InfluxDB基本概念
1. Influxdb(时序数据库)是一个开源分布式时序、时间和指标数据库,使用Go语言编写,无需外部依赖。其设计目标是实现分布式和水平伸缩扩展,着力于高性能地查询与存储时序型数据,是InfluxData的核心产品。
2. Influxdb应用在性能监控,应用程序指标,物联网传感器数据和实时分析等的后端存储。
常见的使用场景:监控数据统计。比如每毫秒记录一下电脑内存的使用情况,进而根据统计的数据,利用图形化界面制作内润使用情况的折线图。
3. Influxdb完整的上下游产业还包括Chronograf、Telegraf、Kapacitor。
与传统关系型数据库(MySQL)基础概念区别
| 概念 | MySQL | InfluxDB |
| 数据库 | database | database |
| 表 | table | measurement |
| 列 | column | time(唯一主键)tags(带索引)、fields(不带索引) |
point(表中的一行数据)的数据结构由time(时间戳)、tags(标签)、fields(数据)三部分组成。
具体解释: time:数据记录的时间,是主索引,自动生成。
tags:各种有索引的属性。
fields:各种value值,没有索引的属性。
分类解释: tag set:不同的每组tag key和tag value的集合。
field set:每组field key和field value的集合。
retention policy: 数据存储策略(默认策略为autogen),InfluxDB没有删除数据操作,规定数据的保留时间来达到清除数据的目的。
series:相当于是InfluxDB中一些数据的集合,在同一个database中,retention policy、measurement、tag sets 完全相同的数据同属于一个 series,同一个 series 的数据在物理上会按照时间顺序排列存储在一起。
示例如下:
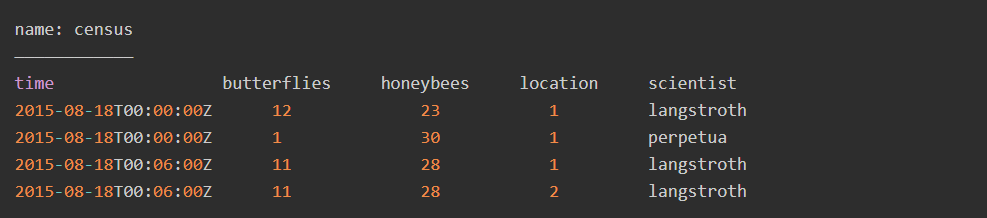
其中census是measurement,butterflies和honeybees是field key,location和scientist是tag key。示例中,有三个tag set。
注意事项:
保留策略(retention policy)
存储目录
influxdb的数据存储有三个目录,分别是meta、wal、data:
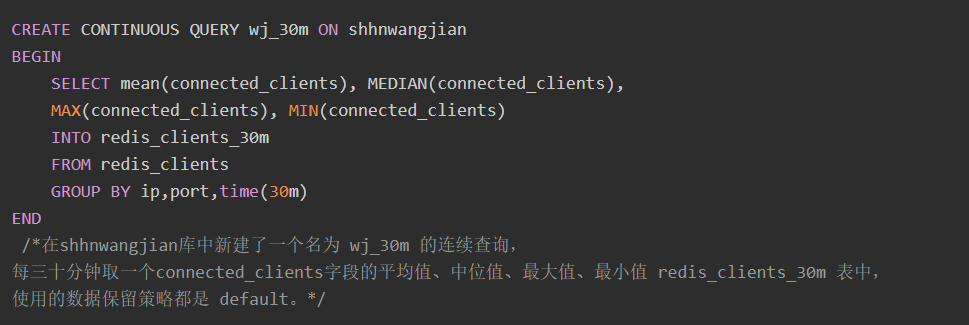
连续查询
influxdb的连续查询是在数据库中自动定时启动的一组语句,语句中必须包含SELECT等关键词。influxdb会将查询结果放在指定的数据表中。
目的:使用连续查询是最优的降低采样率的方式,连续查询和存储策略搭配使用将会大大降低InfluxDB的系统占用量。而且使用连续查询后,数据会存放到指定的数据表中,这样就为以后统计不同精度的数据提供了方便。
当数据超过保存策略里指定的时间之后就会被删除,但是这时候可能并不想数据被完全删掉,可以使用连续查询将数据聚合存储。
安装及启动
1. 可通过官网下载各平台版本:https://portal.influxdata.com/downloads/
以windows为例,选择对应平台的influxdb:https://dl.influxdata.com/influxdb/releases/influxdb-1.7.6_windows_amd64.zip
2. 下载后解压,得到 influxd.exe、influx.exe、influxdb.conf 等文件,data、meta、wal 是自己建立的文件夹:
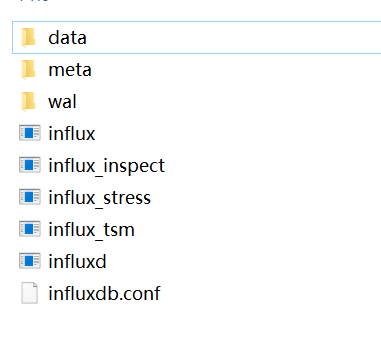
3. influx.exe 表示客户端,influxd.exe 表示服务端,influx_inspect.exe 表示查看工具,influx_stress.exe 表示压力测试工具,influx_tsm 表示数据库转换工具(将数据库从 b1 或 bz1 格式转换为 tsm1 格式),influxdb.conf 是配置文件,需要修改该文件,主要是三个路径修改:
[meta]
# Where the metadata/raft database is stored
dir = "C:/Install/influxdb-1.7.6-1/meta"
[data]
# The directory where the TSM storage engine stores TSM files.
#/var/lib/influxdb/data
dir = "C:/Install/influxdb-1.7.6-1/data"
# The directory where the TSM storage engine stores WAL files.
#/var/lib/influxdb/wal
wal-dir = "C:/Install/influxdb-1.7.6-1/wal"
4. 启动服务端 influxd.exe
5. 打开客户端 influx.exe
操作InfluxDB
可以通过SQL-like语言直接操作influxdb
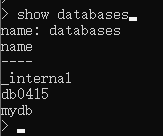
1. 库操作
show databases
create database db1
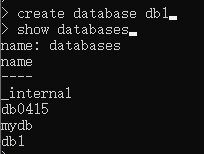
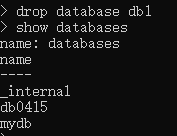
drop databse db1
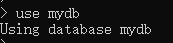
use mydb
2. 表操作
在InfluxDB当中,并没有表(table)这个概念,取而代之的是MEASUREMENTS,MEASUREMENTS的功能与传统数据库中的表一致,因此我们也可以将MEASUREMENTS称为InfluxDB中的表。
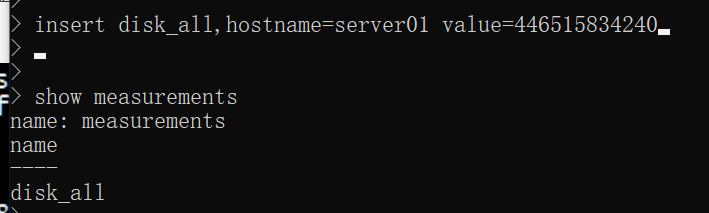
show measurements
InfluxDB中没有显式的新建表的语句,只能通过insert数据的方式来建立新表。
insert disk_all,hostname=server01 value=446515834240
其中disk_all就是表名,hostname是索引(tag),value=xx是记录值(field),记录值可以有多个,系统自带追加时间戳
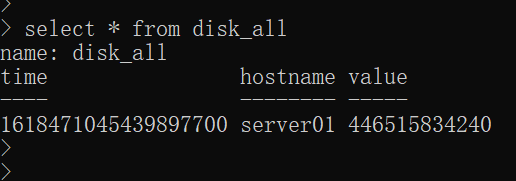
添加数据时,自己也可以写入时间戳
insert disk_all, hostname=server02 value=446515834240 1435362189575692181
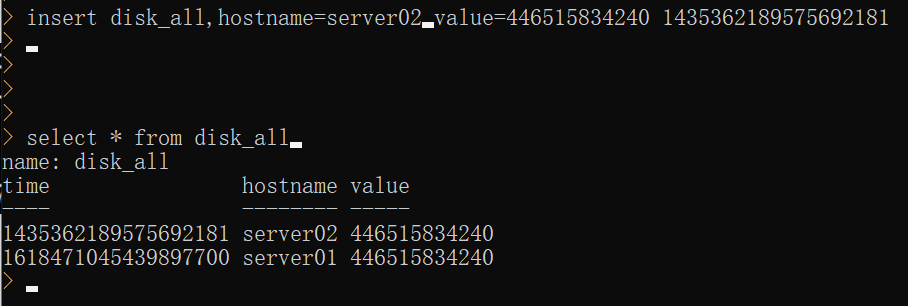
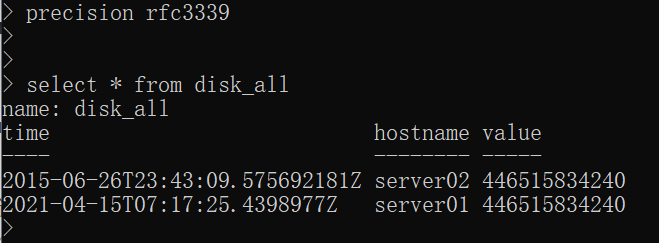
此时time默认显示为19位的ns级别的时间戳,查看不方便,通过如下命令更改:
precision rfc3339
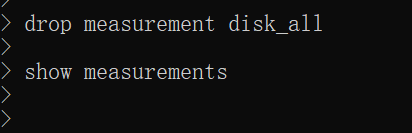
drop measurement disk_all
总结一下语句写法:
3. 数据保存策略(Retention Policies)
influxDB是没有提供直接删除数据记录的方法,但是提供数据保存策略,主要用于指定数据保留时间,超过指定时间,就删除这部分数据。
原文:https://www.cnblogs.com/wangzhilong/p/14665526.html