在前一部分,我们自己实现了通过torch的相关方法完成反向传播和参数更新。
在pytorch中预设了一些更加灵活的简单对象,让我们来构造模型,定义损失,优化损失等。
下面我们就来学习这些pytorch中常用的API。
nn.Module 是 torch.nn 提供的一个类,是 pytorch 中我们自定义网络的一个基类,在这个类中定义了很多有用的方法,让我们在继承这个类定义网络的时候非常简单。
当我们自定义网路的时候,有两个方法需要特别注意:
(1) __init__ 需要调用super方法,继承父类的属性和方法
(2) forward方法必须实现,用来定义我们的网络的向前计算过程
用前面的y=wx+b的模型举例如下:
from torch import nn
class Lr(nn.Module):
def __init__(self):
super(Lr,self).__init__() # 继承父类的init参数
self.linear = nn.Linear(1,1)
def forward(self,x):
out = self.linear(x)
return out
注意:
(1)nn.Linear是torch预定义好的线性模型,也被称为全链接层, 传入的参数为输入的数量,输出的数量(in_features,out_features),是不算(batch_size的列数)
(2)nn.Module定义了__call__方法,实现的就是调用forward方法,即Lr的实例,能够直接被传入参数使用,实际上调用的是forward方法并传入参数。
# 实例化模型
model = Lr()
# 传入数据,计算结果
predict = model(x)
优化器(optimizer),可以理解为torch为我们封装的用来进行更新参数的方法,比如常见的随机梯度下降(SGD)
优化器都是由torch.optim提供的,例如
torch.optim.SGD(参数,学习率)
torch.optim.Adam(参数,学习率)
注意:
参数可以使用model.parameters()来获取,获取模型中所有requires_grad=True的参数
优化类的使用方法
示例如下:
optimizer = optim.SGD(model.parameters(), lr=1e-3) #1. 实例化
optimizer.zero_grad() #2. 梯度置为0
loss.backward() #3. 计算梯度
optimizer.step() #4. 更新参数的值
前面的例子是一个回归问题,torch中也预测了很多损失函数
nn.MSELoss(),常用于回归问题nn.CrossEntropyLoss(),常用于分类问题使用方法:
model = Lr() #1. 实例化模型
criterion = nn.MSELoss() #2. 实例化损失函数
optimizer = optim.SGD(model.parameters(), lr=1e-3) #3. 实例化优化器类
for i in range(100):
y_predict = model(x_true) #4. 向前计算预测值
loss = criterion(y_true,y_predict) #5. 调用损失函数传入真实值和预测值,得到损失结果
optimizer.zero_grad() #5. 当前循环参数梯度置为0
loss.backward() #6. 计算梯度
optimizer.step() #7. 更新参数的值
import torch
from torch import nn
from torch import optim
import numpy as np
from matplotlib import pyplot as plt
# 1. 定义数据
x = torch.rand([50,1])
y = x*3 + 0.8
#2 .定义模型
class Lr(nn.Module):
def __init__(self):
super(Lr,self).__init__()
self.linear = nn.Linear(1,1)
def forward(self, x):
out = self.linear(x)
return out
#3. 实例化模型,loss,和优化器
model = Lr()
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=1e-3)
#4. 训练模型
for i in range(30000):
out = model(x) #3.1 获取预测值
loss = criterion(y,out) #3.2 计算损失
optimizer.zero_grad() #3.3 梯度归零
loss.backward() #3.4 计算梯度
optimizer.step() # 3.5 更新梯度
if (i+1) % 20 == 0:
print(‘Epoch[{}/{}], loss: {:.6f}‘.format(i,30000,loss.data))
#5. 模型评估
model.eval() #设置模型为评估模式,即预测模式
predict = model(x)
predict = predict.data.numpy()
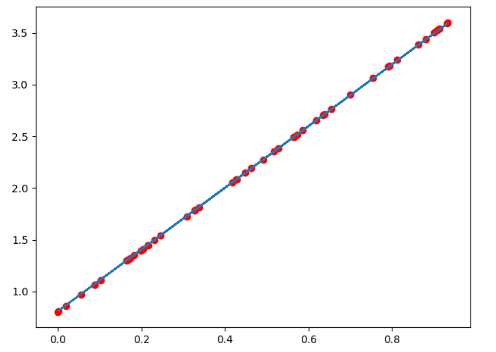
plt.scatter(x.data.numpy(),y.data.numpy(),c="r")
plt.plot(x.data.numpy(),predict)
plt.show()
输出如下:
注意:
model.eval()表示设置模型为评估模式,即预测模式
model.train(mode=True) 表示设置模型为训练模式
在当前的线性回归中,上述并无区别
但是在其他的一些模型中,训练的参数和预测的参数会不相同,到时候就需要具体告诉程序我们是在进行训练还是预测,比如模型中存在Dropout,BatchNorm的时候
当模型太大,或者参数太多的情况下,为了加快训练速度,经常会使用GPU来进行训练
此时我们的代码需要稍作调整:
判断GPU是否可用torch.cuda.is_available()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
>>device(type=‘cuda‘, index=0) #使用gpu
>>device(type=‘cpu‘) #使用cpu
把模型参数和input数据转化为cuda的支持类型
model.to(device)
x_true.to(device)
在GPU上计算结果也为cuda的数据类型,需要转化为numpy或者torch的cpu的tensor类型
predict = predict.cpu().detach().numpy()
detach()的效果和data的相似,但是detach()是深拷贝,data是取值,是浅拷贝
修改之后的代码如下:
import torch
from torch import nn
from torch import optim
import numpy as np
from matplotlib import pyplot as plt
import time
# 1. 定义数据
x = torch.rand([50,1])
y = x*3 + 0.8
#2 .定义模型
class Lr(nn.Module):
def __init__(self):
super(Lr,self).__init__()
self.linear = nn.Linear(1,1)
def forward(self, x):
out = self.linear(x)
return out
# 3. 实例化模型,loss,和优化器
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
x,y = x.to(device),y.to(device)
model = Lr().to(device)
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=1e-3)
# 4. 训练模型
for i in range(300):
out = model(x)
loss = criterion(y,out)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 20 == 0:
print(‘Epoch[{}/{}], loss: {:.6f}‘.format(i,30000,loss.data))
# 5. 模型评估
model.eval() #
predict = model(x)
predict = predict.cpu().detach().numpy() #转化为numpy数组
plt.scatter(x.cpu().data.numpy(),y.cpu().data.numpy(),c="r")
plt.plot(x.cpu().data.numpy(),predict,)
plt.show()
每次迭代都需要把所有样本都送入,这样的好处是每次迭代都顾及了全部的样本,做的是全局最优化,但是有可能达到局部最优。
针对梯度下降算法训练速度过慢的缺点,提出了随机梯度下降算法,随机梯度下降算法算法是从样本中随机抽出一组,训练后按梯度更新一次,然后再抽取一组,再更新一次,在样本量及其大的情况下,可能不用训练完所有的样本就可以获得一个损失值在可接受范围之内的模型了。
torch中的api为:torch.optim.SGD()
SGD相对来说要快很多,但是也有存在问题,由于单个样本的训练可能会带来很多噪声,使得SGD并不是每次迭代都向着整体最优化方向,因此在刚开始训练时可能收敛得很快,但是训练一段时间后就会变得很慢。在此基础上又提出了小批量梯度下降法,它是每次从样本中随机抽取一小批进行训练,而不是一组,这样即保证了效果又保证的速度。
mini-batch SGD算法虽然这种算法能够带来很好的训练速度,但是在到达最优点的时候并不能够总是真正到达最优点,而是在最优点附近徘徊。
另一个缺点就是mini-batch SGD需要我们挑选一个合适的学习率,当我们采用小的学习率的时候,会导致网络在训练的时候收敛太慢;当我们采用大的学习率的时候,会导致在训练过程中优化的幅度跳过函数的范围,也就是可能跳过最优点。我们所希望的仅仅是网络在优化的时候网络的损失函数有一个很好的收敛速度同时又不至于摆动幅度太大。
所以Momentum优化器刚好可以解决我们所面临的问题,它主要是基于梯度的移动指数加权平均,对网络的梯度进行平滑处理的,让梯度的摆动幅度变得更小。
(注:t+1的的histroy_gradent 为第t次的gradent)
AdaGrad算法就是将每一个参数的每一次迭代的梯度取平方累加后在开方,用全局学习率除以这个数,作为学习率的动态更新,从而达到自适应学习率的效果
Momentum优化算法中,虽然初步解决了优化中摆动幅度大的问题,为了进一步优化损失函数在更新中存在摆动幅度过大的问题,并且进一步加快函数的收敛速度,RMSProp算法对参数的梯度使用了平方加权平均数。
Adam(Adaptive Moment Estimation)算法是将Momentum算法和RMSProp算法结合起来使用的一种算法,能够达到防止梯度的摆幅多大,同时还能够加开收敛速度
torch中的api为:torch.optim.Adam()
深度学习与PyTorch | PyTorch完成基础的模型 | 07
原文:https://www.cnblogs.com/Rowry/p/14695903.html