Redis 简介
设置 key value 数据
命令: set key value
示例: set name zhangsan
数据查询
命令: get key
示例: get name
若对应的数据不存在,返回空( nil )
清屏
命令: clear
帮助命令
命令: help 指令
示例: help set
退出命令
exit
quit
添加/修改数据
命令: set key value
示例: set name zhangsan //添加数据
set name lisi //对同一个 key 再次赋值,就为修改数据
获取数据
命令: get key
示例: get name
删除数据
命令: del key
示例: del name
补充
添加修改多个数据(多个数据中原始存在的的则会覆盖)
命令: mset key1 value1 key2 value2 ...
示例: mset name zhangsan age 18 ...
获取多个数据(不存在的数据会给出 nil 值)
命令: mget key1 key2 ...
示例: mget name age ...
追加信息到原始信息后部(若原始信息存在则追加,否则新建数据)
命令: append key value
示例: append age +
例如:原先 age 的数据为 18,append 后为: 18+
返回值为追加后,字符串的长度
获取字符串长度
命令: strlen key
示例: strlen name
单数据操作
多数据操作
如何选择
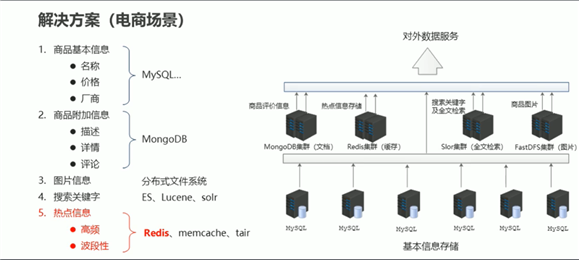
业务场景
解决方案
具体操作
设置数值数据增加指定范围的值
命令: incr key // 对字符串数值形式的数据进行 + 1 的操作
示例: incr num // num 对应的 value 值 + 1
命令: incrby key 增加值 // 对字符串数值形式的数据进行加上指定数值的操作
示例: incrby num 10 // num 对应的 value 值 + 10
命令: incrbyfloat key 增加值 // 对字符串数值新式的数据进行加上指定浮点数的操作
示例: incrbyfloat num 1.5 // num 对应的 value 值 + 1.5
设置数值数据减少指定范围的值
命令: decr key // 对字符串数值形式的数据进行 - 1 的操作
命令: decrby key 减少值 // 对字符串数值形式的数据进行减去指定数值的操作
补充
业务场景
解决方案
具体操作
命令: setex key 秒数 value // 设置 key 对应的 value 数据生命周期为多少秒
示例: setex num 5 value // 设置 num 对应的 value 数据生命周期为 5 秒
命令: psetex key 毫秒数 value // 设置 key 对应的 value 数据生命周期为多少毫秒
示例: psetex num 5 value // 设置 num 对应的 value 数据生命周期为 5 毫秒
补充
业务场景
解决方案
数据库中热点数据 key 的命名规范
表名 主键名 主键值 字段名
user : id : 1001 : name表名 主键名 主键值 字段名
order : id : 1143 : order_name
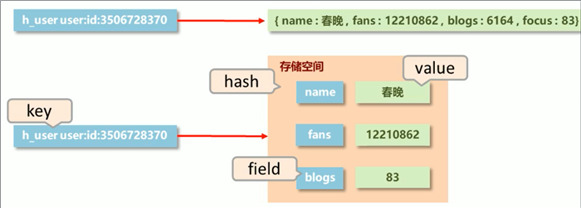
添加/修改数据
命令: hset key field value
示例: hset user name zhangsan
获取数据
命令: hget key field
示例: hget user name
命令: hgetall key // 获取 key 对应的所有 field 数据
示例: hgetall user
删除数据(也删除多个 field 的数据)
命令: hdel key field1 [field2]
示例: hdel user name age
添加/修改多个数据
命令: hmset key field1 value1 field2 value2 ...
获取多个数据
命令: hmget key field1 field2 ...
获取 hash 表中 key 对应字段( field )的数量
命令: hlen key
获取 hash 表中是否存在指定字段
命令: hexists key field
获取 hash 表中 key 对应的所有字段名或字段值
命令: hkeys key // 获取指定 key 对应的所有 field 的值
命令: hvals key // 获取指定 key 对应的所有 filed 的 value 值
设置指定字段的数值数据增加指定范围的值
命令: hincrby key field 增加值 // 执行指定 key 的数值类型的 field 属性加上指定值的操作
命令: hincrbyfloat key field 增加值 // 执行指定 key 的数值类型的 field 属性加上指定浮点值的操作
补充
业务场景
数据模型
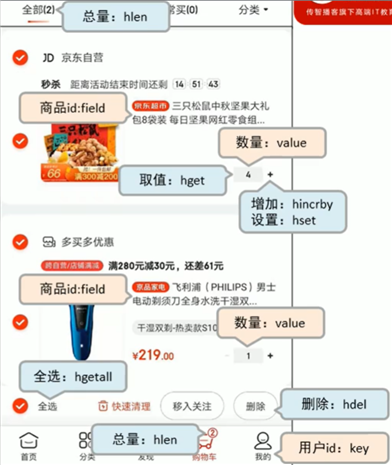
业务分析
缺点
解决方案
每条购物车中的商品记录保存两条 field
优化
此时,保存的商品信息,对于同一个商品,实际上是一样的,差距只是在于购买的商品数量不同,因此,可以将商品信息抽取出来,将商品的 id 作为 field,商品信息的 json 字符串作为 value,成为一个键值对,也就是一个商品 hash,这样,就可以将多个不同的商品 hash 独立出来,作为一个公共的 hsah 区域(也可以根据商品种类,分为多个公共 hash 区域),每个用户的购物车中,保存的就只是商品购买数量,至于商品的信息,全部都去公共的商品 hash 中通过商品 id 进行查询
不可能一开始就将所有的商品全部加入到商品公共 hash 中去,因为每时每刻都可能会出现新的商品上架,可以采取用户购买了一种商品,就将该商品加入到商品公共 hash 中去,同时为了避免重复的商品信息,使用
命令: hsetnx key field value // 判断当前 key 对应的 field 是否有值,若有,则不进行添加操作
来添加商品信息,该命令会先判断当前 key 对应的 field 是否有值,若有,则不进行添加操作,若该商品的信息发生变化,则依然通过 hset 来修改其信息

添加/修改数据
命令: lpush key value1 [value2] ... // 从左边开始添加多个数据到 list 中
命令: rpush key value1 [value2] ... // 从右边开始添加多个数据到 list 中
获取数据(获取数据统一从左边进行获取)
// 获取列表中指定索引范围的数据(索引从 0 开始,若添加数据时,使用的是 lpush 则查出的数据顺序与添加时的顺 序相反,反之亦然(类似于 Stack 结构);倒数第一个索引为 -1,可以直接通过 lrange 0 -1 查询出所有数据)
命令: lrange key start stop
// 获取列表中指定所有的数据(索引从 0 开始)
命令: lindex key index
// 获取指定列表的长度
命令: llen key
获取并移除数据(可以从右边也可以从左边获取)
// 从左边出元素
命令: lpop key
// 从右边出元素
命令: rpop key
补充
规定时间内,从多个 list 中获取并移除数据
命令: blpop key1 [key2] ... timeout // 从左边开始移除
命令: brpop key1 [key2] ... timeout // 从右边开始移除
解析
业务场景
解决方案
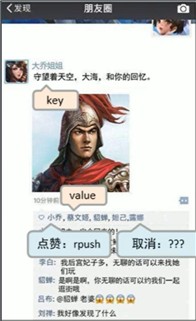
每一条朋友圈都是唯一的,可以作为一个 key,而朋友圈的点赞列表就作为一个 list
当有人点赞时,执行 lpush 或 rpush 操作将点赞人的信息放入 list 中并显示出来
当有人取消点赞时,使用
// 移除指定的数据,意为: 删除指定 key 对应的 list 中的 count 个 value 数据,也就是说,list 中有 3 个 a ,可以使用 lrem list 1 a 只删除一个 a ,也可以使用 lrem list 3 a 将 3 个 a 都删除
命令: lrem key count value
补充
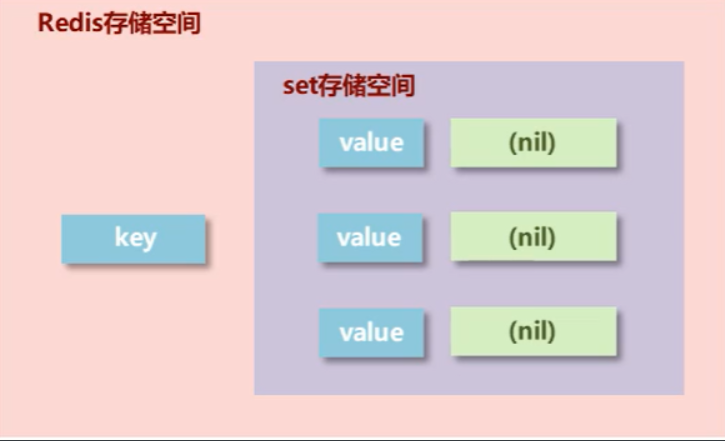
添加数据
命令: sadd key value1 value2
获取全部数据
命令: smembers key
删除数据
命令: srem key value1 value2
获取集合数据总量
命令: scard key
判断集合中是否包含指定的数据
sismember key value
业务场景
业务分析
解决方案
随机获取集合中指定数量的数据
命令: srandmember key [count]
随机获取集合中的某个数据并将数据移出集合
命令: spop key
补充
业务场景
解决方案
求两个集合的交,并,差集
命令: sinter key1 [key2] // 交集
命令: sunion key1 [key2] // 并集
// 差集(redis 中的差集是有方向性的,以在左边的 key 对应的集合为准,以右边的集合比较,相当于从左边的集合中元素去除与右边相比较,相同的元素,剩下的就叫差集)
命令: sdiff key1 [key2]
将两个集合的交,并,差集存储到指定集合中
命令: sinterstore 指定集合 key1 [key2]
命令: sunionstore 指定集合 key1 [key2]
命令: sdiffstore 指定集合 key1 [key2]
将指定数据从原始数据移动到指定目标集合中
命令: smove source 指定集合 指定元素
补充
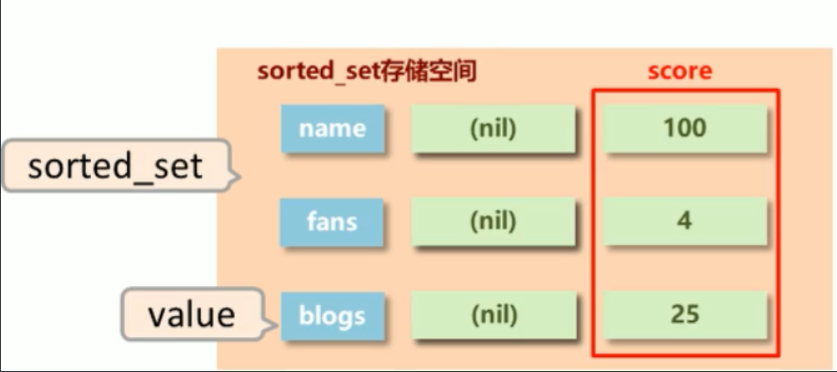
添加数据
命令: zadd key score1 member1 [score2 member2]
获取全部数据
// 升序获取 start 到 stop 索引之间的值(闭区间),加上 WITHSCORES 参数后,会显示 score 字段
命令: zrange key start stop [WITHSCORES]
// 降序获取 start 到 stop 索引之间的值,加上 WITHSCORES 参数后,会显示 score 字段
命令: zrevrange key start stop [WITHSCORES]
删除数据
命令: zrem key member [member ...]
按条件获取数据
// 查询指定范围 min ~ max 内的数据(闭区间),升序,limit 限定查询结果,用法与 MySQL 相同
命令: zrangebyscore key min max [WITHSCORES] [LIMIT]
// 查询指定范围 min ~ max 内的数据(闭区间),降序,limit
命令: zrevrangebyscore key max min [WITHSCORES]
按条件删除数据
// 删除 start 到 stop 索引之间的值(闭区间)
命令: zremrangebyrank key start stop
命令: zremrangebyscore key min max
注意
获取集合数据总量
// 获取数据总数
命令: zcard key
// 获取指定范围 min ~ max(闭区间) 的数据总数
命令: zcount key min max
集合交并操作
// 多个集合的 交 操作,执行 交 操作时,还会对集合中的 score 进行求和操作(还有其他操作,如最大值等)
命令: zinterstore 保存结果的集合 参与操作的集合个数 key1 key2 ...
// 多个集合的 并 操作,执行 并 操作时,还会对集合中的 score 进行求和操作(还有其他操作,如最大值等)
命令: zunionstore 保存结果的集合 参与操作的集合个数 key1 key2 ...
未完,持续更新 ......
原文:https://www.cnblogs.com/hashmap-put/p/14656723.html