library(ggplot2) #fortify()
library(dplyr) #full_join()
windowsFonts(font1=windowsFont(‘Book Antiqua‘),
font2=windowsFont(‘Cambria‘),
font3=windowsFont(‘华文中宋‘),
font4=windowsFont(‘楷体‘))
##写入地图边界数据
x0 = rgdal::readOGR("D:/R/china-province-border-data/bou2_4p.shp")
x <- x0@data
xs <- data.frame(x, id = seq(0:924) -1)# 地图中共计有925个地域信息
xs[‘id‘]<-as.character(xs$id)
china_map1 <- fortify(x0) #提取复合数据类型中的数据
china_map_data <- full_join(china_map1, xs,type = "full")# 基于id进行连接
##导入自己的数据
mydata <-read.csv("C:/Users/.../Desktop/map_value.csv",encoding = "UTF-8")
names(mydata)<-c("NAME","value")
china_data <- full_join(china_map_data,mydata, type = "full")
#基于NAME字段进行连接,NAME字段来自于地图文件中
##获取省份中心坐标
prov_path <- system.file("geojson/china.json", package = "leafletCN")
prov_map <- leafletCN::read.geoShape (prov_path)
prov_data <- prov_map@data
prov_names <- prov_data$name # 或者regionNames("china")
prov_centroids <- vector("list", length(prov_names))
for (i in seq_along(prov_names)) {
prov_centroids[[i]] <- prov_map[prov_data$name == prov_names[[i]], ] %>%
rgeos::gCentroid() %>%
as_tibble()
}
prov_centroids_tb <- bind_rows(prov_centroids)#转化为数据框
prov_centroids_name <- bind_cols(prov_centroids_tb, name = prov_names)
names(prov_centroids_name)=c("cp1","cp2","NAME")
##汇总数据
china_data <- full_join(china_data,prov_centroids_name)
#以简称显示省市名称
china_data$NAME <- gsub(pattern = "省", replacement = "", china_data$NAME)
china_data$NAME <- gsub(pattern = "市", replacement = "", china_data$NAME)
china_data$NAME <- gsub(pattern = "自治区", replacement = "", china_data$NAME)
china_data$NAME <- gsub(pattern = "维吾尔", replacement = "", china_data$NAME)
china_data$NAME <- gsub(pattern = "壮族", replacement = "", china_data$NAME)
china_data$NAME <- gsub(pattern = "回族", replacement = "", china_data$NAME)
china_data$NAME <- gsub(pattern = "特别行政区", replacement = "", china_data$NAME)
china_data$NAME <- gsub(pattern = "香港", replacement = "", china_data$NAME)
china_data$NAME <- gsub(pattern = "澳门", replacement = "", china_data$NAME)
#微调名称位置
china_data[is.na(china_data$value),][‘value‘]<-0
china_data[which(china_data$NAME=="河北"&!is.na(china_data$cp1)),‘cp1‘] <- 115.20212
china_data[which(china_data$NAME=="河北"&!is.na(china_data$cp2)),‘cp2‘]<-38.279605
china_data[which(china_data$NAME=="内蒙古"&!is.na(china_data$cp1)),‘cp1‘]<-118.366455
china_data[which(china_data$NAME=="内蒙古"&!is.na(china_data$cp2)),‘cp2‘]<-43.844183
china_data[which(china_data$NAME=="甘肃"&!is.na(china_data$cp1)),‘cp1‘]<-102
china_data[which(china_data$NAME=="甘肃"&!is.na(china_data$cp2)),‘cp2‘]<-39
##绘图
dev.new()
ggplot(china_data,aes(x=long,y=lat,group=group,fill=value))+
geom_polygon(colour="grey40")+ #边界颜色
scale_fill_gradient(low = "white",high = "red")+ #填充方式,这里是2色渐变填充
coord_map("polyconic")+
geom_text(family="font4",aes(x=cp1,y=cp2,label=NAME),colour="black",size=3)+
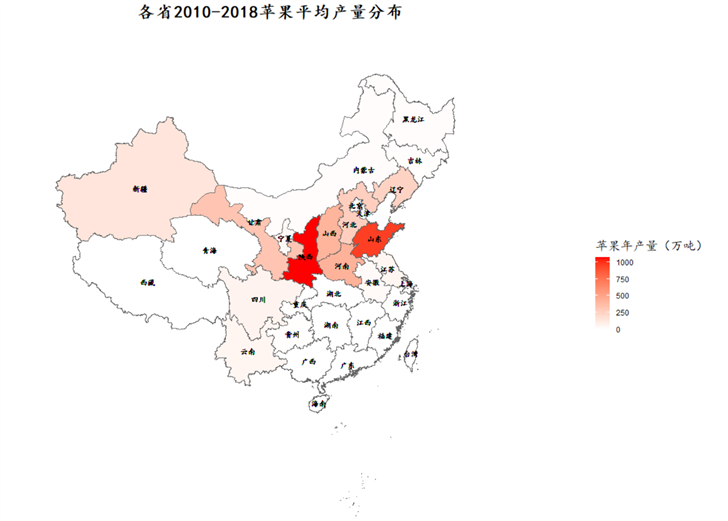
ggtitle("各省2010-2018苹果平均产量分布")+
theme(
plot.title = element_text(family="font4", face="bold",hjust = 0.5,size=20),
panel.grid=element_blank(),
panel.background=element_blank(),
axis.text=element_blank(),
axis.ticks=element_blank(),
axis.title=element_blank()
)+
labs(fill = "苹果年产量(万吨)")+
theme(legend.title = element_text(family="font4",size = 15))原文:https://www.cnblogs.com/lhjc/p/14708587.html