这篇论文主要提出了一个网络,成为Multi-Factor Generative Adversarial Network,直接翻译过来的话就是多因子生成对抗网络。主要是期望能够探究影响推荐的其他因子(因素)到底起到了多大的作用。这里的因子指的是上下文的信息。说明:后文中判别器和鉴别器是相同的。
里面的核心有两个部分:
以前的论文主要还是基于Markov假设,并且使用了循环神经网络或者Transformer等网络结构来处理用户和物品的交互,这些方法利用了上下文的信息,能够很有效的表示了用户的行为。
序列的推荐器通常会使用极大似然估计进行优化,然而,很多论文发现基于MLE的训练很容易受到数据稀疏性或暴露偏差等问题的影响。
这篇论文的一个创新之处在于,利用生成对抗网络,希望能够从序列预测当中将因子利用部分解耦。对抗学习与推荐系统结构的方法,在这篇论文当中也有表述:在本文的框架中,生成器仅依靠用户与物品的交互数据预测未来的推荐物品,而判别器则根据现有的各种因素信息判断生成的推荐序列的合理性。这种方法可以更灵活地利用外部上下文形成顺序推荐,能够提高推荐的可解释性。
问题的假设为,有一组用户,每个用户都会对应一组物品,物品是具有时间顺序的。因子在这里也给出了例子,比如在音乐推荐中,因子(上下文)就表示如艺术家、专辑、人气等等。那么,最终要解决的问题就是,给出用户的一段交互历史,希望能预测该用户最可能的下一个交互的物品。
生成器就是比较常规的生成器,输入交互的物品序列,生成用户下一个交互物品的预测。而判别器有点不一样,判别器有多个,其数目取决于有多少因子(上下文),利用多角度的信息判断生成序列的合理性。每个判别器都会将物品序列作为输入,判别器的参数根据生成的交互物品序列以及真实的交互物品序列进行更新的。
【我不禁想到了如果因子很多很多,那岂不是要爆炸……所以感觉有点像是是面向数据集设计模型方法了。】
论文的结构图如下:
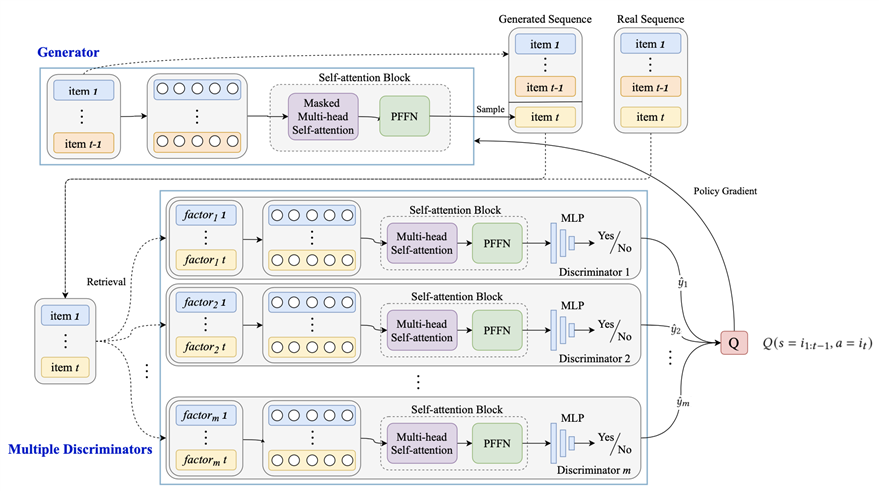
MFGAN论文结构图
搞个这样的模型有三点原因:
生成器的主要组成模块:
对于鉴别器来说:
由于物品集的采样是一个离散的过程,所以对于我们的推荐任务,不能直接应用梯度下降法来解决原来的GAN公式。所以需要强化学习进行指导。接下来说强化学习如何接管。按照强化学习的设定:
整体算法流程

[SIGIR2020] Sequential Recommendation with Self-Attentive Multi-Adversarial Network
原文:https://www.cnblogs.com/nomornings/p/14641405.html