Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene? 基础之上。
https://github.com/ZhongFuCheng3y/3y 引用Java3y
Term Dictionary,而我们需要通过分词找到对应的记录,这些文档ID保存在PostingList。Term Dictionary中的词由于是非常非常多的,所以我们会为其进行排序,Term Index,这层只存储 部分 词的前缀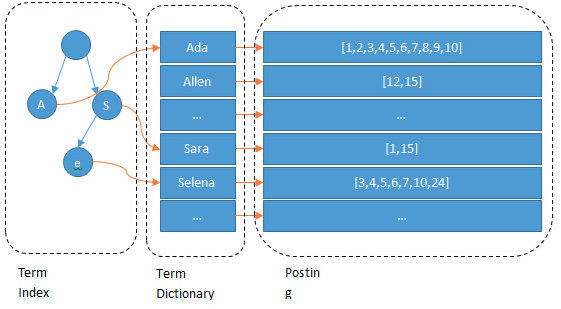
Term Index在内存中是以FST(Finite State Transducers)的形式保存的,其特点是非常节省内存。
PostingList会使用Frame Of Reference(FOR)编码技术对里边的数据进行压缩,节约磁盘空间。
一个Elasticsearch集群会有多个Elasticsearch节点,所谓节点实际上就是运行着Elasticsearch进程的机器。
在众多的节点中,其中会有一个Master Node,它主要负责维护索引元数据、负责切换主分片和副本分片身份等工作,如果主节点挂了,会选举出一个新的主节点。
一个Index的数据我们可以分发到不同的Node上进行存储,这个操作就叫做分片。分片会有主分片和副本分片之分。数据写入的时候是写到主分片,副本分片会复制主分片的数据,读取的时候主分片和副本分片都可以读。如果某个节点挂了,前面所提高的Master Node就会把对应的副本分片提拔为主分片,这样即便节点挂了,数据就不会丢。
Elasticsearch写入数据的时候,是写到主分片上的。
集群上的每个节点都是coordinating node(协调节点),协调节点表明这个节点可以做路由。
coodinate(协调)节点通过hash算法可以计算出是在哪个主分片上,然后路由到对应的节点
路由到对应的节点以及对应的主分片时,会做以下的事:
flush index到磁盘中。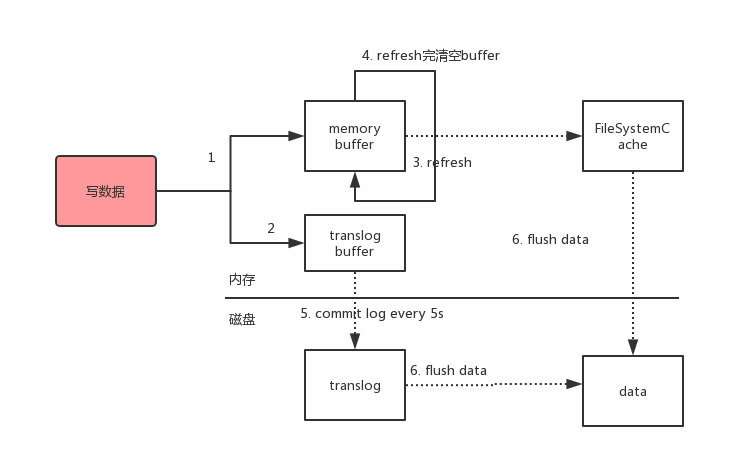
delete状态的doc给物理删除掉。查询我们最简单的方式可以分为两种:
由于Elasticsearch是分布式的,所以需要从各个节点都拉取对应的数据,然后最终统一合成给客户端。
原文:https://www.cnblogs.com/alideluobo/p/14633810.html