Scrapy框架
第一板块:scrapy介绍、安装、基本使用
-什么是框架?
-就是一个集成了很多功能并且具有很强通用性的一个项目模板。
-如何学习框架?
-专门学习框架封装的各种功能的详细用法。
-什么是scrapy?
-爬虫中封装好的一个明星框架。功能:高性能的持久化操作,异步的数据下载,高性能的数据解析,分布式。
-scrapy框架的基本使用
-环境的安装:
-mac or linux: pip install scrapy
-windows:
-下载twisted,下载地址为:
http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
-安装twisted:
pip install Twisted-17.1.0-cp36-cp36m-win_amd64.whl
-pip install pywin32
-pip install scrapy
测试:在终端里录入scrapy指令,没有报错即表示安装成功!
-创建一个工程:scrapy startproject xxxPro
-cd xxxPro
-在spiders子目录中创建一个爬虫文件
-scrapy genspider spiderName www.xxx.com
-执行工程:
-scrapy crawl spiderName
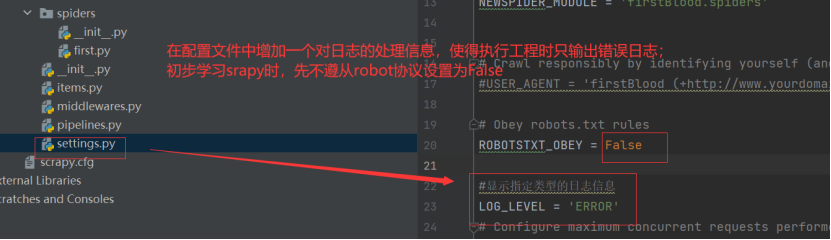
scrapy的配置文件修改:
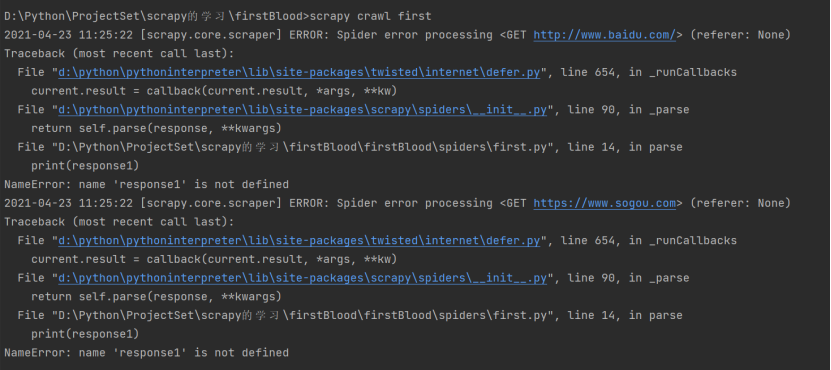
运行结果如下:
在spiders文件夹中创建一个基于scrapy框架的爬虫文件后,对配置文件必要的设置如下:(UA伪装)

第二大板块:基于scrapy的数据解析
-创建一个scrapy工程的基本目录结构如下:
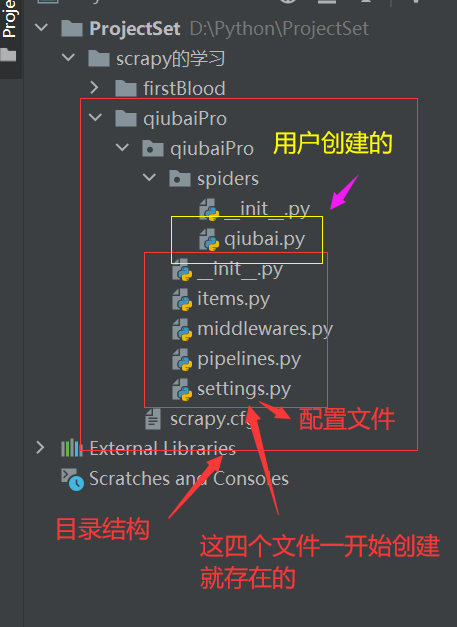
qiubai.py
1 import scrapy 2 3 4 class QiubaiSpider(scrapy.Spider): 5 name = ‘qiubai‘ 6 # allowed_domains = [‘www.xxx.com‘] 7 start_urls = [‘https://www.qiushibaike.com/text/‘] 8 9 def parse(self, response): 10 #解析:作者的名称+段子的内容 11 div_list = response.xpath(‘//div[@class="col1 old-style-col1"]/div‘) 12 # print(len(div_list)) 13 num = 0 14 for div in div_list: 15 #xpath 返回的是列表,但是列表元素一定是Selector类型的对象 16 #extract可以将Selector对象中data参数存储的字符串提取出来 17 author = div.xpath(‘./div[1]/a[2]/h2/text()‘)[0].extract() 18 #列表调用了extract之后,则表示将列表中每一个Selector对象中data对应的字符串提取了出来 19 content = div.xpath(‘./a[1]/div/span//text()‘).extract() 20 #将列表转化成字符串 21 content = ‘‘.join(content) 22 print("++++++++++++++++++++++++++++++++++++") 23 print(num,author,content) 24 print("++++++++++++++++++++++++++++++++++++") 25 num+=1
注意:
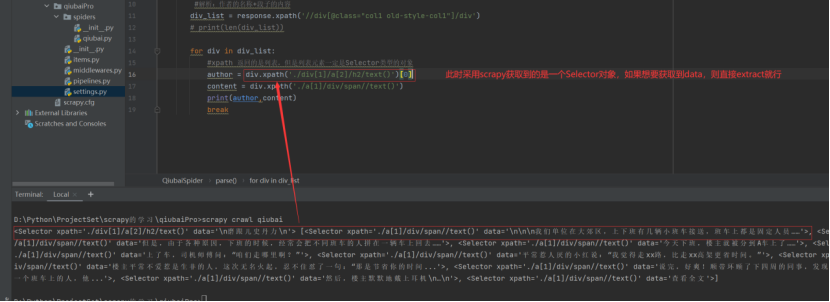
-etract_first()操作前提条件是得保证是对列表长度为1的进行操作。
总结:
UA伪装、Robot协议、日志文件的设置都在settings.py即配置文件中;
规定在spiders子目录下创建scrapy爬虫;
项目运行方式为:scrapy crawl spiderName;
对于scrapy爬虫得到的response对象,进行xpath操作后,得到的对象不是一个etree对象而是一个Selector对象,那么要取得其data数据则只需将Selecor对象进行extract操作就行;
原文:https://www.cnblogs.com/industrial-fd-2019/p/14697462.html