这篇论文的摘要中写道:
In this work, we improve FM by discriminating the importance of different feature interactions.
该论文通过区别不同特征交互的重要性来提升FM算法的性能。其主要的核心部分是通过神经网络实现的注意力机制进行区分。
在有监督学习当中,特征之间的交互是非常重要的。最常见的特征交互莫过于特征交叉,即特征之间进行叉乘的方式。部分特征交互的方案存在一些关键问题,对于只观察到少数交叉特征的稀疏数据集,无法估计未观察到的交叉特征的参数。
FM本身能够度量各种特征交叉的权重,关于FM的相关知识可以参考我之前写过的一篇系列介绍。这篇论文当中也有相对简单的介绍。在介绍FM的过程中,注意到论文举了一个例子,来说明并不是所有的所有的特征交互都会对预测起作用。
However, FM models all possible feature interactions with the same weight, which may adversely deteriorate its generalization performance.
主要是FM里面对交叉特征的权重定义固定,不可调节,其权重公式如下
\(\mathbf{v}\)是输入向量\(\mathbf{x}\)的embedding表示。所以就需要一个可调节的权重来表示这些交叉向量的重要性。
这篇论文提出了新的网络层,称为基于对的交互层,从以前\(m\)个向量扩展层\(\frac{m(m-1)}{2}\)个向量。所产生的的新的交互向量是由源向量之间的元素两两交互产生的,用公式来表示交互的函数可以写作
\(\varepsilon=\{\mathbf{v}_ix_i\}_{i\in X}\)代表了原始向量的embedding。
通过上述的基于对的交互层表示,我们可以进一步对FM进行神经网络的表示。首先对上述的交互进行压缩,使用“和池化”的方式进行,然后接全连接层进行预测得分。
公式当中的\(\mathbf{p}\)和\(b\)都是全连接当中的权重和偏置项。如果我们都将权重设为1,偏置项设为0,那么我们就可以恢复到传统的FM模型。
注意力机制已经很常见了,无论是在推荐、信息检索或者图像领域都有很不错的表现。主要的思想是对多个贡献部分能够在做相同的表示的时候给出不同的权重或者进行区别对待。
带有注意力机制的向量交互可以表示为:
公式当中的\(a_{ij}\)是注意力得分。一般情况下,直接对预测损失进行最小化就可以估计注意力得分。但是通常情况下,在训练数据当中,很多特征不会同时出现,因此无法直接计算注意力得分,因此这篇论文提出了注意力网络。整体的网络结构如下图所示。
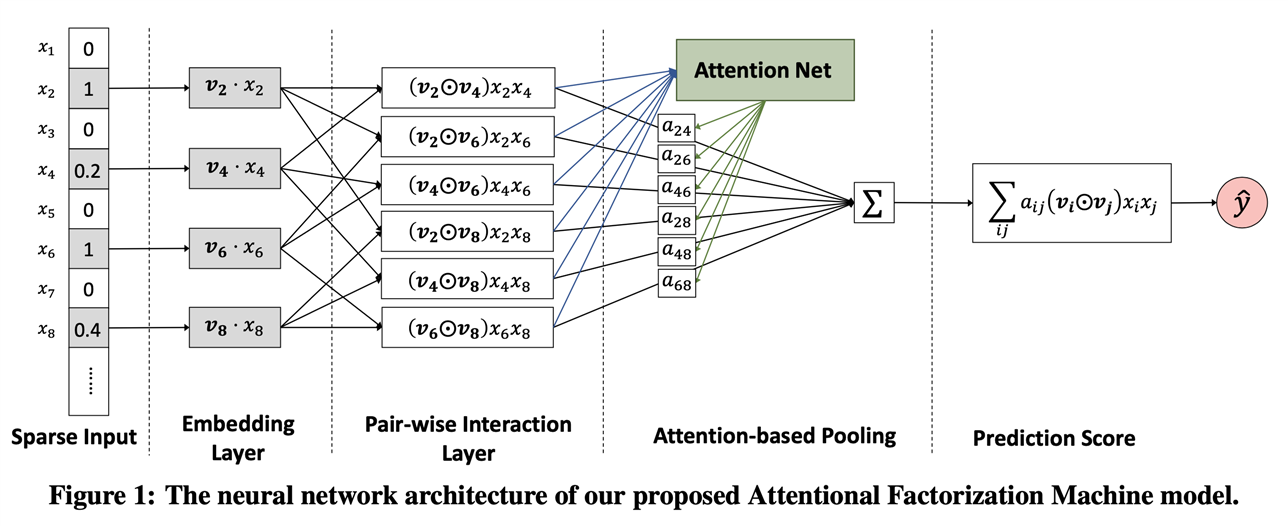
在网络当中的注意力表示公式为:
都是比较基础和常见的注意力机制的操作了。
RecBOLE里面的AFM实现如下所示,我就直接在里面增加注释进行解读。
class AFM(ContextRecommender):
""" AFM is a attention based FM model that predict the final score with the attention of input feature.
"""
def __init__(self, config, dataset):
super(AFM, self).__init__(config, dataset)
# load parameters info
self.attention_size = config[‘attention_size‘]
# 过拟合的DROPOUT的参数设置
self.dropout_prob = config[‘dropout_prob‘]
# 优化的回归权重设置
self.reg_weight = config[‘reg_weight‘]
# 得到的交互对的数量
self.num_pair = self.num_feature_field * (self.num_feature_field - 1) / 2
# define layers and loss
# 后续再补充这个AttLayer的实现
self.attlayer = AttLayer(self.embedding_size, self.attention_size)
self.p = nn.Parameter(torch.randn(self.embedding_size), requires_grad=True)
self.dropout_layer = nn.Dropout(p=self.dropout_prob)
self.sigmoid = nn.Sigmoid()
# 优化损失
self.loss = nn.BCELoss()
# parameters initialization
self.apply(self._init_weights)
def _init_weights(self, module):
if isinstance(module, nn.Embedding):
xavier_normal_(module.weight.data)
elif isinstance(module, nn.Linear):
xavier_normal_(module.weight.data)
if module.bias is not None:
constant_(module.bias.data, 0)
def build_cross(self, feat_emb):
""" Build the cross feature columns of feature columns
Args:
feat_emb (torch.FloatTensor): input feature embedding tensor. shape of [batch_size, field_size, embed_dim].
Returns:
tuple:
- torch.FloatTensor: Left part of the cross feature. shape of [batch_size, num_pairs, emb_dim].
- torch.FloatTensor: Right part of the cross feature. shape of [batch_size, num_pairs, emb_dim].
"""
# 建立需要交互的原始特征
# num_pairs = num_feature_field * (num_feature_field-1) / 2
row = []
col = []
for i in range(self.num_feature_field - 1):
for j in range(i + 1, self.num_feature_field):
row.append(i)
col.append(j)
p = feat_emb[:, row] # [batch_size, num_pairs, emb_dim]
q = feat_emb[:, col] # [batch_size, num_pairs, emb_dim]
return p, q
def afm_layer(self, infeature):
""" Get the attention-based feature interaction score
Args:
infeature (torch.FloatTensor): input feature embedding tensor. shape of [batch_size, field_size, embed_dim].
Returns:
torch.FloatTensor: Result of score. shape of [batch_size, 1].
"""
# 得到需要交互的特征
p, q = self.build_cross(infeature)
# 逐元素点乘
pair_wise_inter = torch.mul(p, q) # [batch_size, num_pairs, emb_dim]
# [batch_size, num_pairs, 1]
# 得到特征得分
att_signal = self.attlayer(pair_wise_inter).unsqueeze(dim=2)
# 特征得分与交互特征进行相乘,然后最大化池化,再就是DROPOUT进行随机失活防止过拟合
att_inter = torch.mul(att_signal, pair_wise_inter) # [batch_size, num_pairs, emb_dim]
att_pooling = torch.sum(att_inter, dim=1) # [batch_size, emb_dim]
att_pooling = self.dropout_layer(att_pooling) # [batch_size, emb_dim]
att_pooling = torch.mul(att_pooling, self.p) # [batch_size, emb_dim]
att_pooling = torch.sum(att_pooling, dim=1, keepdim=True) # [batch_size, 1]
return att_pooling
def forward(self, interaction):
# interaction是RECBOLE里面规整之后的数据输入方式
afm_all_embeddings = self.concat_embed_input_fields(interaction) # [batch_size, num_field, embed_dim]
output = self.sigmoid(self.first_order_linear(interaction) + self.afm_layer(afm_all_embeddings))
return output.squeeze()
def calculate_loss(self, interaction):
label = interaction[self.LABEL]
output = self.forward(interaction)
l2_loss = self.reg_weight * torch.norm(self.attlayer.w.weight, p=2)
# 返回L2 loss以及BCE loss
return self.loss(output, label) + l2_loss
def predict(self, interaction):
return self.forward(interaction)
以下是对上述代码中出现的ATTLAYER的补充
class AttLayer(nn.Module):
"""Calculate the attention signal(weight) according the input tensor.
Args:
infeatures (torch.FloatTensor): A 3D input tensor with shape of[batch_size, M, embed_dim].
Returns:
torch.FloatTensor: Attention weight of input. shape of [batch_size, M].
"""
def __init__(self, in_dim, att_dim):
super(AttLayer, self).__init__()
self.in_dim = in_dim
self.att_dim = att_dim
self.w = torch.nn.Linear(in_features=in_dim, out_features=att_dim, bias=False)
self.h = nn.Parameter(torch.randn(att_dim), requires_grad=True)
def forward(self, infeatures):
att_signal = self.w(infeatures) # [batch_size, M, att_dim]
att_signal = fn.relu(att_signal) # [batch_size, M, att_dim]
att_signal = torch.mul(att_signal, self.h) # [batch_size, M, att_dim]
att_signal = torch.sum(att_signal, dim=2) # [batch_size, M]
att_signal = fn.softmax(att_signal, dim=1) # [batch_size, M]
return att_signal
原文:https://www.cnblogs.com/nomornings/p/14690253.html