一 背景:句子不通顺在应用场景中经常出现,但是可以参考的东西并不多,你是我最好的朋友 对比。你是我好的朋友,后一句明显不通顺,大量的数据想把这些低质的不通顺的句子识别出来,如果不借助工具和算法的力量,我们需要耗费大量的时间和精力也无法解决好这些比较常用的问题。
二 句子通顺度的识别思路:
(a)基于规则来解决这个问题:构建词表的方式,但是发现很难建立完善的语言规则也缺乏相关的语言学知识,实现这么完整的一套规则也不简单,其中发现实词是能够单独充当句子成分的词,有名词、动词、形容词、数词、量词、副词、代词、拟声词;虚词是不能单独充当句子成分的词,有介词、连词、 助词、语气词。
(b)N-Gram:基于词来做参数量巨大,需要非常完善且高质量的语料库,而词的词性种类数目很小,基于词性来做就不会有基于词的困扰,而且基于词性来做直觉上更能体现搭配出现的关系。
(c)深度学习学习句子通顺与否的特征,通过神经网络模型进行训练预测。
三 算法实现:
(1)n_gram调研:
问题探索:经过对一些错误的句子分析之后,发现某些类型的词不应该拼接在一起,比如动词接动词(e.g.我打开听见),这种情况很少会出现在我们的生活中。
n-gram的结果并没有想象的那么好,在样本正负比例2:1的情况下表现效果很差,结果极度偏向不通顺样本,设置阈值麻烦。
n-gram预测空缺词的方法:https://github.com/Jed-Z/ngram-text-prediction https://www.jeddd.com/article/python-ngram-language-prediction.html
n-gram的优化:样本正负样本比例需要调节,阈值划分需要其他方面的思考。
n-gram处理不通顺度的流程:以3-gram为例子,参考指标衡量方式:https://blog.csdn.net/dianyanxia/article/details/107592000 https://blog.csdn.net/hxxjxw/article/details/107722646
(1)建立n-gram词表,词表1分别为3个词滑动出现并且统计出现频次,词表2分别为2个词的滑动出现并且统计出现频次。
(2)通过ppl指标进行test数据的预测观察结果
(3)通过句子分词,句子分词后的词性分别计算句子出现的概率
(4)句子越长ppl就会越高,句子越长,乘积后的概率越小,ppl反而越大
n_gram算法实验结果:(1)1_gram和2_gram对比中,句子出现的联合概率的整体受到句子长度的影响非常大,句子越长ppl越大。
(2)2_gram中句子是否通顺:
(a)对比一个句子中的2_gram的滑动窗口下,一个句子产生所有的2_gram的集合,用该集合中最差的出现概率代替整个句子的出现概率,最后求ppl.
(b)对比一个句子中的2_gram的滑动窗口下,一个句子产生所有的2_gram的集合,用该集合中平均的出现概率代替整个句子的出现概率,最后求ppl.
(3)平滑处理:计算ppl过程中需要进行平滑处理,避免词表中不存在词频的数据,其概率就会为0.
(4)数据词表:数据量越大效果会越好,80w和400w的标题构建词表,产生的词典中词频有很大的差距,所以数据量越大越好。
其实现如下:
# !/usr/bin/python
# -*- coding: UTF-8 -*-
from __future__ import division
import numpy as np
from io import open
import time
import jieba
import jieba.posseg as pseg
from collections import Counter
def text_filter(text):
"""
文本过滤器:过滤掉文本数据中的标点符号和其他特殊字符
:param text: 待过滤的文本
:return: 过滤后的文本
"""
result = str()
for t in text:
if t.isalnum():
if t.isalpha():
t = t.lower()
result += t
return result
def slide_word(tf, l=2):
"""
滑动取词器
Input: text=‘abcd‘,l=2
Output: [‘ab‘,‘bc‘,‘cd‘]
:param text: 过滤后的文本 (只包含小写数字/字母)
:param l: 滑动窗口长度,默认为 5
:return:
"""
#tf = text_filter(text)
result = list()
if len(tf) <= l:
result.append(tf)
return result
for i in range(len(tf)):
word = tf[i:i + l]
if len(word) < l:
break
result.append(word)
return result
def perplexity_n(sentence, bi_gram_dict, l):
"""
function:
计算句子的ppl平均出现概率
params:
sentence:待计算的句子
bi_gram_dict:2个词组的字典
l:2个词组的总数量
"""
V = l
l_p = [] # 概率初始值
k = 1 # ngram 的平滑值,平滑方法:Add-k Smoothing (k<1)
ll = slide_word(sentence)
for i in ll:
p = (bi_gram_dict.get(i, 0) + k) / (k + V)
l_p.append(p)
print(l_p)
return 1 / np.min(l_p)
def data_seg_word(path):
"""
function:
数据滑动拆分构建词典
params:
path:训练集
"""
ngrams_list = [] # n元组(分子)
l = 0
count = 0
with open(path, ‘r‘, encoding=‘utf-8‘) as trainf:
for line in trainf:
if len(line.strip()) != 0:
items = line.strip().split(‘\t‘)
count += 1
if len(items) == 2 and count:
# print(items)
ngrams = slide_word(items[1])
l += len(ngrams)
ngrams_list += ngrams
# 返回字典
ngrams_counter = Counter(ngrams_list)
return ngrams_counter, l
if __name__ == "__main__":
#构建2元词典的过程
ngrams_counter, l = data_seg_word()
#计算句子的出现概率
pro = perplexity_n(sentense, ngrams_counter, l)
(1)句子不通顺的样本部分来源:https://github.com/tracy-talent/curriculum/tree/master/NLP/smooth/smooth/input
(2)样本增强的方式:抽取tp问答和自有内容的问答的标题,通过python脚本进行不同程度的截断,产生不通顺的样本
(3)cnn模型训练结果与其他模型对比结果:通过paddle 1.15版本实现在 https://aistudio.baidu.com/aistudio/projectdetail/71554?channelType=0&channel=0
(4)cnn模型总结发现:句子结尾带有呢,吗这种语气助词以及?,这样的标志更容易判断是通顺的。
(5)阈值的划分:通过不同的阈值划分出不通顺的部分,后期进行修改和补充。目前阈值的划分是0.5,可以结合具体情况进行阈值划分,0.4等等的划分。
(3) 规则过滤:
a 句子去重长度大于2通常不通顺;b 特殊字的开头和结尾的单独出现;c 相同的词性不能共现
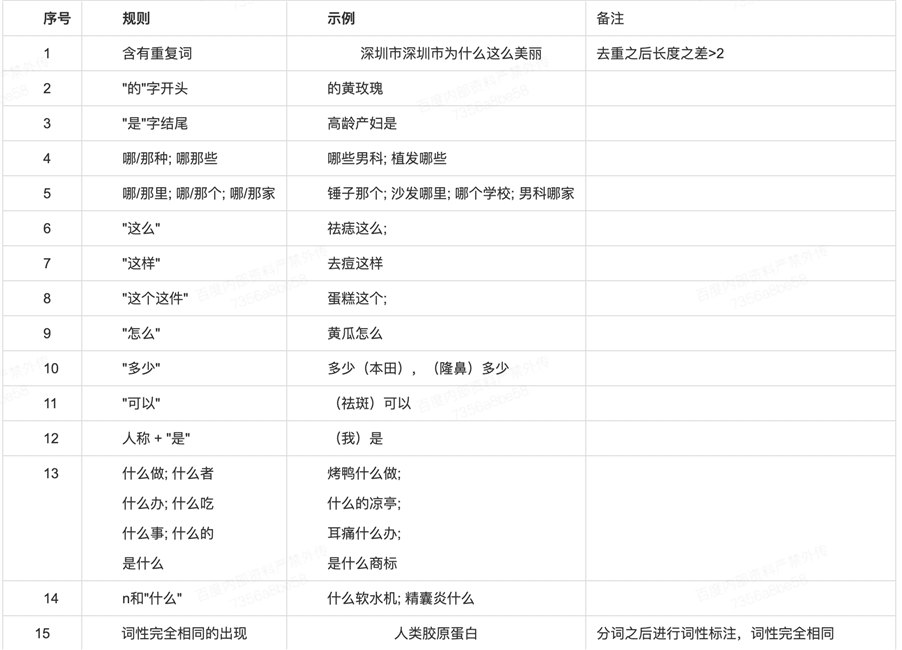
其代码实现如下:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import requests
import re
import json
import jieba
import jieba.posseg as pseg
fuhao_word_set = set()
def init_fuhao_word_dict(fuhao_word_path):
"""
function:加载标点符号列表
params: fuhao_word_path 标点符号存放列表
"""
global fuhao_word_dict
input_file = open(fuhao_word_path, "r")
lines = input_file.readlines()
input_file.close()
for line in lines:
fuhao_word_set.add(line.strip().decode("utf8"))
white_fuhao_set_1 = set("""‘"()[]{}‘’“”《》()【】{}"""[:])
white_fuhao_set_2 = set("""‘"()[]{}‘’“”《》()【】{}?,?,"""[:])
white_fuhao_set_3 = set("""‘"()[]{}‘’“”《》()【】{}??…"""[:])
white_fuhao_set_3.add("...")
white_fuhao_set_3.add("……")
stop_word_set = set(["你好", "谢谢", "多谢"])
def get_word_list_jieba(content):
"""
funtion:对内容进行分词
params:content 切词的内容
"""
seg = jieba.cut(content, cut_all=False)
return list(seg)
def get_dis_fuhao_word_list(word_list):
"""
function:去掉句子中冗余的标点符号
params:word_list 分词结果
"""
str_len = len(word_list)
dis_word_list = []
dis_word_num = 0
fuhao_num = 0
if str_len > 1:
pro_idx = -1
# pro_word = word_list[0]
for i in range(0, str_len):
if word_list[i] in fuhao_word_set:
fuhao_num += 1
if pro_idx == -1:
pro_idx = i
dis_word_list.append(word_list[i])
else:
if word_list[pro_idx] in fuhao_word_set and word_list[i] in fuhao_word_set:
dis_word_num += 1
else:
dis_word_list.append(word_list[i])
pro_idx = i
else:
pro_idx = -1
dis_word_list.append(word_list[i])
return dis_word_list, dis_word_num, fuhao_num
kuohao_map = {")": "(", ")": "("}
def format_fuhao_word_list(word_list):
"""
function:返回标准化后的句子结果
params:word_list 分词结果
"""
str_len = len(word_list)
str_idx = 0
res_word_list = []
word_kuohao_dict = dict()
if str_len > 1:
for i in range(0, str_len):
if word_list[i] in fuhao_word_set:
if str_idx == 0:
if word_list[i] in white_fuhao_set_1:
res_word_list.append(word_list[i])
str_idx += 1
else:
pass
else:
if i == str_len - 1:
if word_list[i] in white_fuhao_set_3:
res_word_list.append(word_list[i])
str_idx += 1
else:
if word_list[i] in white_fuhao_set_2:
res_word_list.append(word_list[i])
str_idx += 1
else:
res_word_list.append(" ")
str_idx += 1
else:
res_word_list.append(word_list[i])
str_idx += 1
if len(res_word_list) > 0:
for i in range(0, len(res_word_list)):
if res_word_list[i] in ["(", "("]:
word_kuohao_dict[res_word_list[i]] = i
if res_word_list[i] in [")", ")"]:
kuohao_tmp = kuohao_map.get(res_word_list[i])
if kuohao_tmp in word_kuohao_dict:
word_kuohao_dict.pop(kuohao_tmp)
else:
res_word_list[i] = " "
if len(word_kuohao_dict) > 0:
for j in word_kuohao_dict.values():
res_word_list[j] = " "
return res_word_list
return word_list
def merge(sentence, max_ngram_length=4):
"""
function:去掉句子重复词
params: max_ngram_length 控制滑动窗口
"""
final_merge_sent = sentence
max_ngram_length = min(max_ngram_length, len(sentence))
for i in range(max_ngram_length, 0, -1):
start = 0
end = len(final_merge_sent) - i + 1
ngrams = []
while start < end:
ngrams.append(final_merge_sent[start: start + i])
start += 1
result = []
for cur_word in ngrams:
result.append(cur_word)
if len(result) > i:
pre_word = result[len(result) - i - 1]
if pre_word == cur_word:
for k in range(i):
result.pop()
cur_merge_sent = ""
for word in result:
if not cur_merge_sent:
cur_merge_sent += word
else:
cur_merge_sent += word[-1]
final_merge_sent = cur_merge_sent
if (len(final_merge_sent) - len(sentence)) > 2:
return 1
return 0
def regular_ze(title):
"""
title:输入的标题
"""
r = [‘这次‘, ‘这么‘, ‘这儿‘, ‘这个‘, ‘这样‘,