今天使用python写了一个简单的爬虫,用来下载taptap网站的游戏截图。下面说下具体的实现方法。
在搜索框中搜索“原神”
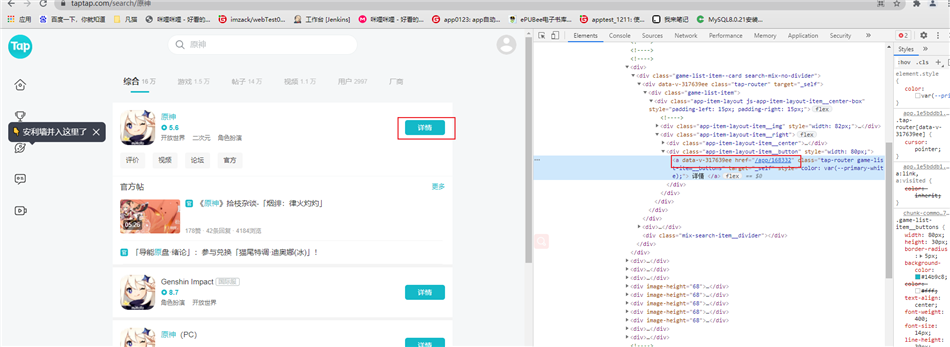
打开浏览器的开发者选项,从详情按钮里面跳转到游戏的页面,点击详情之后,跳转页面
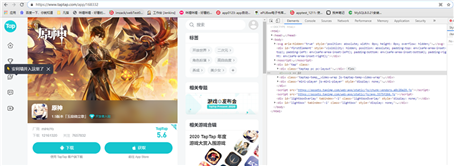
这时候看到,浏览器地址:https://www.taptap.com/app/168332,tap官网的域名加上app/和图一的游戏id,可以使用re模块正则表达式模块从接口中获取到这个id
x_ua = ‘V=1&PN=WebApp&LANG=zh_CN&VN_CODE=4&VN=0.1.0&LOC=CN&PLT=PC&DS=Android&UID=97bb961f-bf03-4c7a-8cd7-8d6d8655d9c8&DT=PC‘ def search(game_name): """根据游戏名搜索提取出游戏id""" url = ‘https://www.taptap.com/webapiv2/mix-search/v1/by-keyword‘ data = { ‘kw‘: f‘{game_name}‘, ‘X-UA‘ : x_ua # ‘X-UA‘: ‘V=1&PN=WebApp&LANG=zh_CN&VN_CODE=4&VN=0.1.0&LOC=CN&PLT=PC&DS=Android&UID=97bb961f-bf03-4c7a-8cd7-8d6d8655d9c8&DT=PC‘ } r = requests.get(url=url, params=data) pattern = re.compile(‘"type":"app","identification":"app:(.+?)"‘, re.S) r1 = pattern.findall(r.text) #从response中提取游戏id return r1[0]
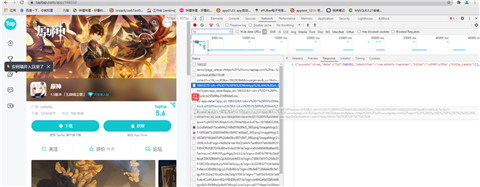
然后打开开发者选项观察接口,可以从这个接口中获取到游戏截图的链接,
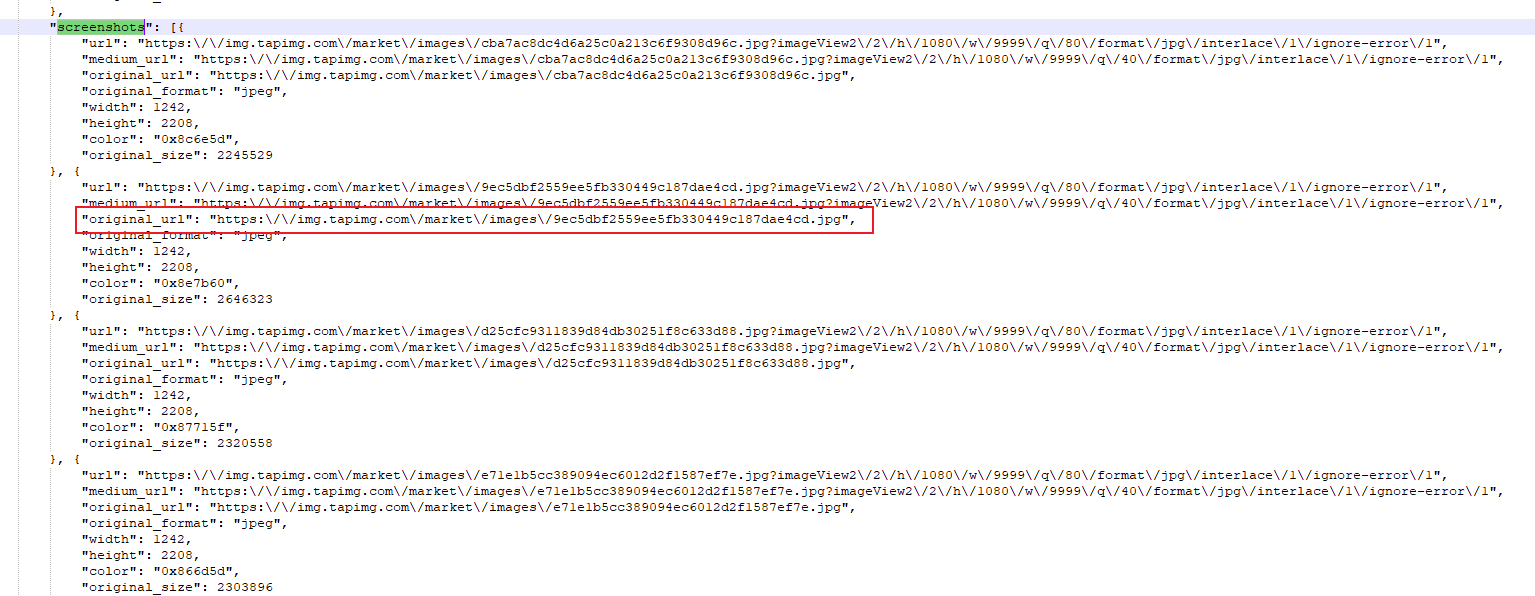
把数据json格式化一下,可以发现在data下,"screenshots"下的“orignal_url”就是截图的链接。使用json.load转换成字典,就可以比较方便的取出内容了。
url = f‘https://www.taptap.com/webapiv2/app/v2/detail-by-id/{search(game_name)}‘ r = requests.get(url=url, params={‘X-UA‘: x_ua}) data = json.loads(r.text) #转换为字典格式 original_url = data.get(‘data‘).get(‘screenshots‘) #提取出截图url
之后使用一个循环将图片保存到本地
for i in original_url: time.sleep(0.5) game_original_url = i.get(‘original_url‘) print(game_original_url, type(game_original_url)) respones = requests.get(game_original_url) img = respones.content file_name = game_original_url[-36: -4] screenshots = os.path.join(os.path.dirname(__file__), f‘screenshots/{game_name}‘) if not os.path.exists(screenshots): os.makedirs(screenshots) file_path = os.path.join(screenshots, file_name) with open(file_path + ‘.png‘, ‘wb‘) as f: f.write(img)
完整代码:
import os import requests import json import re import time x_ua = ‘V=1&PN=WebApp&LANG=zh_CN&VN_CODE=4&VN=0.1.0&LOC=CN&PLT=PC&DS=Android&UID=97bb961f-bf03-4c7a-8cd7-8d6d8655d9c8&DT=PC‘ def search(game_name): """根据游戏名搜索提取出游戏id""" url = ‘https://www.taptap.com/webapiv2/mix-search/v1/by-keyword‘ data = { ‘kw‘: f‘{game_name}‘, ‘X-UA‘ : x_ua # ‘X-UA‘: ‘V=1&PN=WebApp&LANG=zh_CN&VN_CODE=4&VN=0.1.0&LOC=CN&PLT=PC&DS=Android&UID=97bb961f-bf03-4c7a-8cd7-8d6d8655d9c8&DT=PC‘ } r = requests.get(url=url, params=data) pattern = re.compile(‘"type":"app","identification":"app:(.+?)"‘, re.S) r1 = pattern.findall(r.text) #从response中提取游戏id return r1[0] def download_screenshots(game_name): url = f‘https://www.taptap.com/webapiv2/app/v2/detail-by-id/{search(game_name)}‘ r = requests.get(url=url, params={‘X-UA‘: x_ua}) data = json.loads(r.text) #转换为字典格式 original_url = data.get(‘data‘).get(‘screenshots‘) #提取出截图url try: for i in original_url: time.sleep(0.5) game_original_url = i.get(‘original_url‘) print(game_original_url, type(game_original_url)) respones = requests.get(game_original_url) img = respones.content file_name = game_original_url[-36: -4] screenshots = os.path.join(os.path.dirname(__file__), f‘screenshots/{game_name}‘) if not os.path.exists(screenshots): os.makedirs(screenshots) file_path = os.path.join(screenshots, file_name) with open(file_path + ‘.png‘, ‘wb‘) as f: f.write(img) except: print(‘下载失败‘) if __name__ == ‘__main__‘: download_screenshots(‘lol‘)
原文:https://www.cnblogs.com/liuyingjie123/p/14716352.html