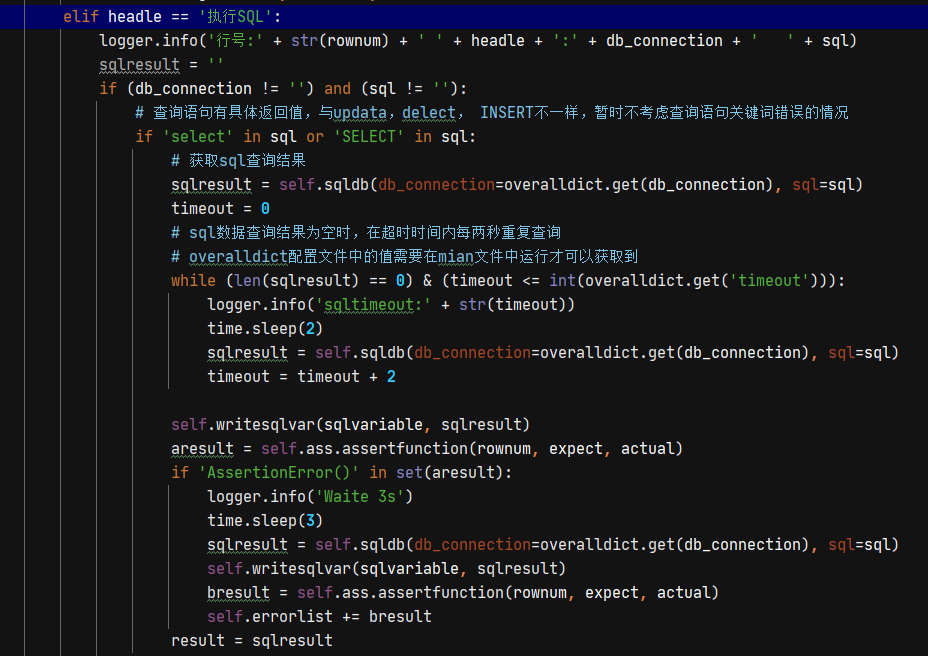
1、一般测试过程中都会涉及到数据库的查询,数据库查询之后的一般都是需要存储变量的,所以这里默认将对应的信息全部储存,然后通过类似于jmeter数据库查询结果的方式进行提取。
2、在查询过过程中数据库的连接可能会导致查询速度,然后需要考虑查询速度的容错机制,这里是重复查询等待,2秒的间隔,直到查询时间超过配置项设定的时间。
1、在测试过程中常会遇到执行用例有前置的情况,就是必须要执行某个独立的用例去取值才能进行本用例的参数入参,所以需要定义一个关键词为执行用例的,
2、在做流程自动化的时候,一个大的流程可能是由于多个小用例组成,在对流程的组装时,就可以使用执行用例这个关键字对小用例进行封装,提高用例的复用性和降低后续的维护成本
3、实现逻辑的话就直接复用前面的处理逻辑,只需要将方法在关键字的逻辑下进行执行就可以了

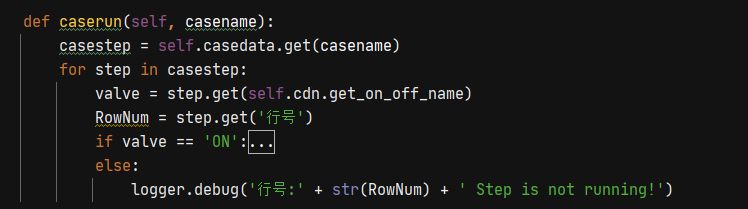
以上的话就是执行主体的设计了,有些详细的东西,如字符的处理,sql结果的存储等,在后续慢慢来。
主要是思路,代码的东西不是很重要
毕竟是菜鸟,有很多不完美的地方,后续有接触到更好的会持续改进
原文:https://www.cnblogs.com/ysynzy/p/14622635.html