<thread>库是C++11标准新引进的多线程库,包含线程类及其相关函数实现。
常见的创建线程的方法可分为两类:
thread th(func, arg1, arg2, ...)thread th(&class::func, &obj, arg1, ...)线程的运行也有两种方法:
thread::join() 主线程等待该线程结束才会结束。thread::detach() 主线程将该线程分离,不会等待该线程结束,需要注意临时变量悬空问题。注:C++还有异步线程future,本文不涉及。
mutex(mutual exclusion) 是C++多线程中的互斥量,一个互斥量一次只能被一个线程独占。互斥量是解决多线程互斥问题的基础。在编程时需要控制对一部分资源访问的场景中,可设置一个mutex,只有获取了这个mutex(相当于是一个通行证,一种条件),才能继续往下运行。
mutex有两个基本操作:
mutex::lock()mutex::unlock()笔者在理解多线程常说的锁概念时,认为在C++中表现为对mutex的独占,即占有了mutex = mutex::lock() = 获取了锁,以下讲解中三者概念等同。
unique_lock包装了mutex,支持自动/手动加解锁,提供了相关便利的函数;并且mutex是无法直接交付给条件变量的,必须通过unique_lock的包装。
condition_variable是C++多线程中的同步工具,可以自动判断相关条件决定是否阻塞当前线程,或唤醒其他已阻塞的线程。基于此,可以设定相关条件以维持一定的线程运行顺序。condition_variable阻塞效率要高于mutex的轮询,因为轮询需要不断判断消耗CPU资源。
常用的函数有:
condition_variable::wait(unique_lock<mutex>, bool func)condition_variable::notify_one()condition_variable::notify_all()对于多线程问题,笔者一般将其分为以下三个模块,按顺序依次为:
编写一个多线程程序,轮流打印出ABC三个字符
相信多数人无论是在学习过程中还是面试过程都碰到过这个简单又经典的问题,既容易理解,又包含一个完整的同步问题处理步骤。
下图是笔者的“三模块”分析。
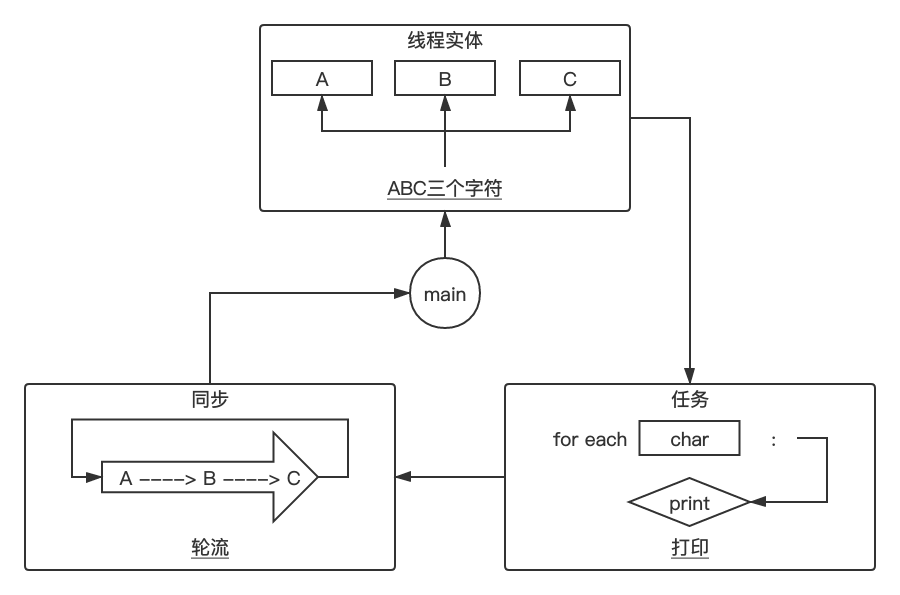
代码部分依次分析任务、同步、线程实体三模块进行编写。
void print_char(char ch, int times) // 打印times次字符ch
{
string name("Thread");
name += ch;
for (int i = 0; i < times; i++) {
cout << name << ‘ ‘
<< "id " << gettid() % 100 << ‘ ‘ /* linux unistd.h 获取线程id */
<< ch << endl;
}
}
一段很朴实的代码...
int main()
{
vector<thread> pool;
pool.emplace_back(thread(print_char,‘A‘, 3));
pool.emplace_back(thread(print_char,‘B‘, 3));
pool.emplace_back(thread(print_char,‘C‘, 3));
for (auto &th : pool) { // thread不可拷贝,使用引用访问
th.join();
}
cout << "end" << endl;
return 0;
}
代码编写到这已经可以打印出ABC字符了,不过打印是混乱的,不符合“依次ABC”的要求,因此还需进一步的时序控制——同步代码编写。
要保证顺序,那么ABC三个线程必定需要访问同一个信号才知道自己是否可以输出,则需要mutex防止冲突和condition_variable判断条件(顺序)。
condition_variable bell; // “钟声响起之时,权杖降临之日”
mutex wand; // “执杖者”拥有打印之力
两者为全局变量以便访问。
在进行时序约束之前,需要设定一个固定的顺序,利用to_print函数确定顺序。
bool to_print(char cur) // 字符cur是否应当打印
{
static char p = ‘A‘; // 静态单例,标识要打印的字符
if (cur != p) { // 不应打印字符cur
return false;
}
switch (p) { // 设定顺序
case ‘A‘:
p = ‘B‘;
break;
case ‘B‘:
p = ‘C‘;
break;
case ‘C‘:
p = ‘A‘;
break;
default:
cout << "strange" << endl;
}
return true;
}
每次打印字符前,需要判断一下是否应该本线程执行,应在print_char增加时序约束。
void print_char(char ch, int times)
{
string name("Thread");
name += ch;
unique_lock<mutex> plk(wand, defer_lock); // 获取mutex信息,延迟手动上锁
for (int i = 0; i < times; i++) {
plk.lock(); // 第一关卡:尝试占有mutex
bell.wait(plk, [ch] { /* 第二关卡:已经获取mutex,判断是否是正确的线程获取 */
return to_print(ch);
});
cout << name << ‘ ‘
<< "id " << gettid() % 100 << ‘ ‘
<< ch << endl;
plk.unlock(); // 达成目的,及时让出mutex,以便其他线程继续运行
bell.notify_all(); // 通知所有阻塞的线程,“快准备占用,我已经让出mutex了”
}
}
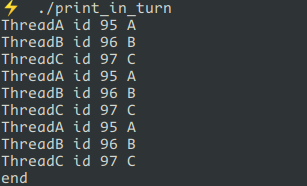
最终在终端得到输出:
ThreadA id 20 A
ThreadB id 21 B
ThreadC id 22 C
ThreadA id 20 A
ThreadB id 21 B
ThreadC id 22 C
ThreadA id 20 A
ThreadB id 21 B
ThreadC id 22 C
end

1 #include<condition_variable> 2 #include<iostream> 3 #include<thread> 4 #include<unistd.h> 5 #include<vector> 6 7 using namespace std; 8 9 mutex wand; 10 condition_variable bell; 11 12 bool to_print(char cur) 13 { 14 static char p = ‘A‘; 15 16 if (cur != p) { 17 return false; 18 } 19 20 switch (p) { 21 case ‘A‘: 22 p = ‘B‘; 23 break; 24 case ‘B‘: 25 p = ‘C‘; 26 break; 27 case ‘C‘: 28 p = ‘A‘; 29 break; 30 default: 31 cout << "strange" << endl; 32 } 33 34 return true; 35 } 36 37 void print_char(char ch, int times) 38 { 39 string name("Thread"); 40 name += ch; 41 unique_lock<mutex> plk(wand, defer_lock); 42 for (int i = 0; i < times; i++) { 43 plk.lock(); 44 bell.wait(plk, [ch] { 45 return to_print(ch); 46 }); 47 cout << name << ‘ ‘ 48 << "id " << gettid() % 100 << ‘ ‘ 49 << ch << endl; 50 plk.unlock(); 51 bell.notify_all(); 52 } 53 } 54 55 int main() 56 { 57 vector<thread> pool; 58 59 pool.emplace_back(thread(print_char,‘A‘, 3)); 60 pool.emplace_back(thread(print_char,‘B‘, 3)); 61 pool.emplace_back(thread(print_char,‘C‘, 3)); 62 63 for (auto &th : pool) { 64 th.join(); 65 } 66 67 68 cout << "end" << endl; 69 return 0; 70 }
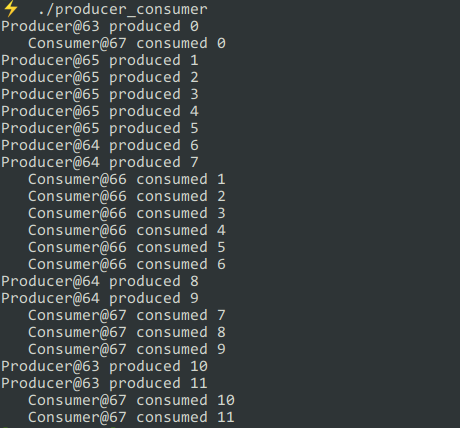
1 #include<condition_variable> 2 #include<queue> 3 #include<iostream> 4 #include<thread> 5 #include<unistd.h> 6 7 using namespace std; 8 9 struct Warehouse { 10 int cap; 11 queue<int> space; 12 Warehouse(int c) : cap(c) {}; 13 bool full() { 14 return space.size() == cap; 15 }; 16 bool empty() { 17 return space.empty(); 18 }; 19 int push(int i) { 20 space.emplace(i); 21 return i; 22 }; 23 int pop() { 24 int first = space.front(); 25 space.pop(); 26 return first; 27 }; 28 }; 29 30 class Role { 31 protected: 32 thread badge; 33 unique_lock<mutex> lk; 34 condition_variable &bell; 35 Warehouse &warehouse; 36 int piece; 37 38 public: 39 Role(mutex &m, condition_variable &cv, Warehouse &w, int n) 40 : bell(cv), warehouse(w), piece(n) { 41 badge = thread(&Role::work, this); 42 lk = unique_lock<mutex>(m, defer_lock); 43 }; 44 void run() { 45 badge.join(); 46 } 47 virtual void work() {}; 48 }; 49 50 class Producer : public Role { 51 private: 52 static int no; 53 54 public: 55 using Role::Role; 56 void work() { 57 for (int i = 0; i < piece; i++) { 58 lk.lock(); 59 bell.wait(lk, [this] { 60 return !this->warehouse.full(); 61 }); 62 cout << "Producer@" << gettid() % 100 63 << " produced " << warehouse.push(no++) << endl; 64 lk.unlock(); 65 bell.notify_all(); 66 } 67 }; 68 }; 69 70 int Producer::no = 0; 71 72 class Consumer : public Role { 73 public: 74 using Role::Role; 75 void work() { 76 for (int i = 0; i < piece; i++) { 77 lk.lock(); 78 bell.wait(lk, [this] { 79 return !this->warehouse.empty(); 80 }); 81 cout << " Consumer@" << gettid() % 100 82 << " consumed " << warehouse.pop() << endl; 83 lk.unlock(); 84 bell.notify_all(); 85 } 86 }; 87 }; 88 89 int main() 90 { 91 mutex m; 92 condition_variable cv; 93 Warehouse wh(8); 94 95 Producer p1(m, cv, wh, 3); 96 Producer p2(m, cv, wh, 4); 97 Producer p3(m, cv, wh, 5); 98 99 Consumer c1(m, cv, wh, 6); 100 Consumer c2(m, cv, wh, 6); 101 102 p1.run(); 103 p2.run(); 104 p3.run(); 105 106 c1.run(); 107 c2.run(); 108 109 return 0; 110 }
在轮流打印和生产者——消费者模型中,条件变量都采用notify_all()唤醒所有线程。已知notify_all()会使所有线程唤醒从而产生锁争用,不仅相比与notify_one()性能较低,而且程序中一次只能允许一个线程继续执行,那为什么不用notify_one()呢?
实践是检验真理的唯一标准。笔者尝试之后,发现程序可能会出现一直挂起,无法结束的现象,一个最大的可能性是所有线程都被阻塞了。为什么会发生这种情况?笔者做了以下的调研分析。
condition_variable::wait(...)的参考手册上表明wait()会将当前线程加入到一个名为*this上的阻塞列表中。而在所用的函数中,只有notify_one()/notify_all()会将阻塞移除阻塞列表。
纵使notify_one()效率高,但在计算机编程乃至世界中一个亘古不变的真理就是trade-off,有得必有失。notify_one()只能唤醒一个不确定的阻塞线程可能会导致一种结果——本线程唤醒的线程不符合条件。被唤醒的线程抵达不了临界区(可理解为一次只能进入一个线程的代码区域)后方,无法再唤醒/解放其他线程;本线程释放锁后又争用到锁,但也不满足条件,被阻塞,导致因此全员被阻塞。
按照以上分析,套用本问题,不妨此时应该打印C,一种阻塞的流程如下:
for的下一轮,争用到锁,但也不满足条件,也被阻塞,那么全员被阻塞,程序无法运行。生产者-消费者问题与之相似。不妨设当前生产者将库存填满了,唤醒了一个生产者线程,但随之被阻塞;本线程又争用到锁,然而不满足条件,又被阻塞。最后全员被阻塞,程序无法继续运行。
原文:https://www.cnblogs.com/gantianciyu/p/14678739.html
