最近学习了极客时间的《数据结构与算法之美》很有收获,记录总结一下。
欢迎学习老师的专栏:数据结构与算法之美
代码地址:https://github.com/peiniwan/Arithmetic
周末你带着女朋友去电影院看电影,女朋友问你,咱们现在坐在第几排啊?电影院里面太黑了,看不清,没法数,现在你怎么办?别忘了你是程序员,这个可难不倒你,递归就开始排上用场了。
于是你就问前面一排的人他是第几排,你想只要在他的数字上加一,就知道自己在哪一排了。但是,前面的人也看不清啊,所以他也问他前面的人。就这样一排一排往前问,直到问到第一排的人,说我在第一排,然后再这样一排一排再把数字传回来。直到你前面的人告诉你他在哪一排,于是你就知道答案了。
我们用递推公式将它表示出来就是这样的:
f(n)=f(n-1)+1 其中,f(1)=1
f(n) 表示你想知道自己在哪一排,f(n-1) 表示前面一排所在的排数,f(1)=1 表示第一排的人知道自己在第一排。有了这个递推公式,我们就可以很轻松地将它改为递归代码,如下:
int f(int n) {
if (n == 1) return 1;
return f(n-1) + 1;
}
写递归代码最关键的是写出递推公式,找到终止条件
爬楼梯
int f(int n) {
if (n == 1) return 1;
if (n == 2) return 2;
return f(n-1) + f(n-2);
}
写递归代码的关键就是找到如何将大问题分解为小问题的规律,并且基于此写出递推公式,然后再推敲终止条件,最后将递推公式和终止条件翻译成代码。
人脑几乎没办法把整个“递”和“归”的过程一步一步都想清楚。计算机擅长做重复的事情,所以递归正和它的胃口。
对于递归代码,这种试图想清楚整个递和归过程的做法,实际上是进入了一个思维误区。很多时候,我们理解起来比较吃力,主要原因就是自己给自己制造了这种理解障碍。那正确的思维方式应该是怎样的呢?
如果一个问题 A 可以分解为若干子问题 B、C、D,你可以假设子问题 B、C、D 已经解决,在此基础上思考如何解决问题 A。而且,你只需要思考问题 A 与子问题 B、C、D 两层之间的关系即可,不需要一层一层往下思考子问题与子子问题,子子问题与子子子问题之间的关系。屏蔽掉递归细节,这样子理解起来就简单多了。
因此,编写递归代码的关键是,只要遇到递归,我们就把它抽象成一个递推公式,不用想一层层的调用关系,不要试图用人脑去分解递归的每个步骤。
不要陷入思维误区。
函数调用会使用栈来保存临时变量。每调用一个函数,都会将临时变量封装为栈帧压入内存栈,等函数执行完成返回时,才出栈。系统栈或者虚拟机栈空间一般都不大。如果递归求解的数据规模很大,调用层次很深,一直压入栈,就会有堆栈溢出的风险。
那么,如何避免出现堆栈溢出呢?
// 全局变量,表示递归的深度。
int depth = 0;
int f(int n) {
++depth;
if (depth > 1000) throw exception;
if (n == 1) return 1;
return f(n-1) + 1;
}
但这种做法并不能完全解决问题,因为最大允许的递归深度跟当前线程剩余的栈空间大小有关,事先无法计算。如果实时计算,代码过于复杂,就会影响代码的可读性。所以,如果最大深度比较小,比如 10、50,就可以用这种方法,否则这种方法并不是很实用。
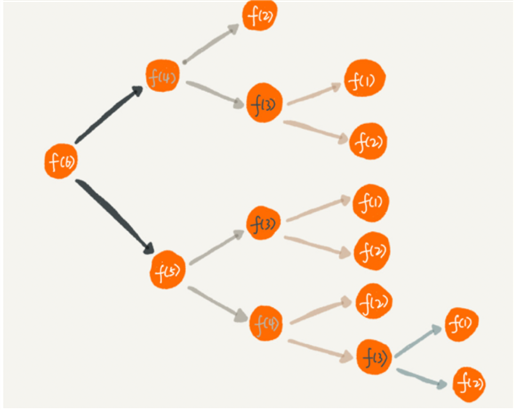
为了避免重复计算,我们可以通过一个数据结构(比如散列表)来保存已经求解过的 f(k)。当递归调用到 f(k) 时,先看下是否已经求解过了。如果是,则直接从散列表中取值返回,不需要重复计算,这样就能避免刚讲的问题了。
public int f(int n) {
if (n == 1) return 1;
if (n == 2) return 2;
// hasSolvedList可以理解成一个Map,key是n,value是f(n)
if (hasSolvedList.containsKey(n)) {
return hasSolvedList.get(n);
}
int ret = f(n-1) + f(n-2);
hasSolvedList.put(n, ret);
return ret;
}
电影院递归代码,空间复杂度并不是 O(1),而是 O(n)。
递归有利有弊,利是递归代码的表达力很强,写起来非常简洁;而弊就是空间复杂度高、有堆栈溢出的风险、存在重复计算、过多的函数调用会耗时较多等问题
电影院修改
int f(int n) {
int ret = 1;
for (int i = 2; i <= n; ++i) {
ret = ret + 1;
}
return ret;
}
但是这种思路实际上是将递归改为了“手动”递归,本质并没有变,而且也并没有解决前面讲到的某些问题,徒增了实现的复杂度。
推荐注册返佣金的这个功能我想你应该不陌生吧?现在很多 App 都有这个功能。这个功能中,用户 A 推荐用户 B 来注册,用户 B 又推荐了用户 C 来注册。我们可以说,用户 C 的“最终推荐人”为用户 A,用户 B 的“最终推荐人”也为用户 A,而用户 A 没有“最终推荐人”。
long findRootReferrerId(long actorId) {
Long referrerId = select referrer_id from [table] where actor_id = actorId;
if (referrerId == null) return actorId;
return findRootReferrerId(referrerId);
}
不过在实际项目中,上面的代码并不能工作,为什么呢?这里面有两个问题。
第一,如果递归很深,可能会有堆栈溢出的问题。
第二,如果数据库里存在脏数据,我们还需要处理由此产生的无限递归问题。比如 demo 环境下数据库中,测试工程师为了方便测试,会人为地插入一些数据,就会出现脏数据。如果 A 的推荐人是 B,B 的推荐人是 C,C 的推荐人是 A,这样就会发生死循环。
第一个问题,我前面已经解答过了,可以用限制递归深度来解决。第二个问题,也可以用限制递归深度来解决。不过,还有一个更高级的处理方法,就是自动检测 A-B-C-A 这种“环”的存在。如何来检测环的存在呢?
调试递归
我们平时调试代码喜欢使用 IDE 的单步跟踪功能,像规模比较大、递归层次很深的递归代码,几乎无法使用这种调试方式。
调试递归:
public class Recursion {
/**
* 求和
*/
public static int summation(int num) {
if (num == 1) {
return 1;
}
return num + summation(num - 1);
}
/**
* 求二进制
*/
public static int binary(int num) {
StringBuilder sb = new StringBuilder();
if (num > 0) {
summation(num / 2);
int i = num % 2;
sb.append(i);
}
System.out.println(sb.toString());
return -1;
}
/**
* 求n的阶乘
*/
public int f(int n) {
if (n == 1) {
return n;
} else {
return n * f(n - 1);
}
}
}
有点像分治,底层必须依赖数组,并且还要求数据是有序的。二分查找更适合处理静态数据,也就是没有频繁的数据插入、删除操作。

这是一个等比数列。其中 n/2k=1 时,k 的值就是总共缩小的次数。而每一次缩小操作只涉及两个数据的大小比较,所以,经过了 k 次区间缩小操作,时间复杂度就是 O(k)。通过 n/2k=1,我们可以求得 k=log2n,所以时间复杂度就是 O(logn)。
public int binarySearch(int[] arr, int k) {
if (arr.length == 0) {
return -1;
}
if (arr[0] == k) {
return 0;
}
int a = 0;
int b = arr.length - 1;
while (a <= b) {
int m = a + (b - a) / 2;
if (k < arr[m]) {
b = m-1;
} else if (k > arr[m]) {
a = m + 1;
} else {
return m;
}
}
return -1;
}
容易出错的 3 个地方
二分查找除了用循环来实现,还可以用递归来实现
// 二分查找的递归实现
public int bsearch(int[] a, int n, int val) {
return bsearchInternally(a, 0, n - 1, val);
}
private int bsearchInternally(int[] a, int low, int high, int value) {
if (low > high) return -1;
int mid = low + ((high - low) >> 1);
if (a[mid] == value) {
return mid;
} else if (a[mid] < value) {
return bsearchInternally(a, mid+1, high, value);
} else {
return bsearchInternally(a, low, mid-1, value);
}
}
首先,二分查找依赖的是顺序表结构,简单点说就是数组。
数组按照下标随机访问数据的时间复杂度是 O(1),而链表随机访问的时间复杂度是 O(n)。所以,如果数据使用链表存储,二分查找的时间复杂就会变得很高。
其次,二分查找针对的是有序数据。
数据必须是有序的。如果数据没有序,我们需要先排序
如果我们的数据集合有频繁的插入和删除操作,要想用二分查找,要么每次插入、删除操作之后保证数据仍然有序,要么在每次二分查找之前都先进行排序。针对这种动态数据集合,无论哪种方法,维护有序的成本都是很高的。
所以,二分查找只能用在插入、删除操作不频繁,一次排序多次查找的场景中。针对动态变化的数据集合,二分查找将不再适用。那针对动态数据集合,如何在其中快速查找某个数据呢?别急,等到二叉树那一节我会详细讲。
再次,数据量太小不适合二分查找。
如果要处理的数据量很小,完全没有必要用二分查找,顺序遍历就足够了。比如我们在一个大小为 10 的数组中查找一个元素,不管用二分查找还是顺序遍历,查找速度都差不多。只有数据量比较大的时候,二分查找的优势才会比较明显。
最后,数据量太大也不适合二分查找。
二分查找的底层需要依赖数组这种数据结构,而数组为了支持随机访问的特性,要求内存空间连续,对内存的要求比较苛刻。比如,我们有 1GB 大小的数据,如果希望用数组来存储,那就需要 1GB 的连续内存空间。
如何在 1000 万个整数中快速查找某个整数?
这个问题并不难。我们的内存限制是 100MB,每个数据大小是 8 字节,最简单的办法就是将数据存储在数组中,内存占用差不多是 80MB,符合内存的限制。借助今天讲的内容,我们可以先对这 1000 万数据从小到大排序,然后再利用二分查找算法,就可以快速地查找想要的数据了。
虽然大部分情况下,用二分查找可以解决的问题,用散列表、二叉树都可以解决。但是,我们后面会讲,不管是散列表还是二叉树,都会需要比较多的额外的内存空间。如果用散列表或者二叉树来存储这 1000 万的数据,用 100MB 的内存肯定是存不下的。而二分查找底层依赖的是数组,除了数据本身之外,不需要额外存储其他信息,是最省内存空间的存储方式,所以刚好能在限定的内存大小下解决这个问题。
十个二分九个错
上一节讲的只是二分查找中最简单的一种情况,在不存在重复元素的有序数组中,查找值等于给定值的元素。最简单的二分查找写起来确实不难,但是,二分查找的变形问题就没那么好写了。

变体一:查找第一个值等于给定值的元素
如下面这样一个有序数组,其中,a[5],a[6],a[7] 的值都等于 8,是重复的数据。我们希望查找第一个等于 8 的数据,也就是下标是 5 的元素。
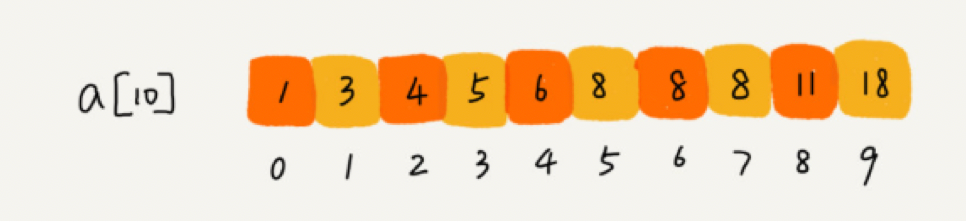
如果我们用上一节课讲的二分查找的代码实现,首先拿 8 与区间的中间值 a[4] 比较,8 比 6 大,于是在下标 5 到 9 之间继续查找。下标 5 和 9 的中间位置是下标 7,a[7] 正好等于 8,所以代码就返回了。
尽管 a[7] 也等于 8,但它并不是我们想要找的第一个等于 8 的元素,因为第一个值等于 8 的元素是数组下标为 5 的元素。
public int bsearch(int[] a, int n, int value) {
int low = 0;
int high = n - 1;
while (low <= high) {
int mid = low + ((high - low) >> 1);
if (a[mid] > value) {
high = mid - 1;
} else if (a[mid] < value) {
low = mid + 1;
} else {
if ((mid == 0) || (a[mid - 1] != value)) return mid;
else high = mid - 1;
}
}
return -1;
}
变体二:查找最后一个值等于给定值的元素
前面的问题是查找第一个值等于给定值的元素,我现在把问题稍微改一下,查找最后一个值等于给定值的元素,又该如何做呢?
public int bsearch(int[] a, int n, int value) {
int low = 0;
int high = n - 1;
while (low <= high) {
int mid = low + ((high - low) >> 1);
if (a[mid] > value) {
high = mid - 1;
} else if (a[mid] < value) {
low = mid + 1;
} else {
if ((mid == n - 1) || (a[mid + 1] != value)) return mid;
else low = mid + 1;
}
}
return -1;
}
变体三:查找第一个大于等于给定值的元素
在有序数组中,查找第一个大于等于给定值的元素。比如,数组中存储的这样一个序列:3,4,6,7,10。如果查找第一个大于等于 5 的元素,那就是 6。
public int bsearch(int[] a, int n, int value) {
int low = 0;
int high = n - 1;
while (low <= high) {
int mid = low + ((high - low) >> 1);
if (a[mid] >= value) {
if ((mid == 0) || (a[mid - 1] < value)) return mid;
else high = mid - 1;
} else {
low = mid + 1;
}
}
return -1;
}
变体四:查找最后一个小于等于给定值的元素
我们来看最后一种二分查找的变形问题,查找最后一个小于等于给定值的元素。比如,数组中存储了这样一组数据:3,5,6,8,9,10。最后一个小于等于 7 的元素就是 6。
public int bsearch7(int[] a, int n, int value) {
int low = 0;
int high = n - 1;
while (low <= high) {
int mid = low + ((high - low) >> 1);
if (a[mid] > value) {
high = mid - 1;
} else {
if ((mid == n - 1) || (a[mid + 1] > value)) return mid;
else low = mid + 1;
}
}
return -1;
}
我们用的最多的就是编程语言提供的字符串查找函数,比如 Java 中的 indexOf(),Python 中的 find() 函数等,它们底层就是依赖接下来要讲的字符串匹配算法。
BF 算法和 RK 算法、BM 算法和 KMP 算法。
BF 算法中的 BF 是 Brute Force 的缩写,中文叫作暴力匹配算法,也叫朴素匹配算法。
我们在字符串 A 中查找字符串 B,那字符串 A 就是主串,字符串 B 就是模式串。我们把主串的长度记作 n,模式串的长度记作 m。因为我们是在主串中查找模式串,所以 n>m。
BF 算法的思想可以用一句话来概括,那就是,我们在主串中,检查起始位置分别是 0、1、2…n-m 且长度为 m 的 n-m+1 个子串,看有没有跟模式串匹配的(看图)。
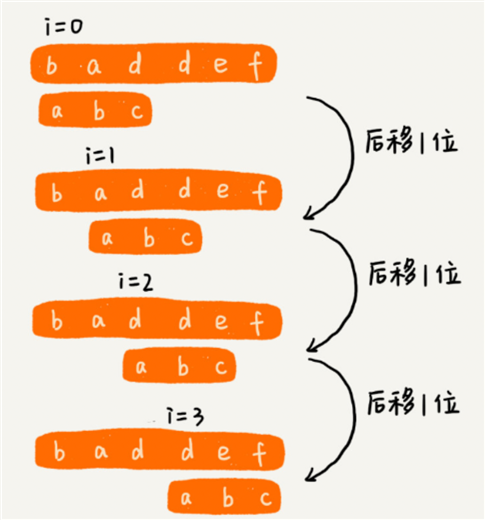
我们每次都比对 m 个字符,要比对 n-m+1 次,所以,这种算法的最坏情况时间复杂度是 O(n* m)。
/**
* BF算法
* 检查起始位置分别是 0、1、2…n-m 且长度为 m 的 n-m+1 个子串,看有没有跟模式串匹配的
*/
public static int bfFind(String S, String T, int pos) {
char[] arr1 = S.toCharArray();
char[] arr2 = T.toCharArray();
int i = pos;
int j = 0;
while (i < arr1.length && j < arr2.length) {
if (arr1[i] == arr2[j]) {
i++;
j++;
} else {
i = i - j + 1;
j = 0;
}
}
if (j == arr2.length) return i - j;
else return -1;
}
尽管理论上,BF 算法的时间复杂度很高,是 O(n* m),但在实际的开发中,它却是一个比较常用的字符串匹配算法。
第一,实际的软件开发中,大部分情况下,模式串和主串的长度都不会太长。
第二,朴素字符串匹配算法思想简单,代码实现也非常简单。
BF 算法的升级版。
BF每次检查主串与子串是否匹配,需要依次比对每个字符,所以 BF 算法的时间复杂度就比较高,是 O(n* m)。我们对朴素的字符串匹配算法稍加改造,引入哈希算法,时间复杂度立刻就会降低。
RK 算法的思路是这样的:我们通过哈希算法对主串中的 n-m+1 个子串分别求哈希值,然后逐个与模式串的哈希值比较大小。如果某个子串的哈希值与模式串相等,那就说明对应的子串和模式串匹配了(这里先不考虑哈希冲突的问题,后面我们会讲到)。因为哈希值是一个数字,数字之间比较是否相等是非常快速的,所以模式串和子串比较的效率就提高了。
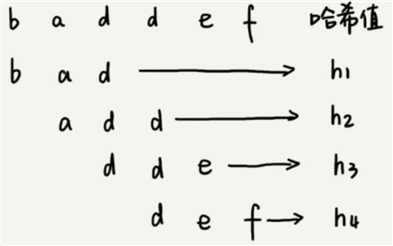
比如要处理的字符串只包含 a~z 这 26 个小写字母,那我们就用二十六进制来表示一个字符串。我们把 a~z 这 26 个字符映射到 0~25 这 26 个数字,a 就表示 0,b 就表示 1,以此类推,z 表示 25。
在十进制的表示法中,一个数字的值是通过下面的方式计算出来的。对应到二十六进制,一个包含 a 到 z 这 26 个字符的字符串,计算哈希的时候,我们只需要把进位从 10 改成 26 就可以。
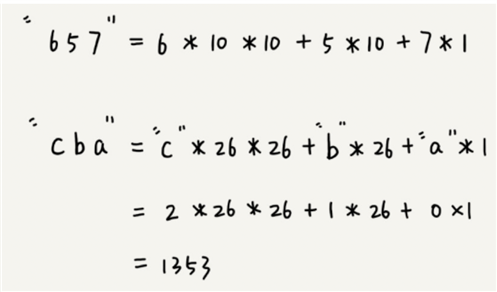
这种哈希算法有一个特点,在主串中,相邻两个子串的哈希值的计算公式有一定关系。我这有个个例子,你先找一下规律,再来看我后面的讲解。
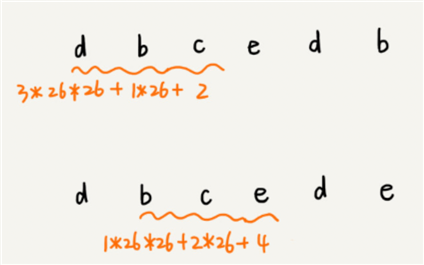
从这里例子中,我们很容易就能得出这样的规律:相邻两个子串 s[i-1] 和 s[i](i 表示子串在主串中的起始位置,子串的长度都为 m),对应的哈希值计算公式有交集,也就是说,我们可以使用 s[i-1] 的哈希值很快的计算出 s[i] 的哈希值。如果用公式表示的话,就是下面这个样子:

原文:https://www.cnblogs.com/sixrain/p/14693369.html