一、RocketMQ集群
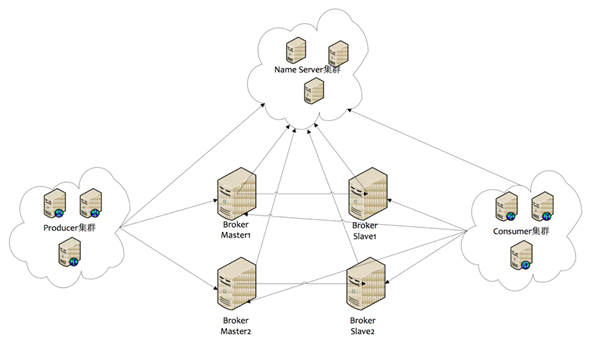
RocketMQ集群由于无法选主,所以当Master挂了以后,slave需要手动切换master。这一点不好
二、RocketMQ为什采用NameSr,而不是zk
ZK是CP,NameSr是AP。RocketMQ选择了高可用。
RocketMQ的集群思想与Kafka有很大区别,在Kafka中borker这个概念分为Master和slave,可以通过zk选主进行切换和高可用。RocketMQ中Master对应的Borker 和 slave对应的borker是搭建环境的时候指定好的,他不需要选举。从这里可以看出Kafka的核心思想是通过主从切换保证集群的高可用。而RocketMQ是通过故障转移保证集群的高可用。例如:当RocketMQ中某个masterBorker挂了,那本来该发送到这个borker中对应队列的消息,此时将会被发送到其他Master上(对于普通消息)。
三、RocketMQ的顺序消息
全局顺序:就是我希望所有的消息你都给我按序消费,对应这样的消息我们可以创建topic时只分配一个队列。这样就失去了高可用的,高吞吐量的效果。
局部顺序:这类顺序消息很常见,我们就是根据一定的算法将同类型的消息路由到同一个队列中。发送消息,要实现 MessageQueueSelector 该接口,重写select()方法,按照自己的算法将相同类别的消息发送大同一个Queue中。
消费端处理: 如何保证消费端顺序消费?
- MessageListenerOrderly(顺序消费):有序消费,同一队列的消息同一时刻只能一个线程消费,可保证消息在同一队列严格有序消费
- MessageListenerConcurrently(并发消费):如果是使用该方式,则需要把线程池改为单线程模式。
四、消息重试的原理与死信队列
Producer
- 如果是异步发送 那么重试次数只有1次
- 对于同步而言,超时异常也是不会再去重试。
- Product默认是2次;他是立即重试
- 发送超时,不会重试
Consumer:
- Consumer默认是16次
- Consumer是有一定时间间隔的。它照1S,5S,10S,30S,1M,2M····2H进行重试。
- Consumer在广播情况下重试失效
RocketMQ 规定,以下三种情况统一按照消费失败处理并会发起重试。
- 业务消费方返回 ConsumeConcurrentlyStatus.RECONSUME_LATER
- 业务消费方返回null
- 业务消费方主动/被动抛出异常
RocketMQ 消费失败后会将消息加入到重试队列(设置重试消息的TOPIC, 重试队列名称为:%RETRY%+consumergroup),如果当前消息的重试次数大于最大重试次数,那么就开始走死信队列。 跟重试消息一样,也是设置死信队列的TOPIC %DLQ%+ 实际的消费组 ,我们可以对死性对了进行处理。但是在实际工作中我们一般重试三次,如果还是失败也给borker返回成功,同时我们会将该消息记录下来,后期补偿。
注意:RocketMQ消息重试功能需要区分事务消息、顺序消息、与普通消息。
- 普通消息:该类型消息的重试,会触发故障转移,就是当第一次发送消息失败,重试发送会换一个borker。
- 顺序消息:该类型消息重试,不会触发故障转移,就是一直往同一个borker上发送。
五、如何保证消息零丢失
生产者:
- 同步发送: Producer 向 broker 发送消息,阻塞当前线程等待 broker 响应 发送结果。
- 异步发送: Producer 首先构建一个向 broker 发送消息的任务,把该任务提交给线程池,等执行完该任务时,回调用户自定义的回调函数,执行处理结果。
- Oneway发送: Oneway 方式只负责发送请求,不等待应答,Producer 只负责把请求发出去,而不处理响应结果。我们使用同步发送返送,并且捕获返回结果进行重试,可以减小消息发送丢失。
Conusmer:PushConsumer为了保证消息肯定消费成功,只有使用方明确表示消费成功,RocketMQ才会认为消息消费成功。中途断电,抛出异常等都不会认为成功——即都会重新投递。ConsumeConcurrentlyStatus.CONSUME_SUCCESS
brocker存储消息:采用同步刷盘模式,当刷盘成功后才返回producer投递消息成功。
六、如何保证消息的最终一致性
事务消息
- 发送方向 MQ 服务端发送消息。该消息为prepare消息,即消费者不可见。
- MQ Server 将消息持久化成功之后,向发送方 ACK 确认消息已经发送成功,此时消息为半消息。
- 发送方开始执行本地事务逻辑。发送方根据本地事务执行结果向 MQ Server 提交二次确认(Commit 或是 Rollback),MQ Server 收到Commit 状态则将半消息标记为可投递,订阅方最终将收到该消息;MQ Server 收到 Rollback 状态则删除半消息,订阅方将不会接受该消息。
- 在断网或者是应用重启的特殊情况下,上述步骤4提交的二次确认最终未到达 MQ Server,经过固定时间后MQ Server 将对该消息发起消息回查。发送方收到消息回查后,需要检查对应消息的本地事务执行的最终结果。发送方根据检查得到的本地事务的最终状态再次提交二次确认,MQ Server 仍按照步骤4对半消息进行操作。
Producer Group:标识发送同一类消息的Producer,通常发送逻辑一致。发送普通消息的时候,仅标识使用,并无特别用处。若事务消息,如果某条发送某条消息的producer-A宕机,使得事务消息一直处于PREPARED状态并超时,则broker会回查同一个group的其 他producer,确认这条消息应该commit还是rollback。但开源版本并不支持事务消息。
七、Broker是怎么保存数据的
RocketMQ主要的存储文件包括commitlog文件、consumequeue文件、indexfile文件。
Broker在收到消息之后,会把消息保存到commitlog的文件当中,而同时在分布式的存储当中,每个broker都会保存一部分topic的数据,同时,每个topic对应的messagequeue下都会生成consumequeue文件用于保存commitlog的物理位置偏移量offset,indexfile中会保存key和offset的对应关系。
ommitLog文件保存于${Rocket_Home}/store/commitlog目录中,从图中我们可以明显看出来文件名的偏移量,每个文件默认1G,写满后自动生成一个新的文件。

由于同一个topic的消息并不是连续的存储在commitlog中,消费者如果直接从commitlog获取消息效率非常低,所以通过consumequeue保存commitlog中消息的偏移量的物理地址,这样消费者在消费的时候先从consumequeue中根据偏移量定位到具体的commitlog物理文件,然后根据一定的规则(offset和文件大小取模)在commitlog中快速定位。

八、Master和Slave之间是怎么同步数据的呢?
而消息在master和slave之间的同步是根据raft协议来进行的:
- 在broker收到消息后,会被标记为uncommitted状态
- 然后会把消息发送给所有的slave
- slave在收到消息之后返回ack响应给master
- master在收到超过半数的ack之后,把消息标记为committed
- 发送committed消息给所有slave,slave也修改状态为committed
九、RocketMQ为什么速度快
是因为使用了顺序存储、Page Cache和异步刷盘。
我们在写入commitlog的时候是顺序写入的,这样比随机写入的性能就会提高很多
写入commitlog的时候并不是直接写入磁盘,而是先写入操作系统的PageCache
最后由操作系统异步将缓存中的数据刷到磁盘
RocketMQ
原文:https://www.cnblogs.com/jalja365/p/14673232.html