??“索引”类似一本书的目录(页码),通过目录(页码),让我们能快速找到想看的位置。对于一个DataFrame数据框,其中:
??源Excel文件index.xlsx:
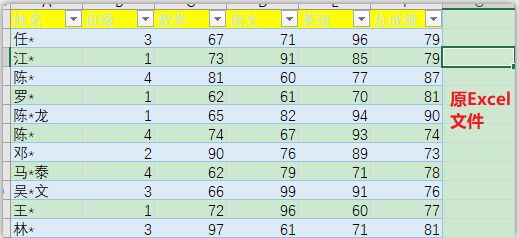
df = pd.read_excel(‘C:/Users/asus/Desktop/index.xlsx‘)
df
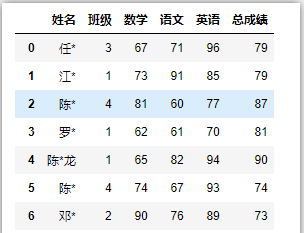
# 指定’姓名‘或’班级‘这一列为行索引
df = pd.read_excel(‘C:/Users/asus/Desktop/index.xlsx‘,index_col=‘姓名‘)
# df = pd.read_excel(‘C:/Users/asus/Desktop/index.xlsx‘,index_col=‘班级‘)
df
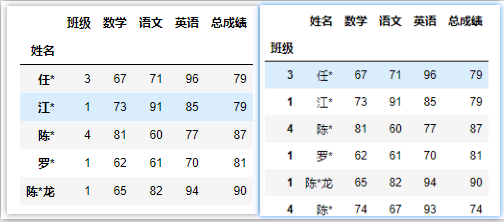
# 指定’班级‘、’姓名‘这两列为层级索引MultiIndex
df = pd.read_excel(‘C:/Users/asus/Desktop/index.xlsx‘,index_col=[1,0])
df
?也可以根据header参数指定哪行作为列名,或根据names参数自定义列名,具体见:https://www.cnblogs.com/xiaoshun-mjj/p/14538695.html
DataFrame.set_index(keys, drop=True, append=False,
inplace=False, verify_integrity=False)
参数说明:
# 导入数据时,未指定索引
df = pd.read_excel(‘C:/Users/asus/Desktop/index.xlsx‘)
df.set_index(‘姓名‘) # 设置姓名为索引
df.set_index([‘班级‘,‘姓名‘]) # 设置班级和姓名为索引
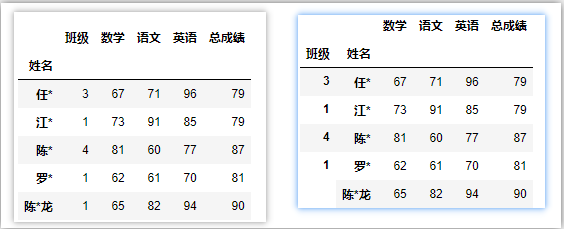
df.set_index(‘姓名‘,drop=False) # 保留原列
df.set_index(‘姓名‘,append=True) # 保留原索引
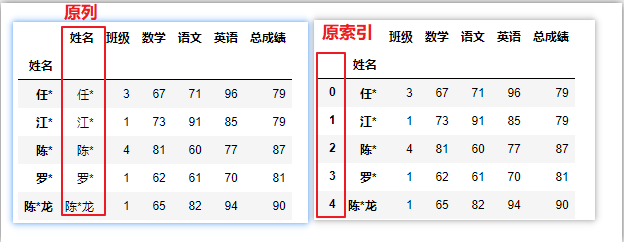
以df.index为例,也适用于 df.columns, 因为两者都是 index 对象
df = pd.read_excel(‘C:/Users/asus/Desktop/index.xlsx‘) # 导入数据时,未指定索引
df.set_index(‘姓名‘,drop=False,inplace=True) # 保留原列,对原数据生效
# 查看索引信息(值和类型,还有可能有名称)
df.columns
df.index

df.index.name # 行索引名称
df.index.dtype # 索引数据类型
df.index.shape # 形状
df.index.size # 元素数量,行记录条数
# df.columns.size
df.index.values # 索引的值,array 数组
# df.index.value_counts() # 去重统计
# df.index.values.tolist() # array 数组转换成列表list
df.index.is_unique # 判断是否有重复,业务上原则一般不会重复,有重复返回False
一样适用于 df.columns。
df.columns.isin([‘姓名‘,‘语文‘]) # 是否存在,快速查看是否有该列名或行

df.index.nunique() # 不重复值的数量
df.index.sort_values(ascending=False) # 排序,倒序
df.index.to_frame(index=False) # 转成 DataFrame
df.index.unique() # 去重
df.index.value_counts() # 去重分组统计
df.index.where(df.index==‘林*‘) # 筛选,查看是否由该行记录
df.index.max() # 最大值
df.index.map(lambda x:x+‘_‘) # 批量处理索引

列可以变成索引,索引也能回复成列。
DataFrame.reset_index(level=None, drop=False,
inplace=False, col_level=0, col_fill=‘‘)
参数说明:
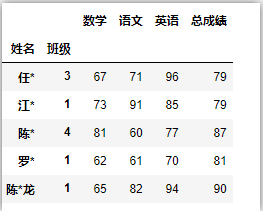
df = pd.read_excel(‘C:/Users/asus/Desktop/index.xlsx‘) # 导入数据时,未指定索引
df = df.set_index([‘姓名‘,‘班级‘]) # 设置MultiIndex
df
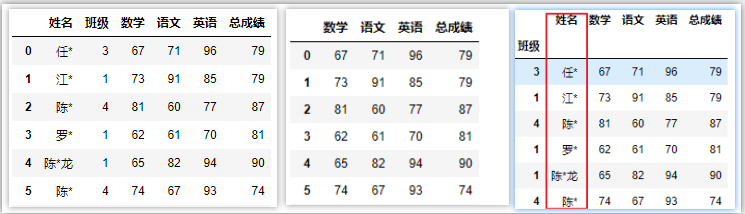
df.reset_index() # 移除所有层级索引,并把索引还原成列
df.reset_index(drop=True) # 移除所有层级索引,舍弃原索引
df.reset_index([‘姓名‘]) # 只把姓名这一层索引还原层列
# 一对一对应修改
df.rename(columns={‘数学‘: ‘maths‘})
# 也可以通过一些函数进行批量修改
df.rename(lambda x:‘t_‘ + x, axis=1) # 通过lambda表达式批量给列名加前缀
原文:https://www.cnblogs.com/xiaoshun-mjj/p/14679408.html