补充下另外两点:
1.ConcurrentHashMap 这个版本之所以高,还有一个非常核心的原因就是:ConcurrentHashMap 的查询get方法是没有加锁的,读是没有锁,写的时候才会涉及到锁。
2.比如hashtable 、Collections.SynchronizedMap无论是读还是写都会加锁,ConcurrentHashMap读上是没有锁的(依赖于Volatile的可见性来解决),再加上ConcurrentHashMap 1.8版本又把锁的粒度降低了,所以在并发的情况下性能较高。
原文:https://www.cnblogs.com/javacd/p/14717315.html
1、hashtable 对所有方法加锁(synchronized),所有线程锁的都是当前对象,锁的粒度太大
2、Collections.SynchronizedMap 锁的是同一个对象,每次锁的都是当前整张表,锁的粒度太大
3、ConcurrentHashMap JDK1.7 分段锁,通过hash计算,在找桶的位置之前,先去找锁的位置(对桶中位置分组的概念),缺点之一,每次确定位置,需要两次hash计算
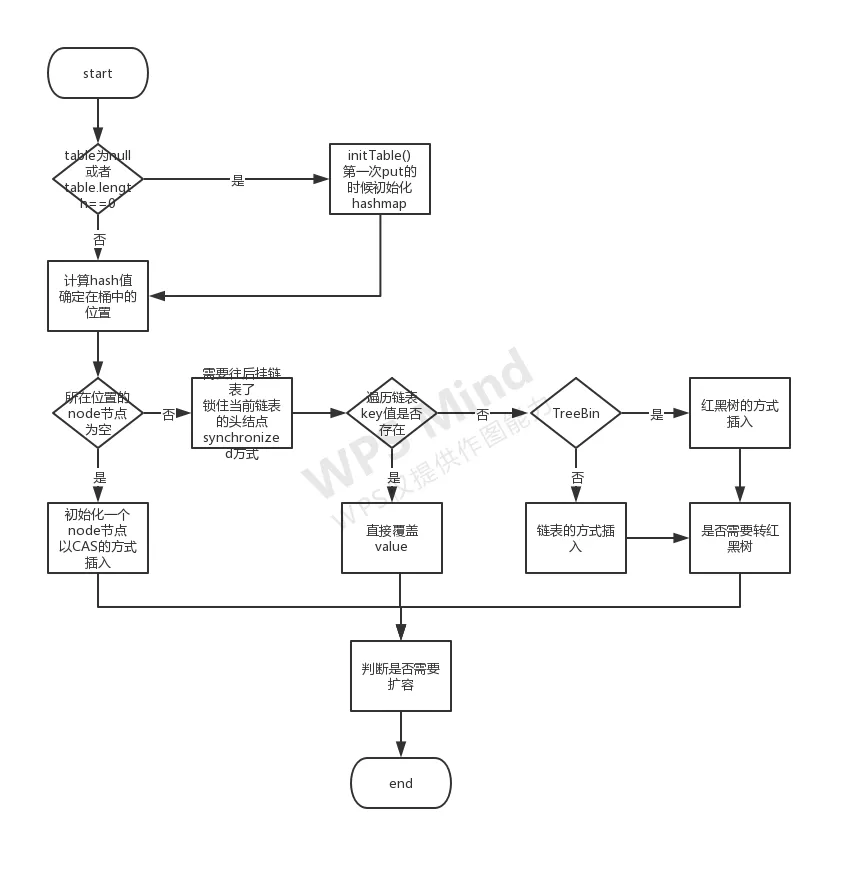
4、ConcurrentHashMap JDK1.8 锁的粒度很小,当发生hash冲突的时候会去加锁,锁的是当前链表的头结点
实现方式:Node数组+CAS(桶中的头结点为空,用cas的方式做插入操作)+Synchronized(hash冲突,往后挂链表的时候加锁)+Volatile(多线程环境之下的可见性)
ConcurrentHashMap JDK1.8 put方法流程图如下: