数据库(DataBase,简称DB)是以特定数据结构组织,在计算机上存储和管理的数据仓库。
数据库的优点:持久化存储数据。数据独立存储、且集中控制、方便存储和管理数据。统一使用SQL语句操作。数据一致性和可维护性,保证数据安全可靠。
关系数据库管理系统(Relational Database Management System,RDBMS),通过关系模型来组织数据的数据库,关系型数据库把数据库看成右实体和联系组成
常见的关系型数据库:****Oracle、DB2、Microsoft SQL Server、Microsoft Access、MySQL
常见的非关系型数据库:NoSql、Cloudant、MongoDb、redis、HBase
SQL (Structured Query Language):结构化查询语言
SQL就是访问和处理关系数据库的计算机标准语言,它定义了所有操作关系型数据库的规则,大部分数据库在SQL的标准上进行了扩展。而每一种数据库操作的方式存在不一样的地方,称为方言。
但凡涉及到关系型数据库就离不开SQL
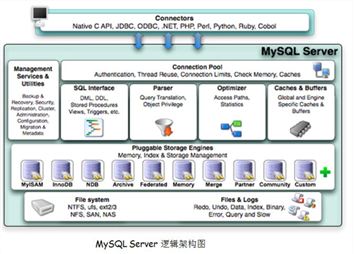
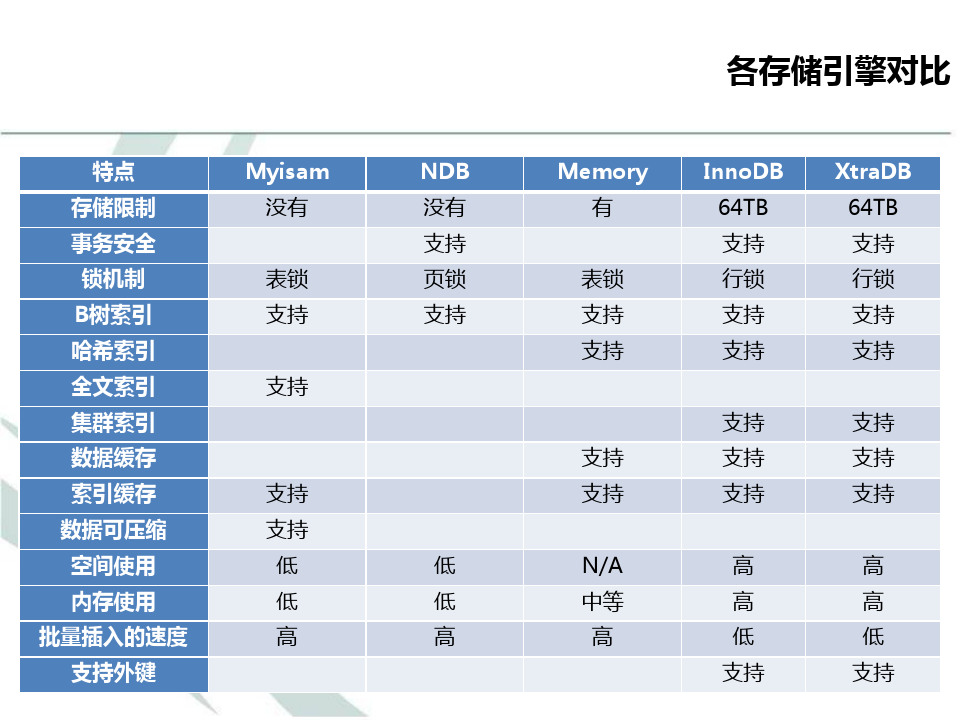
InnoDB引擎、MyISAM引擎、MEMORY引擎、CSV引擎、ARCHIVE引擎、BLACKHOLE引擎
SQL通用语法
MySQL数据库的SQL语句不区分大小写。
二种注释
A.单行注释:--注释内容
B.多行注释:/* 注释内容 */
临时表与内存表
临时表:对大数据量表做一个临时表,提高查询速度,临时表建在内存中,数据存放在内存中
内存表:对大数据量表做一个内存表,表结构存放再磁盘中,数据存放在内存中
数据类型
| 数据类型 | 含义 |
|---|---|
| char(n) | 长度为 n 的定长字符串 |
| varchar(n) | 最长度为 n 的边长字符串 |
| int或 interger | 长整数 |
| smallint | 短整数 |
| double(6,3) | 双精度浮点数,代表共保留6位数字,小数点后保留3位(也可不设置直接使用) |
| float(n) | 浮点数,精度至少为 n 位数字(也可不设置直接使用) |
| date | 日期,只包含年月日,yyyy-MM-dd |
| timestamp | 时间戳类型,包含年月日时分秒,yyyy-MM-dd HH:mm:ss |
1.约束保证数据的完整性和一致性。
2.约束分为表级约束和列级约束。
3.针对某一列,叫做列级约束。针对多列属性的约束,叫做表级约束。
4.约束类型包括:
not null (非空约束)
primary key (主键约束)[?pra?meri] [ki?]
unique key (唯一约束)[ju?ni?k] [ki?]
default (默认约束)[d??f??lt]
foreign key (外键约束)[?f??r?n] [ki?]
auto_increment (自动编号)--必须与住建一起使用
数据定义语言——DDL(Data Definition Language)
--允许用户定义 (创建) 数据库对象:数据库,表,列等
数据操作语言——DML(Data Manipulation Language)
--允许用户对数据库中表的数据进行增删改
数据查询语言——DQL(Data Query Language)
--允许用户查询数据库中表的记录(数据)
数据控制语言——DCL(Data Control Language)
--用来定义数据库的访问权限和安全级别,及创建用户
数据库
-- 启动关闭服务器:cmd(管理员)-->net stop MySQL、net start MySQL或者services.msc打开服务设置
1.C(Create):
-- 创建数据库
create database 数据库名;
-- 创建数据库,如果不存在,才创建
create database if not exists 数据库名;
-- 创建数据库,并制定字符集
create database 数据库名 character set 字符集名;
2.R(Retrieve):
--查询所有数据库名称
show databases;
--查询某个数据库的字符集:查询某个数据库的创建语句
show create database 数据库名;
3.U(Update):
--删除数据库
drop database 数据库名;
--判断数据库存在,存在才删除
drop database if exists 数据库名;
4.D(Delete):
--使用数据库
use 数据库名;
--查询当前正在使用的数据库名称
select database();
表
1.C(Create):
--创建表
create table 表名(
列名1 数据类型1 约束 comment‘别名‘,
列名2 数据类型2,
列名3 数据类型3,
约束(列名1)
)engine = innodb default charset utf8;
--复制表
--复制表结构、主键、索引
1.create table new_tb like past_tb;
--插入数据
2.insert new_tb select * from past_tb;
--复制表结构、数据,不能复制主键、索引
3.create table new_tb select * from past_tb;
--复制表结构、不复制数据,不能复制主键、索引
4.create table new_tb select * from past_tb where 0;
2.R(Retrieve):
--查询数据库下的所有表
show tables;
--查询表结构
desc 表名;
3.U(Update):
--修改表名
alter table 表名 rename to 新表名;
--修改表的字符集
alter table 表名 charcter set 字符集名称;
--添加一列
alter table 表名 add 列名 数据类型;
--修改列名称 类型
alter table 表名 change 列名 add 新列名 新数据类型;
alter table 表名 modify 列名 新数据类型;
--注意
修改数据类型,修改字段位置 ---用modify
修改名字 --就用change
--删除列
alter table 表名 drop column 列名;
--约束
alter table 表名 modify 列名 数据类型 约束;--建完表添加约束
alter table 表名 add 列名 数据类型 约束;--新增字段并为其设置约束
alter table 表名 drop 约束;--删除约束
4.D(Delete):
drop table 表名;
drop table if exists 表名;
1.insert:
--语法
insert into 表名(列名1,列名2,...) values(值1,值2,...);
--注意
A: 列名和值要一一对应。
B: 如果表名后,不定义列名,则默认给所有列添加值
Eg:insert into 表名 values(值1,值2,...值n);
C: 除了数字类型,其他类型需要使用引号(单双都可以)引起来
2.delete:
--语法
delete from 表名 [where 条件]
--注意
若不加条件,则删除表中所有记录
--删除所有记录的两种方式
A: delete from 表名; -- 不推荐使用,有多少条记录就会执行多少次删除操作
B: truncate table 表名; -- 推荐使用,先删除表,然后再创建一张一样的表,效率更高
3.update:
--语法
update 表名 set 列名1=值1,列名2=值2,...[where 条件];
--注意
如果不限定条件,则会修改表中的所有记录
select * from 表名;
1.语法:
select
--聚合函数
--字段
from
--表名
where
--条件查询、数据过滤
group by
--分组
having
--设置分组条件
order by
--排序
limit
--分页限定
2.聚会函数
count();--返回某列行数,如果为null不统计
sum(); --返回某列值的和
avg(); --计算某列平均值
max(); --返回某列最大值
min(); --返回某列最小值
3.sql查询解析顺序
(1) from
(2) where
(3) group by
(4) (聚合函数)
(5) having
(6) select
(7) order by
(8) limit
1.基础查询
--查询所有
select * from 表名;
--去重
select distinct 字段1,字段2,... from 表名;
--别名
select 字段1 别名1 from 表名;
select 字段1 as 别名1 from 表名;
2.条件查询、数据过滤
1.where子句后跟的条件
2.运算符
< > <= >= = <>
not
and | or
in() | not in()
is null | is not null
between A and B
any() | all()
exists()
union | union all
minus | intersect
like(模糊查询): _单个任意字符; %多个任意字符;
子查询:where型子查询、from型子查询、exists型子查询
3.例子
/*< > <= >= = <>*/
select * from classes where mysql > 90;--查询mysql分大于90的同学
/*not:操作符有且只有一个功能:否定它之后所跟的任何条件*/
select * from classes where mysql not between 80 and 90;--查询mysql分数小于为[80,90]之间的同学
/*and | or*/
select * from classes where mysql > 90 and java > 90;--查询mysql分大于90且Java大于90分的同学
select * from classes where mysql > 90 or java > 90;--查询mysql分大于90或者Java大于90分的同学
/*in() | not in()*/
select * from classes where mysql in(70,80,90);--查询mysql分等于(70,80,90)的同学
select * from classes where mysql in not(70,80,90);--查询mysql分不等于(70,80,90)的同学
/*is null | is not null*/
select * from classes where mysql is null;--查询mysql分数为空的同学
select * from classes where mysql is not null;--查询mysql分数不为空的同学
/*better A and B*/
select * from classes where mysql between 80 and 90;--查询mysql分数为[80,90]之间的同学
/*any() | all()*/
--all():全真则真,查询mysql分数大于大数据二班所有同学mysql分数的同学
select * from classes where mysql > all(select mysql from classes where student=‘大数据2班‘);
--any():一真则真,查询mysql分数小于大数据二班所有同学mysql分数的同学
select * from classes where mysql < any(select mysql from classes where student=‘大数据2班‘);
/*exists():不返回记录,如果内层sql成立则返回true,否则返回false*/
--如果全班有同学mysql成绩等于100就返回所有同学,如果没有就不返回
select * from classes where exists(select * from classes where mysql=100);
/*union | union all*/
--union
select student from classes where mysql=90
union --对两个结果集进行并集,不包括重复行
select student from classes where mysql=91;
--union all
select student from classes where mysql=90
union all --对两个结果集进行并集操作,包括重复行
select student from classes where mysql=91;
/*minus | intersect*/
--minus:A minus B 即A结果集-B结果集
--intersect:A intersect B 即A结果集交B结果集
/*like*/
-- _单个任意字符
--_朝_:查询第名字的第二个字是朝字的同学
select * from classes where name like ‘_朝_‘;
--__阳:查询第名字的第三个字是阳字的同学
select * from classes where name like ‘__阳‘;
-- %多个任意字符
--汪%:查询以汪开头的名字
select * from classes where name like ‘汪%‘;
--%朝%:查询中间带有朝字的名字
select * from classes where name like ‘%朝%‘;
--%阳:查询以阳结尾的名字
select * from classes where name like ‘%阳‘;
/*子查询*/
--where型子查询:查询java成绩大于梅西的java成绩的同学
select * from classes where java > (select java from classes where name=‘梅西‘);
--from型子查询:将返回的结果作为临时表as设置别名,在临时表中查询大数据一般中java分数大于90的同学
select * from (select * from classes where student=‘大数据1班‘) as table1 where java > 90;
--exists型子查询:如果内层sql成立则返回true,否则返回false。如果班级中有"高琳"这个名子就返回该班级同学
select * from classes where exists(select * from classes where name=‘高琳‘);
3.分组查询
--group by:分组查询,在使用group by时最好与聚合函数一起使用。
--查询大数据1班的最低分
select min(mysql) from classes where student=‘大数据1班‘ group by student;
4.聚合函数
--count()、sum()、avg()、max()、min()
--查询大数据1班的平均分
select avg(mysql) from classes where student=‘大数据1班‘ group by student;
5.设置分组条件
--having:只能用于group by,where 语句可以进行过滤,他是分组之前进行过滤,如果想在分组之后进行过滤必须使用having语 句来进行
--不使用having分组,查询每个班级的mysql平均分
select student,avg(mysql) from classes group by student;
--使用having分组,查询班级mysql平均分大于80分的班级
select student,avg(mysql) from classes group by student having avg(mysql)>80;
6.排序
--order by:[asc|desc] 分别为升序、降序。升序可以默认不写,但是降序必须要说明。
--升序:根据mysql分数升序
select name,mysql from classes order by mysql;
--降序:根据mysql分数降序
select name,mysql from classes order by mysql desc;
7.分页查询
--limit:[起始位,步长]
--查询mysql成绩前五名的同学
select name,mysql from classes order by mysql desc limit 1,5;
总结:分组查询一般是配合聚合函数一起使用的,而设置分组条件又是和分组查询一起使用的,所有分组查询、聚合函数、分组条件一起使用时重点时分清除要分组的对象,再配合分组条件使用。在sql解析中先执行顺序是group by、聚合函数、分组条件。
# DBA:数据库管理员
# DCL:管理用户,授权
*. 管理用户
1. 添加用户:
- 语法:CREATE USER ‘用户名‘@‘主机名‘ IDENTIFIED BY ‘密码‘;
-在添加用户的同时设置权限:grant select,insert,update,delete on 数据库.* 用户名@主机名 identified by ‘password‘;
2. 删除用户:
- 语法:DROP USER ‘用户名‘@‘主机名‘;
3. 修改用户密码:
UPDATE USER SET PASSWORD = PASSWORD(‘新密码‘) WHERE USER = ‘用户名‘;
SET PASSWORD FOR ‘用户名‘@‘主机名‘ = PASSWORD(‘新密码‘);
4. 查询用户:
-- 1. 切换到mysql数据库
USE myql;
-- 2. 查询user表
SELECT * FROM USER;
* 通配符: % 表示可以在任意主机使用用户登录数据库
*. 权限管理:
1. 查询权限:
-- 查询权限
SHOW GRANTS FOR ‘用户名‘@‘主机名‘;
SHOW GRANTS FOR ‘lisi‘@‘%‘;
2. 授予权限:
-- 授予权限
grant 权限列表 on 数据库名.表名 to ‘用户名‘@‘主机名‘;
-- 给张三用户授予所有权限,在任意数据库任意表上
GRANT ALL ON *.* TO ‘zhangsan‘@‘localhost‘;
3. 撤销权限:
-- 撤销权限:
revoke 权限列表 on 数据库名.表名 from ‘用户名‘@‘主机名‘;
REVOKE UPDATE ON db3.`account` FROM ‘lisi‘@‘%‘;
1.内连接查询: select * from ...[inner] join...on...;
select * from 表1 A [inner] join 表2 B on A.cid=B.tid;
2.外连接查询
- 左连接查询: select * from ...left join...on...;
select * from 表1 A left oin 表2 B on A.cid=B.tid;
- 右连接查询: select * from ...right join...on...;
select * from 表1 A right oin 表2 B on A.cid=B.tid;
3.交叉连接查询(基本不用)
4.自然连接查询(很少用)
5.在多表查询sql执行顺序
(1)from
(3) join
(2) on
(4) where
(5) group by(开始使用select中的别名,后面的语句中都可以使用)
(6) (聚合函数)
(7) having
(8) select
(9) distinct
(10)order by
内连接查询与外连接查询的区别:内连接查询只配置两个表的字段的交集。外连接查询中左连接可以简单理解为left前面的表为主表后面的为从表,主表数据必须全部展示,若根据连接条件,在从表中未找到对应数据,则字段显示为NULL。右连接查询与左连接查询正好相反。
原文:https://www.cnblogs.com/w-eye/p/14647401.html