下载
wget https://mirrors.bfsu.edu.cn/apache/spark/spark-3.1.1/spark-3.1.1-bin-hadoop2.7.tgz
解压
tar -vxf spark-3.1.1-bin-hadoop2.7.tgz -C /opt/module/
配置文件改名
cp spark-env.sh.template spark-env.sh
cp workers.template workers
修改配置表
[datalink@slave3 conf]$ vim spark-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_131
export HADOOP_HOME=/opt/module/hadoop-3.1.4
export SCALA_HOME=/opt/module/scala-2.12.13
export HADOOP_CONF_DIR=/opt/module/hadoop-3.1.4/etc/hadoop
export SPARK_MASTER_HOST=slave2
export SPARK_EXECUTOR_MEMORY=1G
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_PORT=7078
export SPARK_MASTER_PORT=7077
[datalink@slave3 conf]$ vim workers
slave1
slave3
slave4
修改启动脚本名称
[datalink@slave3 sbin]$ cp start-all.sh start-spark-all.sh
[datalink@slave3 sbin]$ cp stop-all.sh stop-spark-all.sh
分发到其他服务器
scp -r spark-3.1.1-bin-hadoop2.7/ datalink@slave2:/opt/module/
scp -r spark-3.1.1-bin-hadoop2.7/ datalink@slave1:/opt/module/
scp -r spark-3.1.1-bin-hadoop2.7/ datalink@slave2:/opt/module/
scp -r spark-3.1.1-bin-hadoop2.7/ datalink@slave4:/opt/module/
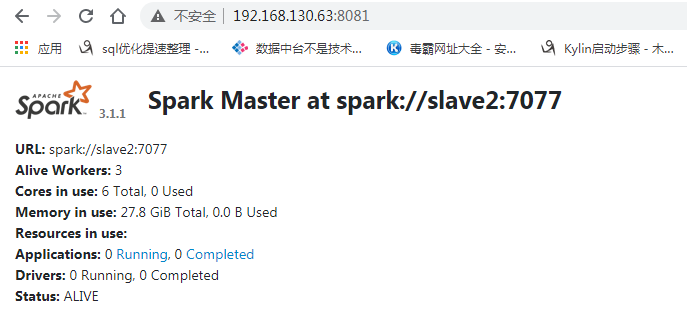
启动
[datalink@slave2 sbin]$ ./start-spark-all.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/module/spark-3.1.1-bin-hadoop2.7/logs/spark-datalink-org.apache.spark.deploy.master.Master-1-slave2.out
slave4: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-3.1.1-bin-hadoop2.7/logs/spark-datalink-org.apache.spark.deploy.worker.Worker-1-slave4.out
slave3: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-3.1.1-bin-hadoop2.7/logs/spark-datalink-org.apache.spark.deploy.worker.Worker-1-slave3.out
slave1: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-3.1.1-bin-hadoop2.7/logs/spark-datalink-org.apache.spark.deploy.worker.Worker-1-slave1.out
[datalink@slave2 sbin]$
原文:https://www.cnblogs.com/playforever/p/14708915.html