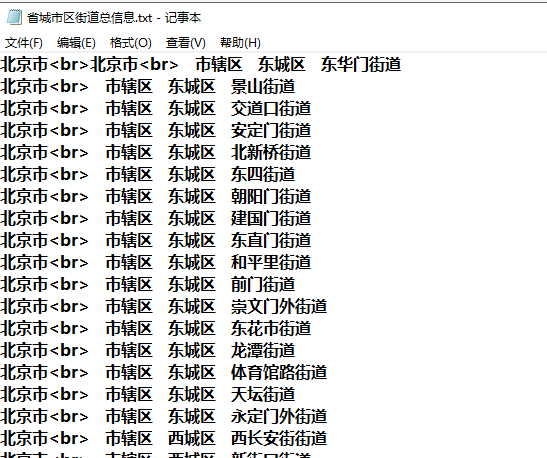
工作中,再次需要python,发现python用得好 ,真的可以节省很多人力,先说我的需求,需要做一个类似像支付宝添加收货地址时,选择地区的功能,需要详细到街道信息,也就是4级联动,如右图。首先需要的就是级联的数据,许是百度能力太差,找不到想要的,或者想要的需要积分才能下载,没有积分,只能干巴巴看着,好无奈,想起国家统计局有这个,以前在那里下载过,是一个表格,现在也忘记放哪里了,在它的官网找了好久,都没找到,后来是如何找到这个链接的也忘记了:http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2020/index.html,找到链接,第一个想到的就是pathon,于是决定靠自己丰衣足食。最后的代码如下,才70多行,咋一下不难,但也花费了我2天时间,脑袋有时候还是不够清晰。
1 # -*-coding:utf-8 -*-
2 import urllib2,urllib
3 from selenium import webdriver
4 import time
5 import sys
6 reload(sys)
7 sys.setdefaultencoding(‘utf-8‘)
8 import os
9
10 def writeData(tasklist):
11 conf = ‘ck.txt‘
12 file = open("%s/%s" % (os.path.abspath(os.path.dirname(__file__)), conf),"a+")
13 file.write(tasklist)
14 file.close()
15
16 chrome = webdriver.Chrome()
17 chrome.get("http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2020/index.html")
18 time.sleep(10)
19 href=[]
20 href1=[]
21 href2=[]
22 href3=[]
23 href4=[]
24 href5=[]
25 href6=[]
26 text=[]
27 text3=[]
28 text5=[]
29
30 href1=chrome.find_elements_by_css_selector(‘.provincetr td a‘)[30:]
31 # 省份和其对于的下一级链接
32 for q in href1:
33 href.append(q.get_attribute(‘href‘))
34 text.append(q.get_attribute(‘innerHTML‘))
35 for h,t in zip(href,text):
36 # if t.find("上海市")<0:
37 # continue
38 if h==‘‘:continue
39 chrome.get(h)
40 time.sleep(3)
41 writeData(t)
42 href2=chrome.find_elements_by_css_selector(".citytr :nth-child(2) a")
43 #城市和其对应的下一级链接
44 timer=0
45 while timer<len(href2):
46 q1=chrome.find_elements_by_css_selector(".citytr :nth-child(2) a")[timer]
47 timer+=1
48 href3=q1.get_attribute(‘href‘)
49 text3=q1.get_attribute(‘innerHTML‘)
50 if href3==‘‘:continue
51 chrome.get(href3)
52 time.sleep(3)
53 href4=chrome.find_elements_by_css_selector(".countytr :nth-child(2) a")
54 #区和其对应的下一级链接
55 timer7=0
56 while timer7<len(href4):
57 print timer7
58 print len(href4)
59 q2=chrome.find_elements_by_css_selector(".countytr :nth-child(2) a")[timer7]
60 timer7+=1
61 href5=q2.get_attribute(‘href‘)
62 text5=q2.get_attribute(‘innerHTML‘)
63 if href5==‘‘:continue
64 chrome.get(href5)
65 time.sleep(3)
66 href6=chrome.find_elements_by_css_selector(".towntr :nth-child(2) a")
67 #街道信息
68 timer6=0
69 while timer6<len(href6):
70 q3=chrome.find_elements_by_css_selector(".towntr :nth-child(2) a")[timer6]
71 timer6+=1
72 writeData(t+" "+text3+" "+text5+" "+q3.get_attribute(‘innerHTML‘)+"\n")
73 chrome.back()
74 chrome.back()
75 chrome.back()
76
下面说说我遇到的主要问题,记录下来,免得下次又踩坑。
1.用for in循环遍历,报错:element is not attached to the page document,发现是chrome.get打开另一个页面之后,再回来就会报这边错误,原来是页面刷新之后,需要重新获取一下元素,一开始我是用了3个for in 遍历的,发现不行,就改为了while,在while重新获取一次元素,获取元素依次增一。
2.爬到的数据有缺失,发现是变量timer,timer7,timer6,在每个while循环前,需要复位为0。
3.大概爬到三分一的时候,需要填入图片中的数字才可以继续打开页面,页面做了反爬,很多网站都会有所限制,接下来的爬取,很多时候需要人工干预,改变爬取的起点,让程序继续爬取剩下的数据
4,。我用的是txt保存爬到的数据,我一开始是打算用excel的,但是安装xlwt失败,报编码问题,安装包的时候,经常遇到这个问题,不知道如何解决。
爬完之后,得到的文件有2M多,的确是蛮大的。有5万多行呢。
原文:https://www.cnblogs.com/lulu-beibei/p/14668089.html