标准化流
深度生成模型[3]
- 统计学和机器学习的一个主要目标是根据从某个分布得到的样本建模该分布,这是无监督学习的一个例子,有时称作生成建模generative modelling。应用包括密度估计density estimation, 异常检测outlier detection, 先验创建prior construction以及数据集总结dataset summarization
- 生成模型: 数据分布的模型。真实数据分布\(p_{data}(\vec x)\),建模数据分布\(p_{\theta}(\vec x)\),其中\(\theta\)是参数。最大似然估计:为数据指定最大似然来找到模型,\(
\begin{equation}
\begin{aligned}
\theta^* & = \arg\min_{\theta}D_{KL}(p_{data}(\vec x)||p_{\theta}(\vec x)) \& = \arg\min_{\theta}E_{p_{data}(\vec x)}[\log p_{data}(\vec x)-\log p_{\theta}(\vec x)] \& = \arg\max_{\theta}E_{p_{data}(\vec x)}[\log p_{\theta}(\vec x)] \approx \frac{1}{N}\sum_{i=1}^N\log p_{\theta}(\vec x^{(i)})
\end{aligned}
\end{equation}
\)
- 学习生成模型:可以生成新数据样例(从学到的分布中采样);当数据生成的成本很高时这是有用的,如一个需要很长时间运行的现实世界的实验;采样也用于创建高维空间积分的估计器。可以计算测试数据的似然,用于拒绝采样或判断模型的好坏。可以发现变量之间的条件关系。可以从数据中抽取结构
- 深度生成模型:使用深度神经网络建模数据分布的生成模型
- 深度生成模型的分类:
- 自回归模型autoregressive models: 机器翻译;可归到精确似然模型
- 隐含变量模型(explicit)latent variable models: VAE[2]
- 隐式生成模型implicit generative models: GAN[1]; 模型被定义为隐式采样过程
- 基于能量模型energy-based models
- 基于标准化流精确似然模型exact-likelihood models based on normalizing flows(可逆生成模型invertible generative models/可逆显式隐含变量模型invertible explicit latent variable models): RealNVP
- 在VAEs背景下增加变分后验的灵活性
- 直接作为生成模型
- GAN和VAE都不允许新点概率密度的精确计算exact evaluation,且训练是有挑战的(由于一系列现象包括模式崩溃mode collapse,后验崩溃posterior collapse, 梯度消失vanishing gradients和训练不稳定training instability)
标准化流[6,7]
- 标准化流(continuous) normalizing flows: 深度生成模型
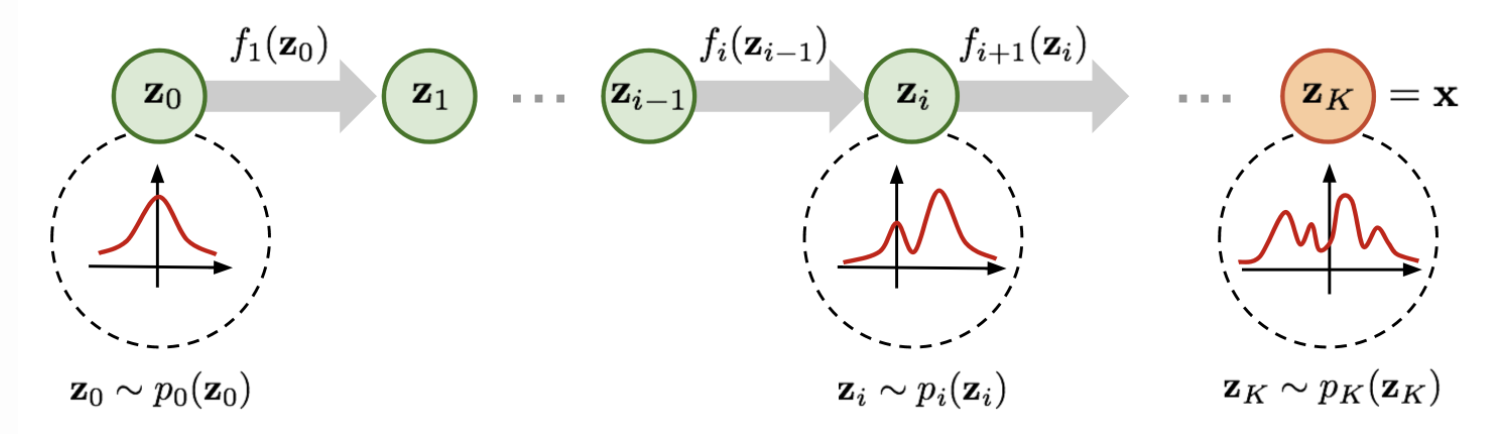
- 将一个简单的分布\(p_Z(\vec{z}^{(0)})\)(基密度base density,如标准高斯分布,可很容易计算其密度),通过应用一系列可逆、可微的映射\(f_1,f_2,...,f_K:R^d\to R^d\),变换成一个复杂的分布\(p_Z(\vec{z}^{(K)})=p_X(\vec{x})\)
- 变量变换公式
- 考虑一维随机变量的线性变换
- 令\(X\)服从均匀分布\((0,1)\),\(Y=f(X)=2X+1\),这里\(Y\)是\(X\)的一个简单仿射
affine(放缩scale和平移shift或translation)变换

- 对\(x\)和\(x+dx\)应用\(f\),则会得到\((y,y+dy)\)。为了保持二者的变化量相等,要使得\(p(x)dx=p(y)dy\)。但我们只关心改变的量,而不关心其方向。因此,\(p(y)=p(x)|dx/dy|\),等价于\(\log p(y)=\log p(x)+\log |dx/dy|\)
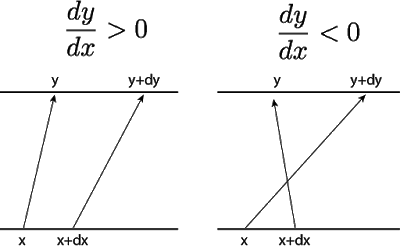
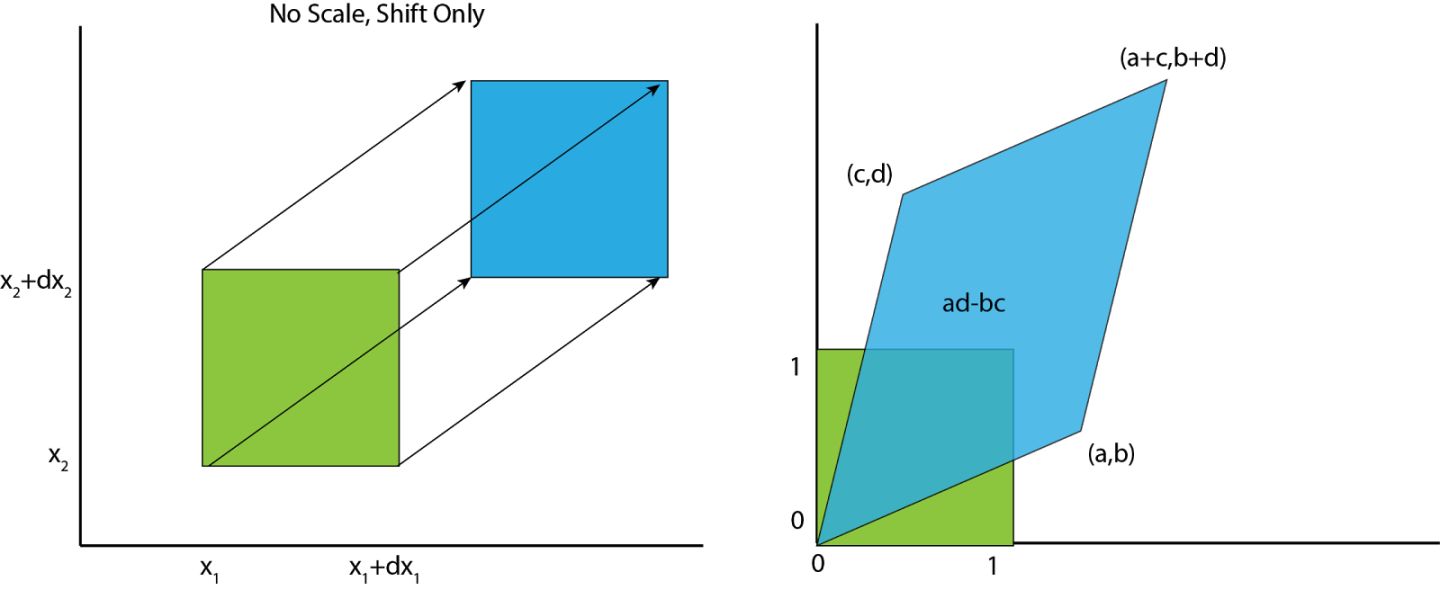
- 考虑多变量(multivariate)情况(如,两个变量)
- 将下图的正方形乘以矩阵\(\begin{bmatrix} a & b \\ c & d \\ \end{bmatrix}\),变换成一个面积为\(ad-bc\)的平行四边形,正是线性变换行列式
determinant的绝对值
volume的局部线性改变locally-linear change是\(|det(J(f^{-1}))|\)(标准化normalized因子),这里\(J(f^{-1})\)表示变换函数逆函数的雅可比矩阵Jacobian,是\(|dx/dy|\)的高维形式,形如\(J=\begin{bmatrix}
\frac{\partial f_1}{\partial x_1} & \cdots & \frac{\partial f_1}{\partial x_n} \\vdots & \ddots & \vdots \\frac{\partial f_m}{\partial x_1} & \cdots & \frac{\partial f_m}{\partial x_n} \\end{bmatrix}\)- 综上:
\[x=f(z) \p(x)=p(f^{-1}(x))|det(J(f^{-1}(x)))|=p(f^{-1}(x))|det(\frac{\partial f^{-1}}{\partial x})| \\log p(x)=\log p(f^{-1}(x))+\log |det(J(f^{-1}(x)))|
\]
- 使用变量变换公式the change-of-variables formula确定精确数据似然
- \(p_X(\vec{x})=p_Z(\vec{z}^{(K)})=p_Z(\vec{z}^{(0)})·\prod_{k=1}^{K}|det\frac{\partial \vec{z}^{(k-1)}}{\partial f_{k}(\vec{z}^{(k-1)})}|\),这里\(\vec{z}^{(k)}=f_{k}(\vec{z}^{(k-1)})\)
- 合成
compose多个流(仍是一个有效的标准化流)可得到更加复杂的分布,从而提升\(p_X(\vec x)\)的表达能力
- 其他形式的估计: 对抗损失adversarial losses可用于标准化流[4]
- 对于任意\(N\times N\)的雅可比矩阵,其行列式计算的最坏情况是\(O(N^3)\),所以有必要限制变换,使其逆具有对角或三角雅可比矩阵,这样就能以\(O(N)\)来计算,此时行列式为矩阵对角元素的乘积
- 设计标准化流使流的雅可比行列式1)容易进行逆运算;2)容易被计算
- 优点:强大的模型灵活性和非自回归生成non-autoregressive generation(generation speed/parallel generation)
- 用流定义的两个核心操作:
- 采样,即\(x\sim p(x)\):先从基密度\(z\sim p(z)\)中采样,然后应用
forward变换\(x=f(z)\)
- 密度估计,即给定一个已知的\(x\),计算\(p(x)\):先进行逆变换\(z=f^{-1}(x)\),然后计算基密度\(p(z)\),并乘以雅可比行列式(由一系列可逆变换引起的volume改变:每个变换的雅可比行列式绝对值的乘积)
- 密度估计和采样都有效[5]: 概率密度蒸馏Probability Density Distillation(使用最大化对数似然来训练逆函数,然后固定它并作为teacher网络。使用teacher网络以最小化采样点的分布与由teacher网络建模的数据分布之间的散度来训练student网络,即forward函数)
- 两个任务:变分推断和密度估计
- 变分推断:引入近似后验approximate posterior;最大化ELBO,但梯度计算不直接not straightforward;使用标准化流重参数化reparametrize近似后验;只能计算采样数据点的似然
- 流变换
- 具体例子:
- planar/radial flows[26]和IAF用于变分推断,因为它们只能计算自己样本的密度,而不能计算外部提供的数据点的密度
- NICE[25]、RealNVP[8]和MAF[9]用于密度估计
- Glow[10]使用\(1\times 1\)卷积来执行变换
- 自回归流
- MAF(Masked Autoregressive Flow)和IAF(Inverse Autoregressive Flow)
- MAF: \(\vec \mu\)和\(\vec \alpha\)是\(\vec x\)的自回归函数,\(
\mu_i=f_{\mu_i}(\vec x_{1:i-1}) \\alpha_i=f_{\alpha_i}(\vec x_{1:i-1})\)
- IAF: \(\vec \mu\)和\(\vec \alpha\)是\(\vec z\)的自回归函数, \(
\mu_i=f_{\mu_i}(\vec z_{1:i-1}) \\alpha_i=f_{\alpha_i}(\vec z_{1:i-1})\)
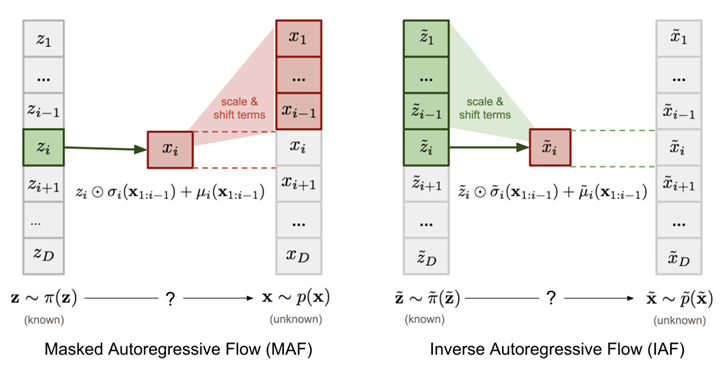

- 结构上的不同使两者具有不同的计算
trade-offs:
- 1)MAF能够通过模型经一个
pass计算任意数据\(x\)的密度\(p(x)\),但采样需要执行D(数据维数)个顺序passes
- 2)IAF能够经一个
pass生成样本和计算它们的密度,但计算一个外部提供的数据点\(x\)的密度\(p(x)\)需要D个passes来寻找和\(x\)相关的\(z\)
- 3)MAF和IAF编码不同的inductive biases,这会阻碍MAF和IAF的泛化能力
- 自回归流的雅可比矩阵是下三角矩阵,所以其行列式是其对角线元素的乘积:\(|det(\frac{\partial f^{-1}}{\partial x})|=exp(-\sum_i\alpha_i)\)
- 使用
masking执行函数集合\(\{f_{\mu_i}, f_{\alpha_i}\}\)
- MADE:
feedforward网络,以\(x\)为输入,经单个forward pass输出\(\mu_i\)和\(\alpha_i\)。通过将MADE的权重矩阵与适当构造的二进制masks相乘来实现自回归属性。使用具有高斯分布的MADE作为流的building layer或component layer
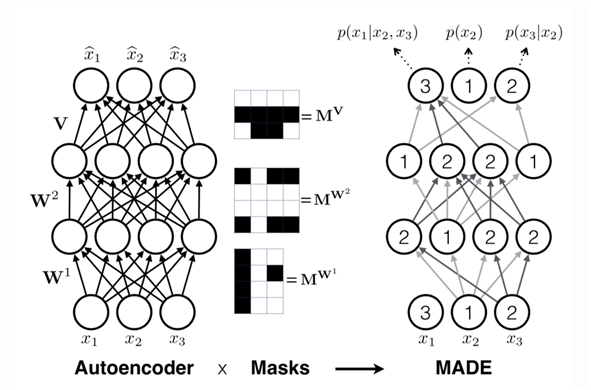
- 没有
masks时:\(
h^0=x \\
h^l=activation^l(W^lh^{l-1}+b^l) \\hat{x}=\sigma (Vh^L+c)\)
- 有
masks时:每个隐含结点被赋予一个值在[1, D-1]之间的整数,对于第l层的第k个单元,这个整数记作\(m_k^l\)。二元mask矩阵则根据层之间两个结点对应的整数确定,输入层和隐含层、隐含层和隐含层之间的masks要求前一层结点的整数值要小于等于后一层结点的整数值;隐含层和输出层之间的masks要求前一层结点的整数值要小于后一层结点的整数值:
\[h^0=x \\
h^l=activation^l((W^l\odot M^{W^l})h^{l-1}+b^l) \\hat{x}=\sigma ((V\odot M^V)h^L+c) \M_{k^{‘},k}^{W^l}= \begin{cases}
1, & \text{if $m_{k^{‘}}^l \geq m_k^{l-1}$} \0, & \text{otherwise}
\end{cases} \M_{d,k}^{V}= \begin{cases}
1, & \text{if $d > m_k^{L}$} \0, & \text{otherwise}
\end{cases}\]
- 二部
bipartite流
- 非线性变换输入的子集
- RealNVP(real-valued non-volume preserving)
- 二部流不如自回归流的表达能力强,因为变量的一个子集没有进行变换。但它可快速进行
forward和inverse计算(生成数据和估计密度都只需要一个forward pass),使其适合生成建模(需要快速生成)
- 耦合层是MAF和IAF中使用的自回归变换的特例。在MAF中,使得\(\mu_i=\alpha_i=0 \quad for \quad i \leq d;\quad \mu_i和\alpha_i只是x_{1:d}的函数for \quad i>d\)。在IAF中,使得\(\mu_i=\alpha_i=0 \quad for \quad i \leq d;\quad \mu_i和\alpha_i只z_{1:d}的函数for \quad i>d\)
- NICE(non-linear independent components estimation): RealNVP的先驱
predecessor。其变换层是additive耦合层,即没有放缩的仿射层,\(
x_{1:d}=z_{1:d} \x_{d+1:D}=z_{d+1:D}+m(z_{1:d})\z_{1:d}=x_{1:d} \z_{d+1:D}=x_{d+1:D}-m(x_{1:d})\)
- 叠加流(Layered Flow)
- 每个流编码一个可逆函数,该函数具有一个可线性计算的雅可比行列式(a linearly computable Jacobian determinant)
- 在函数合成下,可逆性是闭合的(invertibility is closed under function composition)
- 雅可比行列式可分解(factorize)
- 通过叠加流并改变每一层的依赖顺序,更灵活的分布可被创建
- 改变层之间的顺序允许所有的\(x_d‘s\)或\(z_d‘s\)去和每一层交互
- 逆转(reversing)或shuffling依赖的顺序
- 堆叠多层流(stacking multiple layers of flows)(multilayer flow): 增加标准化流的建模灵活性
- 流的改进:Flow++[12]
标准化流的应用
- 推广到非欧空间
- 流形上的流
- 离散分布/离散随机变量:建模离散数据/discrete data(events/sequences)
- 离散数据
- ordinal data如图像,整数代表量化值(quantized values)
- nomial/categorical data没有本质上的顺序且具有复杂和隐含的关系(如词之间的同义synonymy), 如文本/语言(词作为categorical/one-hot变量)、集合、图
- 将连续标准化流应用于离散数据会导致不想要的密度模型(任意高似然会落在特定值上)(离散数据点在一个连续分布中代表delta peaks)(产生一个降级解degenerate solution,将所有概率落在离散数据点上)
- 解决这个问题的常见方法是先通过一个“去量化dequantization”过程将离散数据分布转换成连续分布,然后使用连续密度模型建模得到的连续分布。可分为均匀去量化uniform dequantization和变分去量化variational dequantization[12]
- 使用去量化(给每个值添加一个小的噪声: \(v=x+u,u\in [0,1]^D\),其中x是整数,从v到x的逆向映射:为每个元素\(v_i\)找到the next lower whole number)可将离散数据映射到连续空间中,但不适用于类数据(值表示本质上没有顺序的类)。将类看作整数来进行去量化会使数据偏向bias于不存在的顺序
- 去量化表示dequantized representation \(p_{model}(v)\) 约束lower-bounds建模好的离散分布\(P_{model}(x)\)的下界,下界为\(E_{x\sim P_{data}}[logP_{model}(x)]\ge E_{x\sim P_{data}}E_{u\sim q(\cdot|x)}[log\frac{p_{model}(v)}{q(u|x)}]\),\(q(u|x)\)为去量化分布dequantization distribution,可为均匀uniform(忽略x的依赖)或通过第二个标准化流被学习(variational dequantization)
- 两个角度解决建模离散数据问题:1)修改变量变换公式change-of-variables formula,使其应用于离散变量[13,14];2)利用变分推断(variational dequantization)将离散变量映射到连续空间(隐含空间)中,对连续空间中的变量应用流模型[15,16,17]
- 离散流[13]:变量变换公式为\(p_{Y}(\vec{y})=p_{Z}(f^{-1}(\vec{y}))\),没有雅可比项;对于离散变量函数的反向传播,使用straight-through梯度估计器[24]。但这种方法无法扩展到具有大量元素的分布
- 整数离散流[14]:利用加性耦合层建模\(Z_D\)上的双射
- 隐含流[15]: 基于VAE的生成模型;联合学习隐含空间中基于标准化流的分布和一个到可观测离散空间的随机映射,同时要求基于流的分布要高度多峰,为此提出了几种标准化流架构来最大化模型灵活性。实验考虑常见的离散序列任务,包括character-level字符建模和复调音乐生成;结果表明基于自回归流的模型可以匹配自回归基线的性能,基于非自回归流的模型可以一个性能的损失来提高生成速度。基于encoder-decoder框架,encoder将离散变量映射到连续空间中(变分推断),这里假设离散变量在给定隐含变量的条件下相互独立,这样就将离散变量之间的序列动态关系以及离散变量本身的类别之间的关系放到连续空间中通过流来学习。decoder将隐含连续变量映射到离散空间中
- 类流[16]:考虑标准化流在类数据上的应用。将类数据在连续空间中的编码转换成变分推断问题,联合优化连续表示和模型似然
- 异常检测anomaly detection/新奇检测novelty detection[11]
- 将未见数据样本分成正常和异常,以一个正常数据的学习模型来评分
- 先学一个正常数据的模型,然后在推断时在已学习的模型下计算未见数据的新奇分数,最后根据一个学习到的决策边界boundary标注数据样本
- 可看成是one-class分类任务
- 在训练期间不需要异常数据,这对于少或无异常数据的情况是重要的,因为获取这样的数据很难且costly
- 由于可逆性,流模型可通过计算未见样本在已学习到的分布下的精确似然来对这些样本进行评分
- 可用于时间序列的异常检测
文本与标准化流
- 最直接的应用方式是在字符或词汇表上定义离散流,如离散流[13]中显示了字符级别语言建模的性能与RNNs相当,但具有更快生成运行时间。另一个可选方法应用更广泛,使用离散似然但连续的隐含空间定义一个隐含变量模型,之后标准化流可如往常一样在隐含空间上被定义。例如隐含流[15]用于字符级别语言建模。此外,[18-22]在词嵌入的连续空间上定义标准化流,作为翻译、句法syntactic结构、句法分析parsing模型的子组件
- 涉及任务:语言建模等
离散标准化流[13]
基于去量化的标准化流[15-17]
基于文本嵌入的标准化流[18-22]
参考文献
- [1] 2014 | Generative Adversarial Nets | Ian J. Goodfellow et al.
- [2] 2014 | Auto-encoding variational bayes | Diederik P. Kingma and Max Welling
- [3] 2021 | Deep Generative Modelling: A Comparative Review of VAEs, GANs, Normalizing Flows, Energy-Based and Autoregressive Models | Sam Bond-Taylor et al.
- [4] 2018 | Flow-GAN: Combining Maximum Likelihood and Adversarial Learning in Generative Models | Aditya Grover et al.
- [5] 2017 | Parallel wavenet: Fast high-fidelity speech synthesis | van den Oord et al.
- [6] 2019 | Normalizing Flows: An Introduction and Review of Current Methods | Ivan Kobyzev et al.
- [7] 2019 | Normalizing Flows for Probabilistic Modeling and Inference | George Papamakarios et al.
- [8] 2016 | Density estimation using real nvp | Laurent Dinh et al.
- [9] 2017 | Masked autoregressive flow for density estimation | George Papamakarios et al.
- [10] 2018 | Glow: Generative flow with invertible 1x1 convolutions | Diederik P. Kingma and Prafulla Dhariwal
- [11] 2019 | Normalizing flows for novelty detection in industrial time series data | Maximilian Schmidt and Marko Simic
- [12] 2019 | Flow++: Improving flow-based generative models with variational dequantization and architecture design | Jonathan Ho et al.
- [13] 2019 | Discrete Flows: Invertible Generative Models of Discrete Data | Dustin Tran et al.
- [14] 2019 | Integer discrete flows and lossless compression | Emiel Hoogeboom et al.
- [15] 2019 | Latent Normalizing Flows for Discrete Sequences | Zachary M. Ziegler and Alexander M. Rush
- [16] 2020 | Categorical Normalizing Flows via Continuous Transformations | Phillip Lippe and Efstratios Gavves
- [17] 2019 | Riemannian Normalizing Flow on Variational Wasserstein Autoencoder for Text Modeling | Prince Zizhuang Wang and William Yang Wang
- [18] 2019 | Density matching for bilingual word embedding | Chunting Zhou et al.
- [19] 2018 | Unsupervised learning of syntactic structure with invertible neural projections | Junxian He et al.
- [20] 2019 | Un-supervised learning of PCFGs with normalizing flow | Lifeng Jin et al.
- [21] 2020 | On the Sentence Embeddings from Pre-trained Language Models | Bohan Li et al.
- [22] 2020 | Text Style Transfer via Learning Style Instance Supported Latent Space | Xiaoyuan Yi et al.
- [23] 2019 | Self-Attentive, Multi-Context One-Class Classification for Unsupervised Anomaly Detection on Text | Lukas Ruff et al.
- [24] 2013 | Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation | Yoshua Bengio et al.
- [25] 2015 | NICE: Non-linear Independent Components Estimation | Laurent Dinh et al.
- [26] 2016 | Variational Inference with Normalizing Flows | Danilo Jimenez Rezende and Shakir Mohamed
其他资料
文本与标准化流
原文:https://www.cnblogs.com/yao1996/p/14661828.html