编译语言设计的精髓在于自动化过程,即如果要设计一门编程语言,那么一定要设计一个自动化系统,能够自行读入分析程序员写入的程序,将其翻译为机器能够识别的指令等信息。当然高级语言的编译不是一蹴而就的,而是通过若干步的分解、规约、转换、优化,最后得到目标程序。
具体的编译步骤如下:
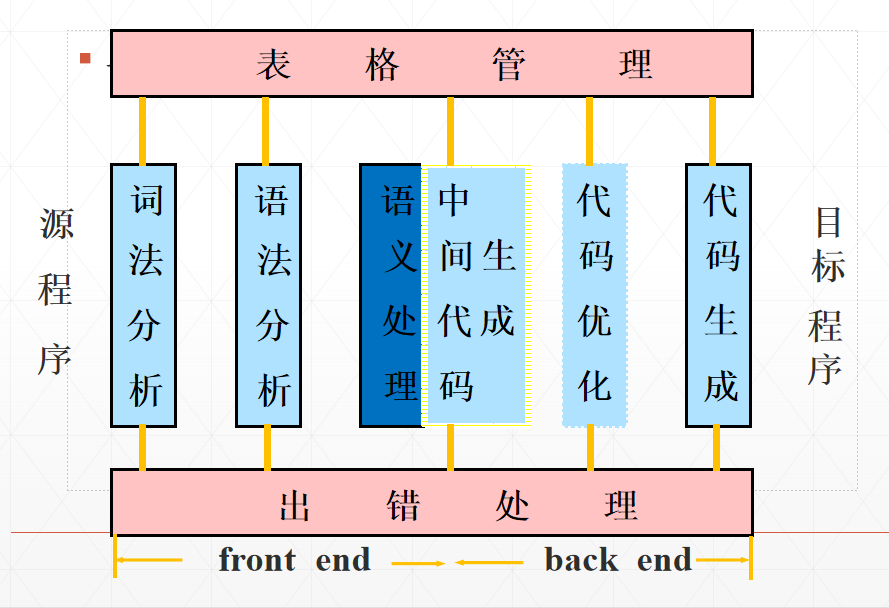
源程序就是我们写入的高级语言,编译的第一步叫做“词法分析”。词法分析的本质,就是要拆解出语句的每一个单词,然后对这个单词的类型进行辨识。
首先拿中文来举例。比如有一句话是“我喜欢你”,那么首先我们要把这句话拆成“我”、“喜欢”、“你”,然后再逐个分析他们的类型,得到“我”->主语;“喜欢”->谓语;“你”->宾语。这样我们就把这句话每个单词都分析出来了,也就完成了中文的“词法分析”。
那么回到编程语言,它的词法分析就是将字符序列转换为单词(Token)序列的过程。翻译成俗话,就是把我们写的大片语言文本分解为一个一个单词,再输出每个单词的类型。举一个例子:
int p = 3 + a;
这个语句非常简单,即定义一个变量p,它的初值为变量a与3的加和。那么接下来我们要对这个语句进行词法分析,首先我们要把这段文本拆解成单词,拆出来就是‘int‘、‘p‘、‘=‘、‘3‘、‘+‘、‘a‘、‘;‘。对这些单词再进行类型的辨识,那么就得到以下结果:
| 语素 | 语言类型 |
| int | 关键字 |
| p | 标识符 |
| = | 运算符 |
| 3 | 数字 |
| + | 运算符 |
| a | 标识符 |
这样我们就把这段文本中的每个单词的类型都分析出来了。乍一看非常简单对不对,对于人类而言你只需要用肉眼就可以轻松观察出来每个单词的类型,但对于计算机而言,它可没有人类那样的智能。如果想要计算机能够识别并分析语素的类型,那就需要我们人类来为它构造一个自动化输入和分析的系统。
构造自动系统的步骤主要分为如下几步:
①编写正则表达式(RE)
②将正则表达式转换为非确定有限自动机(NFA)
③将非确定有限自动机转换为确定有限自动机(DFA)
④将确定有限自动机最小化、规范化
⑤利用确定有限自动机编程
那么接下来就介绍一下上述提到的这几个系统。
正则表达式的英文名称是Regular Expression,简称RE。我们先来看一下定义:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
用俗话来解释,就是正则表达式可以指定一种字符串的规则,只有满足相应规则的字符串才能与表达式相匹配。那么接下来介绍几种最简单的RE:
① a|b -> 只有一个字符且非a即b
② ab -> 字符串必须是ab连接
上述两个非常基础,也很好理解。举个例子,单个数字的正则表达式就是0|1|2|3|4|5|6|7|8|9,即要想匹配“单个数字”这个规则的内容,必须是一个数字且是0~9中的一个;两位数字的正则表达式就是10|11|12|...|99,不多赘述。接下来会有稍微复杂的表达式:
③(a|b)* -> 有任意个(a|b)连接,例如abaaabbabbba...
④(a|b)+ -> 有非零个(a|b)连接
⑤(a|b)? -> 有零到一个(a|b),相当于只有单个a 或 单个b 或ε(空串)可以匹配
⑥[^ab] -> 匹配非a非b的字符
⑦^ab -> 匹配以ab开头的字符串
...
其实还有很多种正则表达类型,但是文法分析用不到那么复杂的,因此就没再列了。对上述规则熟悉后,我们便可以用正则表达式来表达一些我们想要匹配的字符串类型。例如我们想匹配规范的偶数,那么我们就可以这样设计正则表达式:
(1|2|3|4|5|6|7|8|9)?(0|1|2|3|4|5|6|7|8|9)*(0|2|4|6|8)
即首位不能是零,中间位可以是任意个数的任意数字,末位必须是偶数的数字。
再举一个:以a开头和结尾的小写字母串,那么正则表达式就是:
a((a-z)*a)?
即确定a为开头,后面内容可有可无,如果后面有内容,那么必须强行a结尾。这里要提示的是,像上述的正则表达式我们都是根据题意下意识直接构造的,它并不规范,具有很强的不确定性。规范确定的正则表达式也叫正规表达式,之后会介绍这部分内容,这里只是做个提示。
上文我们使用正则表达式把要匹配的文本模式表示了出来,但是RE也并非计算机能够直接识别的内容,因为计算机对于*、+这些符号的反应机制很难构造。这里我们要引入一个新东西:自动机(Automata)。自动机这个东西其实很好理解,如下图:
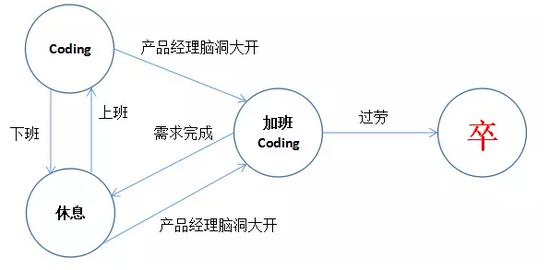
自动机共由5部分组成,分别是状态集合S、输入字符Σ、状态转移函数f、初态S0、终止态Z,即状态自动机M=(S,Σ,f,S0,Z)。对于上图而言:
S={休息,Coding,加班Coding,卒}
Σ={上班,下班,需求完成,产品经理脑洞大开,过劳}
S0=休息
Z={卒} ps:终态可以不唯一
f是一系列映射的集合,映射就是某状态获得某输入后转移到某新状态的意思。
在这个自动机中,最开始是休息状态,获得上班的输入以后就会转移到Coding的状态,以此类推,当状态变为卒时,便可以终止该自动机的运行。
如果一个自动机的状态是有限的,那么我们称其为有限状态机(Finite Automata,简称FA)。但是存在这么一种状态机,它存在下述两种情况:
①同一个状态获得同一个输入,却转移到多个不同的输出状态;
②状态的输入存在ε-边,即无条件状态转移。
下面我们可以看一下这两个例子:
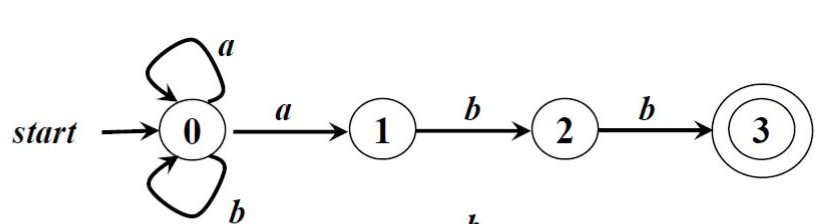
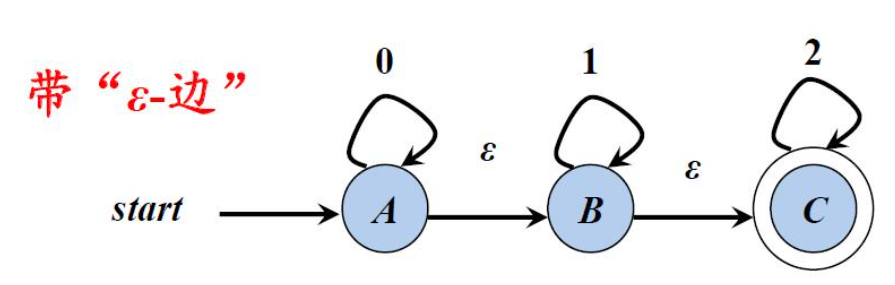
特点还是比较明显的。图1的状态0获得输入a后,分别指向了状态0和状态1;图2中的状态A可以无条件转移到状态B,状态B又无条件转移到状态C。当一个有限自动机存在这些特点时,这个自动机是不稳定的、不确定的,ε-边的存在导致了状态不稳定性,多重输出的存在导致了状态转移的不确定性。含有这些特点的状态机我们叫做非确定有限自动机(Nondeterministic Finite Automata,简称NFA)。
那么,为什么要先介绍NFA这种存在瑕疵的自动机呢?这是因为当我们拿到正则表达式RE后,能直接构造出来的状态机就是非确定的。接下来我们来了解一下如何将RE转化为NFA。
首先我们来看一些NFA的转化规则:
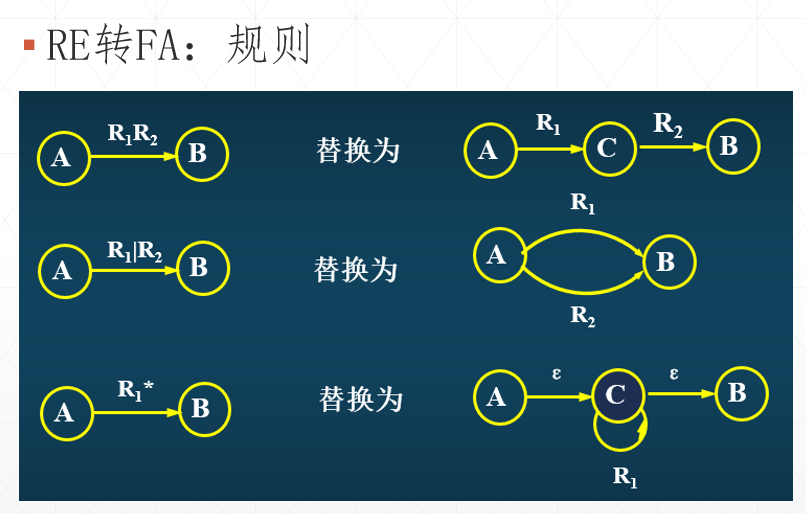
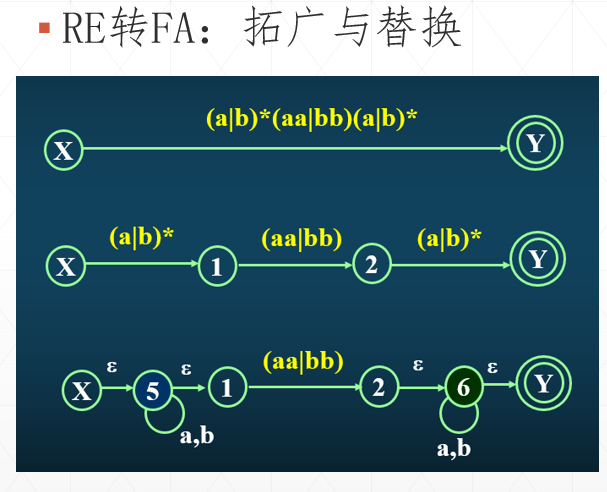
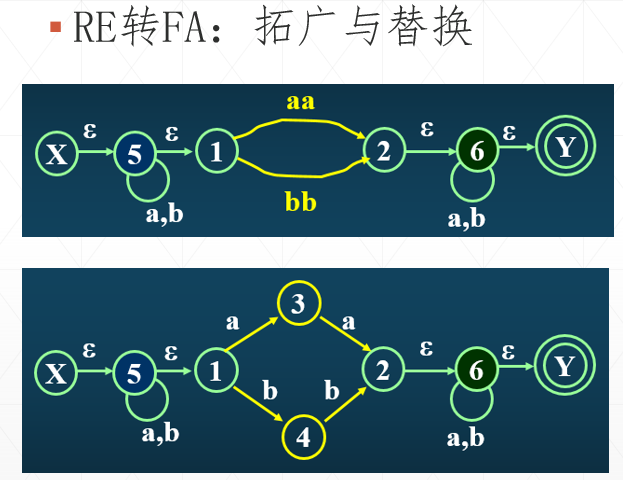
简而言之就是:遇到连接字符串,则分离字符;遇到或符号,则分多条路;遇到*号,则创建ε-边进入到一个“自循环”状态。运用这个规则,我们就可以对(a|b)*(aa|bb)(a|b)*这种正则表达式进行NFA转换了,如图3下半张图就是(a|b)*(aa|bb)(a|b)*这个正则表达式对应的NFA结果。仔细观察可以看到,ε-边和多重输入的状态是很难避免的,因此我们说从RE转成的FA绝大部分情况会是NFA。
与NFA对立,确定有限自动机(Deterministic Finite Automata,简称DFA)就要具备两个条件:不能存在ε-边,不能存在相同输入的多状态转移,例如:
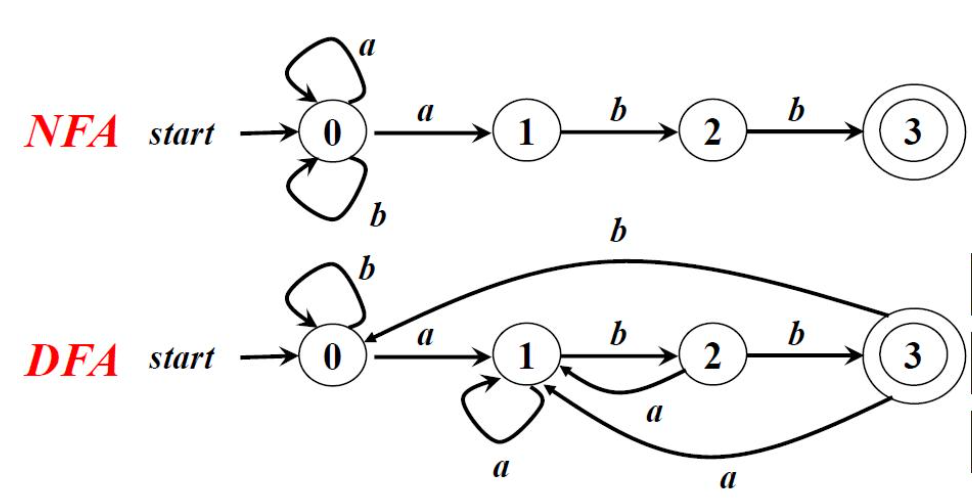
图中的DFA对于每个状态而言,一种输入只能有一个固定的去向,消去了NFA多重状态转移的问题。那么,如何证明这个DFA和原来的NFA是等价的呢?我们可以测试所有输入,然后检查两个自动机是否有相同的匹配结果。例如在NFA中输入bbabb可以进入到终态,在DFA中输入bbabb同样可以到终态。对于所有的输入都有相同的匹配结果,那么这个DFA和NFA就是等价的。
判断不难判断,但NFA转换为等价DFA这个工作可不是随便画两笔就能完成的。这里我们要引入一个新的概念:ε-闭包(ε-closure)。什么是ε-闭包呢,就是某个状态通过若干步ε-边转移以后,所能到达的所有状态集合。ε-closure(A)的意思就是从A状态出发,经过无限次ε-边转移以后所能经过的所有状态。举个实例:
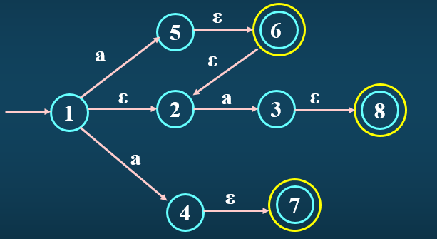
这个图里面,如果要求ε-closure({5}),那么我们就从状态5出发,不断走ε-边,易得经过的状态有5、6、2(必须包括5自己)。这样{5,6,2}就是ε-closure({5})所求的闭包集合。
大家一定猜到闭包的实质是在干嘛了:因为DFA要求没有ε-边,因此我们就把有ε-边连接的几个状态给划分为一团(即闭包),这样ε-边只会出现在这个闭包内。如果我们把闭包定义为新的状态,那么这个闭包内部的ε-边自然就没了。拿刚才的ε-closure({5})举例,5、6、2之间有很多ε-边,现在我们把5、6、2塞到一团里成为一个闭包,然后再把这个闭包定义为一个新状态,那么ε-边就成功消除了。
好,现在ε-闭包可以帮助我们消去ε-边,但现在还有一个问题没解决,那就是单输入出现多状态转移的问题。针对这个问题,我们的解决方式依然是闭包,只不过这回不是ε-闭包,而是a-闭包、b-闭包、c-闭包...(其中abc都是输入)
a-闭包的定义可以仿照ε-闭包,即对于某状态集,经过一步a转换后所能经过的状态的集合(注意是一步,不再像ε-闭包那样是任意步),然后对这些状态分别再求ε-闭包。这个可能有点绕,拿刚才的图举例子,如果要求a-closure({1,2}),那么首先我们对状态1和2分别输入a,得到的是{3,4,5},然后再对{3,4,5}求ε-闭包,得到的就是{3,4,5,6,2,8,7},这样{3,4,5,6,2,8,7}就成为了一个新的闭包和状态。
a-闭包解决多状态转移的思路与ε-闭包解决ε-边的思路非常相似。由于有的状态输入a以后有多个状态转移,那我直接把这多个去向划分为一团(即闭包),这样多重a-边转移就只会出现在闭包内,再把闭包转换为一个新状态,那么多重转移就消除了。
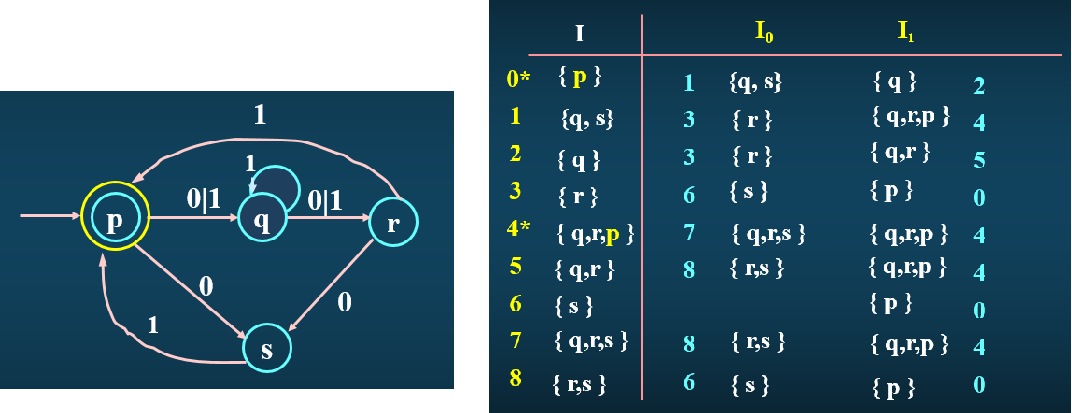
上图是一个NFA转DFA的例子。首先我们第一个闭包选择初态p的ε-闭包,发现结果就是p,那么我们把这个ε-闭包结果作为新的状态0放到I列中。接下来我们要对这个新状态0分别求0-闭包和1-闭包:p输入0以后能到达的状态是q和s,再对q和s求ε-闭包发现还是q和s,那么{q,s}就是状态0的0-闭包。这时发现{q,s}是一种新的状态(未在I列出现),我们要把这些新的状态添加到I列中,然后不断重复上述工作,直到状态不再增加为止。
此时新的状态已经出来了,那么每个状态经过输入以后转移到什么状态也就出来了,例如上表状态0输入0以后转移到状态1,输入1以后转移到状态2,以此类推,然后我们就可以轻松构建出一个DFA自动机了。
DFA的成功建立意味着可以进行编程工作了,只要编码完成计算机便拥有了分析输入串的能力。但是有时候我们得到的DFA非常庞大,其中不乏一些无用状态。因此我们需要精简DFA,去掉一些无用状态,将一些等价状态进行合并。
在最开始,我们将所有状态划分为两个闭包,一个是终结态闭包,包含了所有终结状态;一个是非终结态闭包,包含了所有非终结状态。对于闭包内部,我们可以进一步进行划分:当同一闭包内的两个状态不是等价状态时,它们就可以划分为不同的闭包。
什么叫等价状态呢?这词是我编的,定义如下:如果两个状态对于所有输入,最后转移到的闭包相同,那么两个状态就是等价的,可以进行合并。举个例子:
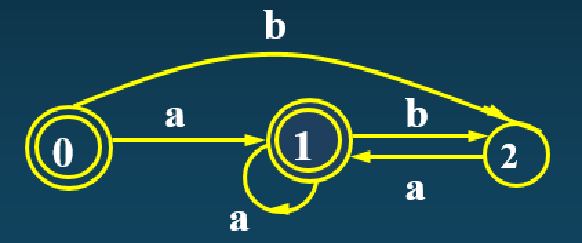
按照上述规则,首先我们把这几个状态分为终结态闭包{0,1}和非终结态闭包{2},对于{0,1}这个闭包进行测试:当输入a时,0和1指向的都是自身闭包;当输入b时,0和1指向的都是2那个闭包,即满足“对于所有输入,最后转移到的闭包相同”,因此我们说0和1是等价状态,可以合并:
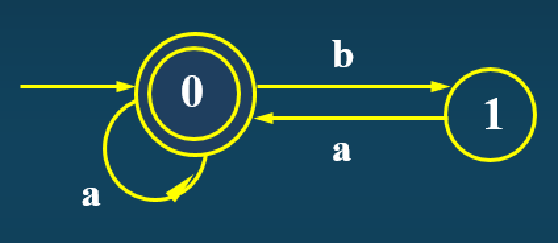
可以看到原来的0和1就合并为了新的0,整个自动机少了一个冗余的状态,这样我们就得到了一个精简化的DFA。接下来我们可以对DFA进行编程,这应该相对比较容易(但是码量很庞大),因此就不再多赘述了。
词法分析的关键在于正则表达式的准确构造、NFA的建立、NFA与DFA的转化以及DFA的最小化,这样便将一个符号表达式转化为一个计算机可自动读入、分析输入串的自动机程序。词法分析的结果是分离的tokens和属性,那么如何判断这些属性的搭配是否合理呢?那就涉及到编译原理的下一层——语法分析了。语法分析的难度将会更上一层,只有认真体会设计思想、多思考多练习,才能将编译原理学习得更加深入。
原文:https://www.cnblogs.com/puluoji/p/14700749.html