TransVG: End-to-End Visual Grounding with Transformers
2021-04-20 10:37:54
Code: Not available yet
1. Background and Motivation:
本文提出了首个基于 Transformer 模型的 Visual Grounding 算法框架,从下图可以看到,主要包含三个模块:language-Transformer,Image-Transformer,以及Vis-Lang-Transformer。作者的实验表明结构化的融合模块并不是必须的,因为简单地进行 Transformer 编码层的堆叠就可以得到较好的效果。因为,attention layer 已经建模了模态内和模态间的对应关系,尽管不用任何特定的融合模块。此外,作者也发现直接回归矩形框位置,比之前任何一种方法,效果都要好。
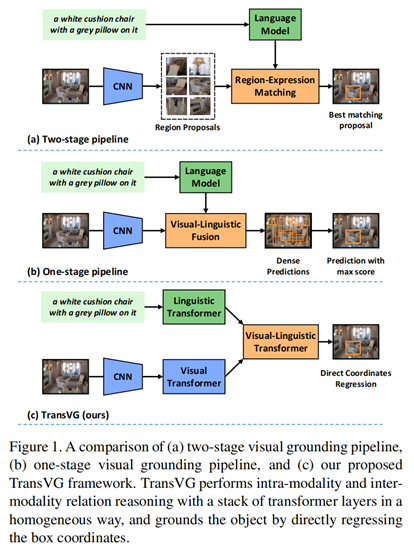
2. Approach:
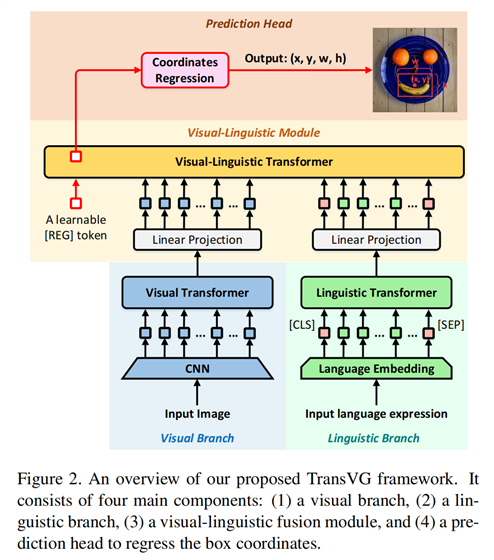
2.1.
==
TransVG: End-to-End Visual Grounding with Transformers
原文:https://www.cnblogs.com/wangxiaocvpr/p/14680131.html