一、二分类损失函数
1.1 从一个简单的实例说起
对于一个二分类问题,比如我们有一个样本,有两个不同的模型对他进行分类,那么它们的输出都应该是一个二维向量,比如:
模型一的输出为:pred_y1=[0.8,0.2]
模型二的输出为:pred_y2=[0.6,0.4]
需要注意的是,这里的数值已经经过了sigmoid激活函数(为什么要这么说,这对于后面理解pytorch的几个函数是有帮助的),所以0.8+0.2=1,
比如样本的真实标签是
true_y=[1,0]
现在我们来求这两个模型对于这一个类别的分类损失,怎么求?先给出二分类损失函数,表达式如下:
![]()
这里的y表示的是真实地标签,y上面有一个符号的那个y表示模型的输出标签,我们带入进去计算得到:
cost1 = -[1*log0.8+(1-1)*log0.2] = 0.22314
cost2 = -[1*log0.6+(1-1)*log0.4] = 0.51083
我们可以看出,第一个模型的损失更小,自然我们觉得第一个模型更好,而且直观来看,第一个模型觉得正确的概率是0.8,自然比0.6要好。
二、多分类损失函数
2.1 关键概念——什么是交叉熵
对于连续性的概率分布而言,首先来看信息论中交叉熵的定义:
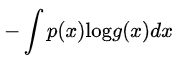
交叉熵是用来描述两个分布的距离的,神经网络训练的目的就是使 g(x) 逼近 p(x)。
对于离散型的概率分布而言,
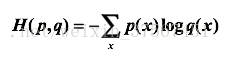
注意:交叉熵是一个信息论中的概念,它原来是用来估算平均编码长度的。给定两个概率分布p和q,通过q来表示p的交叉熵为上式,交叉熵刻画的是两个概率分布之间的距离,或可以说它刻画的是通过概率分布q来表达概率分布p的困难程度,p代表正确答案,q代表的是预测值,交叉熵越小,两个概率的分布约接近。
举个例子,假设有一个3分类问题,某个样例的正确答案是(1,0,0),这个模型经过softmax回归之后的预测答案是(0.5,0.4,0.1),
这里的数值已经经过了softmax激活函数(为什么要这么说,这对于后面理解pytorch的几个函数是有帮助的)
那么预测和正确答案之间的交叉熵为:
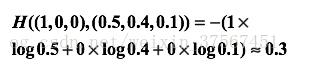
如果另一个模型的预测是(0.8,0.1,0.1),那么这个预测值和真实值之间的交叉熵是:
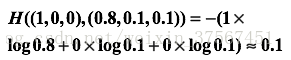
显然我们看到第一个模型的损失为0.3,二第二个模型的损失为0.1,第二个模型的损失更小,第二个预测要优于第一个。这里的(1,0,0)就是正确答案p,(0.5,0.4,0.1)和(0.8,0.1,0.1)就是预测值q,显然用(0.8,0.1,0.1)表达(1,0,0)的损失更小一些,准确度更高一些。
下面给一个多分类交叉熵损失函数的一般表达式:
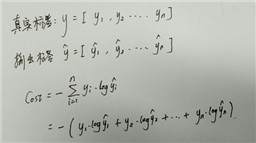
总结:不管是二分类,还是多分类问题,其实在计算损失函数的过程都经历了三个步骤:
(1)激活函数。通过激活函数sigmoid或者是softmax将输出值缩放到[0,1]之间,
(2)求对数。计算缩放之后的向量的对数值,即所谓的logy的值,求对数之后的值在[-infinite,0]之间
(3)累加求和。根据损失函数的定义,将标签和输出值逐元素相乘再求和,最后再添加一个负号求相反数,得到一个正数损失。
不管什么样的实现方式,都会经历这三个步骤,不同的是,可能有的函数会将其中的一个或者是几个步骤封装在一起。
pytorch中二分类损失函数有两种,它们分别是:
torch.nn.BCELoss() 和 torch.nn.BCEWithLogitsLoss()
BCE这三个字母其实就是binary cross entropy的缩写
他们的区别是:
(1)BCELoss:需要先将最后一层经过sigmoid进行缩放然后再通过该函数
(2)BCEWithLogitsLoss:BCEWithLogitsLoss就是把Sigmoid-BCELoss合成一步,不再需要在最后经过sigmoid进行缩放,直接对最后得到的logits进行处理。
备注:logits,指的是还没有经过sigmoid和softmax缩放的结果哦!
(1)softmax/sigmoid
这个只对应于上面的第一步骤,即相当于是激活函数操作,将输出缩放到[0,1]之间
(2)log_softmax
在softmax的结果上再做多一次log运算,即相当于是一次性完成第一步和第二步。
(3)nll_loss
这个实际上只对应于上面的第三个步骤,
(4)CrossEntropyLoss
CrossEntropyLoss就是把以上Softmax–Log–NLLLoss合并成一步
总结:上面的四种方法只是完成的功能,在具体的写代码的时候,还需要我们可以有两种方式来实现上面的四个功能,即通过函数的形式和通过类的形式,如下:
总结:通过上面的分析,我们知道了,求多分类交叉熵损失有三种途径可以实现,分别是:
(1)三步实现:softmax+log+nll_loss
(2)两步实现:log_softmax+nll_loss
(3)一步实现:crossEntropyLoss
原文:https://www.cnblogs.com/nlpers/p/14640202.html