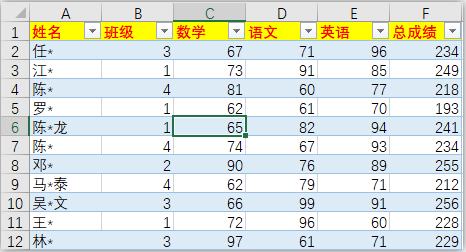
除了对原始数据进行简单的统计计算外,有时候我们还需要对数据进行一定变化再做计算。pandas自带一些基础函数支持这些变化。源Excel文件maths_pro.xlsx:
df.shift(periods=1, freq=None, axis=0)
参数说明:
df = pd.read_excel(r‘C:/Users/asus/Desktop/Python/maths_pro.xlsx‘)
df
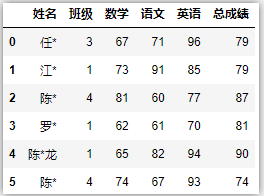
df.shift() # 默认数据向下偏移一个单位
# 设置轴向,向右偏移一个单位,数据类型不匹配,也会设置为NaN值
df.shift(axis=1)
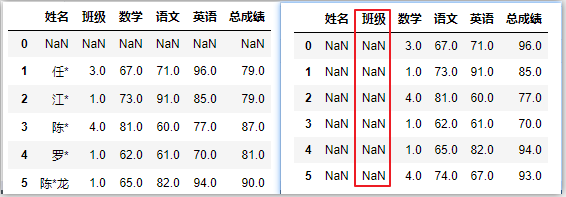
df.shift(periods=-2) # 向上偏移两个单位
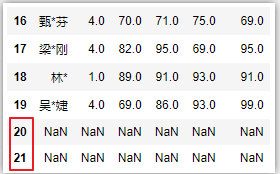
df.diff(periods=1, axis=0)
做位移差操作(不仅位移而且还做了减操作)。用在一个序列性数据中上一个数据和下一个数据之前的差值,增量计算。
df[‘语文‘].diff()
# 等价
df[‘语文‘]-df[‘语文‘].shift()
参考文章:https://zhuanlan.zhihu.com/p/87593543(分组排名)
df.rank(axis=0, method=‘average‘, numeric_only=None,
na_option=‘keep‘, ascending=True, pct=False)
功能:沿着某个轴(0或者1)计算对象的排名
返回值:以Series或者DataFrame的类型返回数据的排名(哪个类型调用返回哪个类型)
参数说明:
# 对语文成绩降序排序,取其中三列
df = df.sort_values(by=‘语文‘)[[‘姓名‘,‘语文‘]]
df
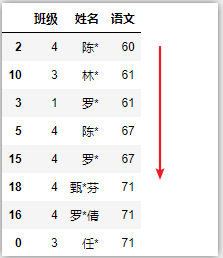
# 5种不同排序方法的比较
df[‘first‘] = df[‘语文‘].rank(method=‘first‘)
df[‘average‘] = df[‘语文‘].rank()
df[‘max‘] = df[‘语文‘].rank(method=‘max‘)
df[‘min‘] = df[‘语文‘].rank(method=‘min‘)
df[‘dense‘] = df[‘语文‘].rank(method=‘dense‘)
df[‘pct‘] = df[‘语文‘].rank(pct=True)
df
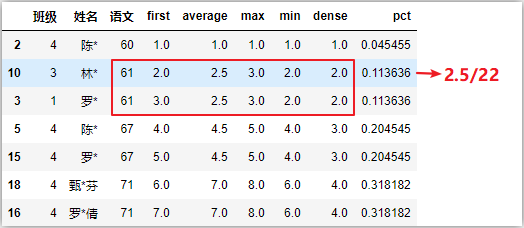
分组排序:
df = df.sort_values(by=[‘班级‘,‘语文‘]).reset_index(drop=True)
df[‘分组排序‘] = df.groupby(‘班级‘).apply(lambda x:x[‘语文‘].rank(method=‘dense‘)).reset_index(drop=True)
df
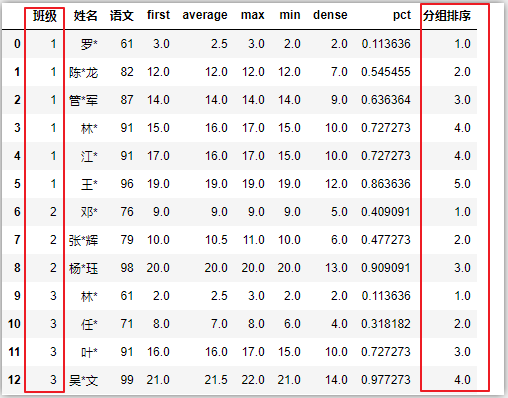
df.eval(‘result=first + average‘,inplace=True) # 表达式计算生成新列
# 四舍五入
df.round(2) # 全部数字字段
df.round({‘result‘: 0, ‘pct‘: 3}) # 指定列
df + 1
df.add() # 加
df.sub() # 减
df.mul() # 乘
df.div() # 除
df.mod() # 模,除后的余数
df.pow() # 指数幂
df.dot(df2) # 矩阵运算
# series特有的函数
s = df[‘result‘]
s.nlargest() # 最大的前5个
s.nlargest(15) # 最大的前15个
s.nsmallest() # 最小的前5个
s.nsmallest(15) # 最小的前15个
s.value_counts() # 去重分组统计
s.pct_change() # 与前一个数变化的百分比=(今-前)/前
原文:https://www.cnblogs.com/xiaoshun-mjj/p/14688018.html