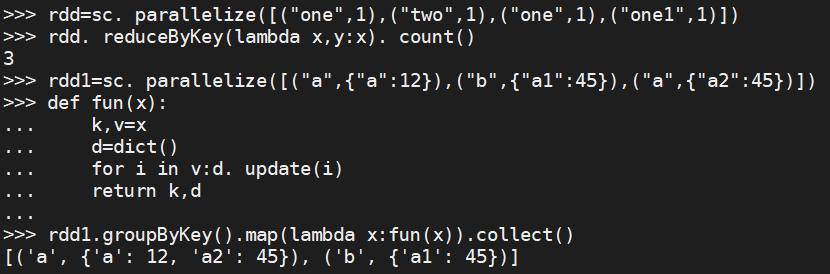
rdd=sc. parallelize([("one",1),("two",1),("one",1),("one1",1)]) rdd. reduceByKey(lambda x,y:x). count() rdd1=sc. parallelize([("a",{"a":12}),("b",{"a1":45}),("a",{"a2":45})]) def fun(x): k,v=x d=dict() for i in v:d. update(i) return k,d rdd1.groupByKey().map(lambda x:fun(x)).collect()
#[(‘a‘, {‘a‘: 12, ‘a2‘: 45}), (‘b‘, {‘a1‘: 45})]
rdd2=sc. parallelize([("a",{"a":13}),("b",{"a1":45}),("a",{"a2":45})]) def fun1(x): k,v=x d=dict() for i in v:d. update(i[1]) return k,d rdd2.groupBy(lambda x:x[0]).map(lambda x:fun1(x)). collect() #[(‘a‘, {‘a‘: 13, ‘a2‘: 45}), (‘b‘, {‘a1‘: 45})] rdd2.keyBy(lambda x:x[0]).collect() #[(‘a‘, (‘a‘, {‘a‘: 13})), (‘b‘, (‘b‘, {‘a1‘: 45})), (‘a‘, (‘a‘, {‘a2‘: 45}))]

x=sc. parallelize([("a",1),("b",4),("b",5),("a",2)])
y=sc. parallelize([("a",3),("c",None)])
x. subtractByKey(y). collect()
#[(‘b‘, 4), (‘b‘, 5)]

pyspark reduceByKey、groupByKey、groupBy、keyBy、subtractByKey 使用
原文:https://www.cnblogs.com/boye169/p/14716265.html