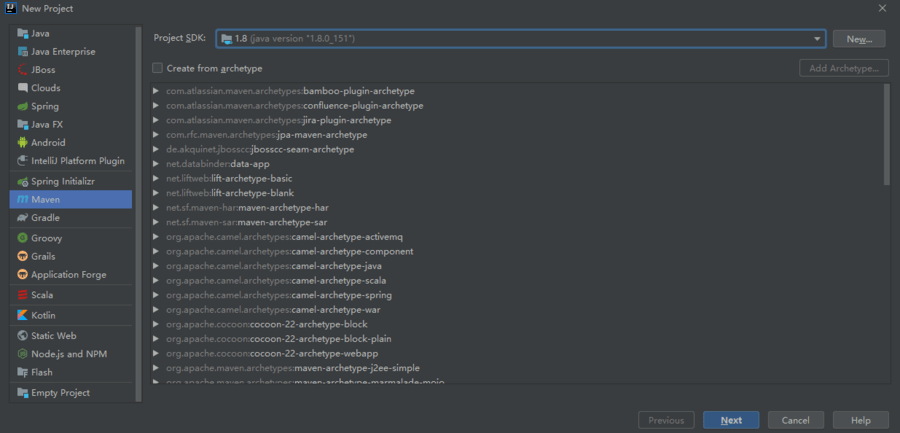
1、idea中新建一个Maven项目

自定义名称
2、编辑pom文件,包括spark、scala、hadoop等properties版本信息、dependencies依赖、和plugins 插件信息
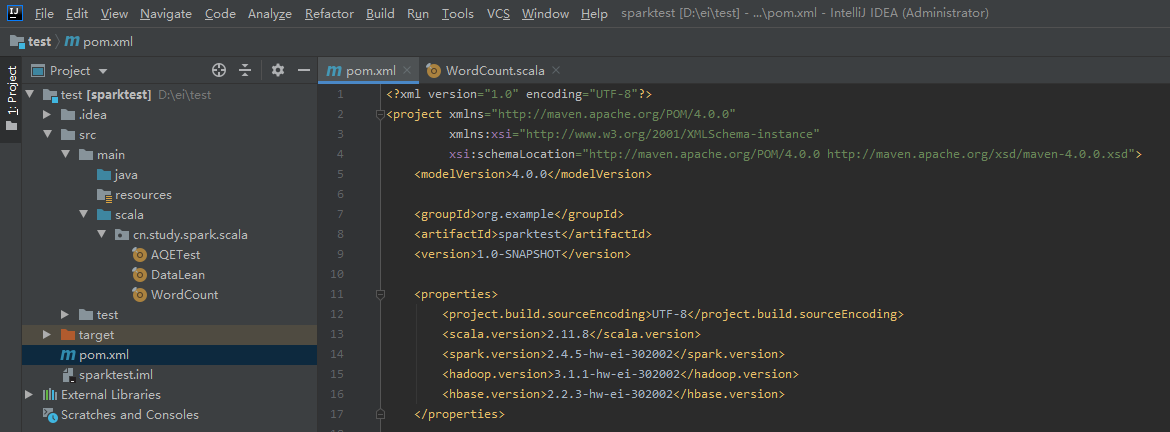
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.example</groupId> <artifactId>sparktest</artifactId> <version>1.0-SNAPSHOT</version> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <scala.version>2.11.8</scala.version> <spark.version>2.4.5-hw-ei-302002</spark.version> <hadoop.version>3.1.1-hw-ei-302002</hadoop.version> <hbase.version>2.2.3-hw-ei-302002</hbase.version> </properties> <dependencies> <!--导入scala的依赖 --> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <!--导入spark的依赖 --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>${spark.version}</version> </dependency> <!--指定hadoop-client API的版本 --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>${hadoop.version}</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <version>2.15.2</version> <configuration> <recompileMode>modified-only</recompileMode> </configuration> <executions> <execution> <id>main-scalac</id> <phase>process-resources</phase> <goals> <goal>add-source</goal> <goal>compile</goal> </goals> </execution> <execution> <id>scala-test-compile</id> <phase>process-test-resources</phase> <goals> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.1</version> <executions> <execution> <phase>compile</phase> <goals> <goal>compile</goal> </goals> </execution> </executions> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> <directory>target</directory> <outputDirectory>target/classes</outputDirectory> <testOutputDirectory>target/test-classes</testOutputDirectory> </build> </project>
创建derectory,命名:scala。看颜色同java不一样,此时还不是源码包,不能添加class
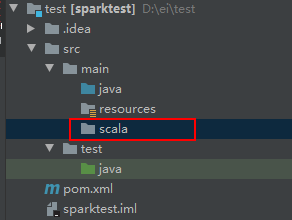
3、点击reimport ,也就是小圆圈,变成源码包

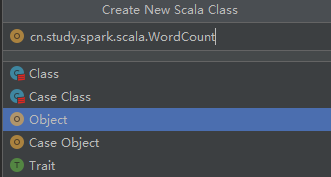
4、创建scala class,编写程序
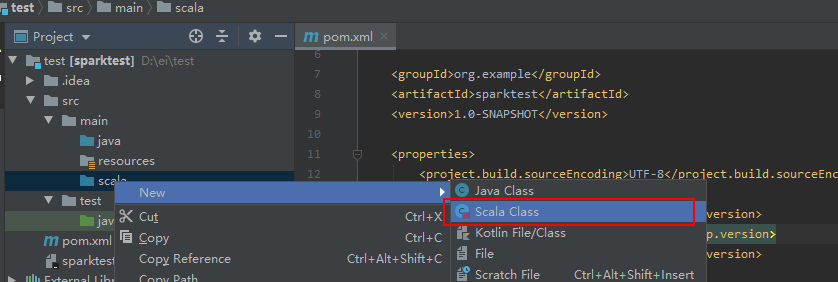
创建object,自定义名称
5、编辑好程序,双击package打包,即可生成jar包

package cn.study.spark.scala import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext, rdd} object WordCount{ def main(args: Array[String]): Unit = { //创建spark配置,设置应用程序名称 val conf = new SparkConf().setAppName("ScalaWordCount") //创建spark执行的入口 var sc = new SparkContext(conf) //指定读取创建RDD(弹性分布式数据集)的文件 //sc.textFile(args(0)).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false).saveAsTextFile(args(1)) val lines:RDD[String] = sc.textFile(args(0)) //切分压平 val words:RDD[String] = lines.flatMap(_.split(" ")) //将单词和一组合 val wordAndOne:RDD[(String,Int)] = words.map((_,1)) //按key进行聚合 val reduced:RDD[(String,Int)] = wordAndOne.reduceByKey(_+_) val sorted:RDD[(String,Int)] = reduced.sortBy(_._2,false) //将结果保存到hdfs中 sorted.saveAsTextFile(args(1)) //释放资源 sc.stop() } }
6、jar包上传集群节点,hdfs上传存放word的文件

7、运行程序跑起来
spark-submit --master yarn --deploy-mode client --class cn.study.spark.scala.WordCount sparktest-1.0-SNAPSHOT.jar /tmp/test/t1.txt /tmp/test/t2
8、查看结果

idea编写wordcount程序及spark-submit运行
原文:https://www.cnblogs.com/cailingsunny/p/14695341.html