Kubernetes集群分为一个Master节点和若干Node节点。
Master
Master是Kubernetes 的主节点。
Master组件可以在集群中任何节点上运行。但是为了简单起见,通常在一台虚拟机上启动所有Master组件,并且不会在此VM机器上运行用户容器。
集群所有的控制命令都传递给Master组件,在Master节点上运行。kubectl命令在其他Node节点上无法执行。
Master节点上面主要由四个模块组成:etcd、api server、controller manager、scheduler。
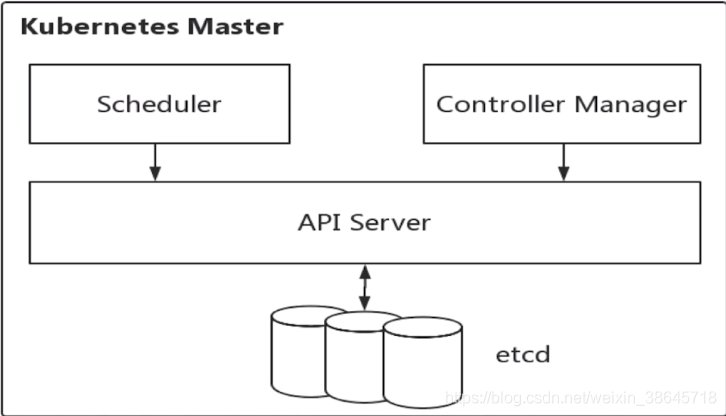
四个组件的主要功能可以概括为:
api server:负责对外提供restful的Kubernetes API服务,其他Master组件都通过调用api server提供的rest接口实现各自的功能,如controller就是通过api server来实时监控各个资源的状态的。
etcd:是 Kubernetes 提供的一个高可用的键值数据库,用于保存集群所有的网络配置和资源对象的状态信息,也就是保存了整个集群的状态。数据变更都是通过api server进行的。整个kubernetes系统中一共有两个服务需要用到etcd用来协同和存储配置,分别是:
1)网络插件flannel,其它网络插件也需要用到etcd存储网络的配置信息;
2)kubernetes本身,包括各种资源对象的状态和元信息配置。
scheduler:监听新建pod副本信息,并通过调度算法为该pod选择一个最合适的Node节点。会检索到所有符合该pod要求的Node节点,执行pod调度逻辑。调度成功之后,会将pod信息绑定到目标节点上,同时将信息写入到etcd中。一旦绑定,就由Node上的kubelet接手pod的接下来的生命周期管理。如果把scheduler看成一个黑匣子,那么它的输入是pod和由多个Node组成的列表,输出是pod和一个Node的绑定,即将这个pod部署到这个Node上。Kubernetes目前提供了调度算法,但是同样也保留了接口,用户可以根据自己的需求定义自己的调度算法。
controller manager:负责维护集群的状态,比如故障检测、自动扩展、滚动更新等。每个资源一般都对应有一个控制器,这些controller通过api server实时监控各个资源的状态,controller manager就是负责管理这些控制器的。当有资源因为故障导致状态变化,controller就会尝试将系统由“现有状态”恢复到“期待状态”,保证其下每一个controller所对应的资源始终处于期望状态。比如我们通过api server创建一个pod,当这个pod创建成功后,api server的任务就算完成了。而后面保证pod的状态始终和我们预期的一样的重任就由controller manager去保证了。
controller manager 包括运行管理控制器(kube-controller-manager)和云管理控制器(cloud-controller-manager)
Kubernetes Master 的架构为:
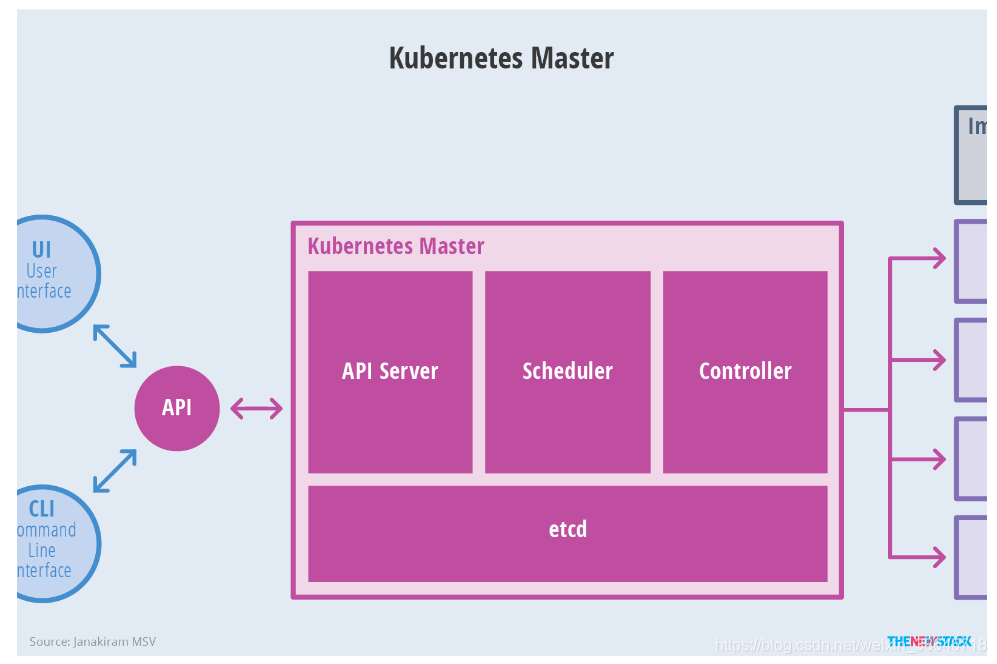
Node
Node上运行着Master分配的pod,当一个Node宕机,其上的pod会被自动转移到其他Node上。
每一个Node节点都安装了Node组件,包括kubelet、kube-proxy、container runtime。
kubelet 会监视已分配给节点的pod,负责pod的生命周期管理,同时与Master密切协作,维护和管理该Node上面的所有容器,实现集群管理的基本功能。即Node节点通过kubelet与master组件交互,可以理解为kubelet是Master在每个Node节点上面的agent。本质上,它负责使Pod的运行状态与期望的状态一致。
kube-proxy 是实现service的通信与负载均衡机制的重要组件,将到service的请求转发到后端的pod上。
Container runtime:容器运行环境,目前Kubernetes支持docker和rkt两种容器。
Node 的架构为:
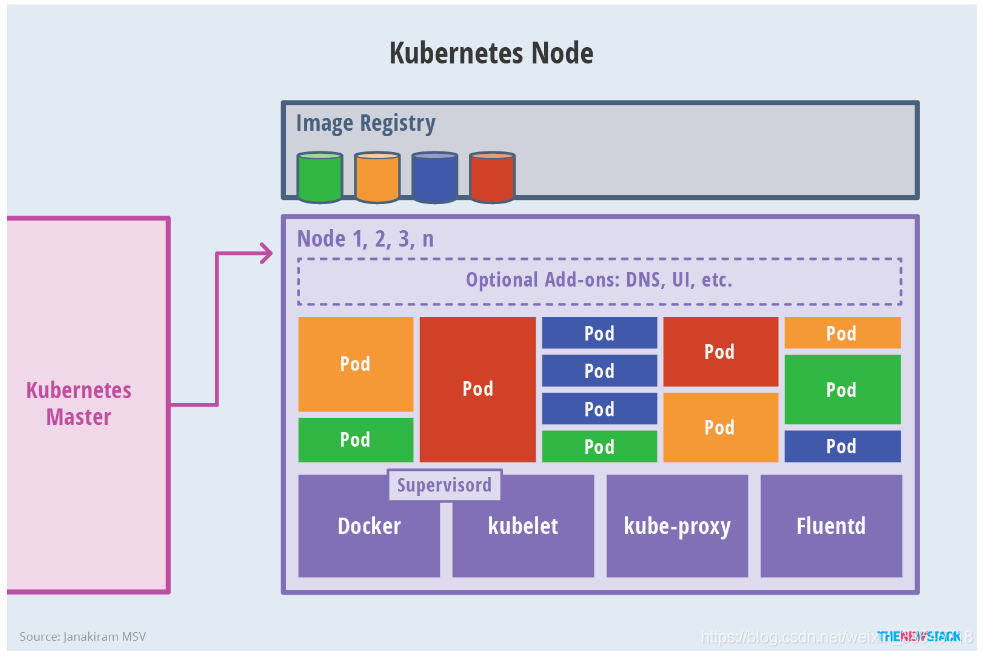
通常不会在Master节点上运行任何用户容器,Node从节点才是真正运行工作负载的节点。
整体架构如下:
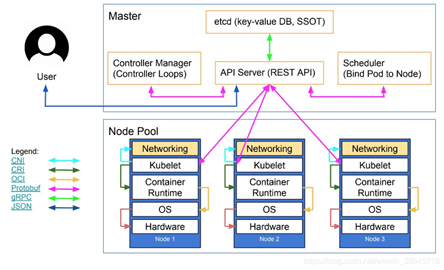
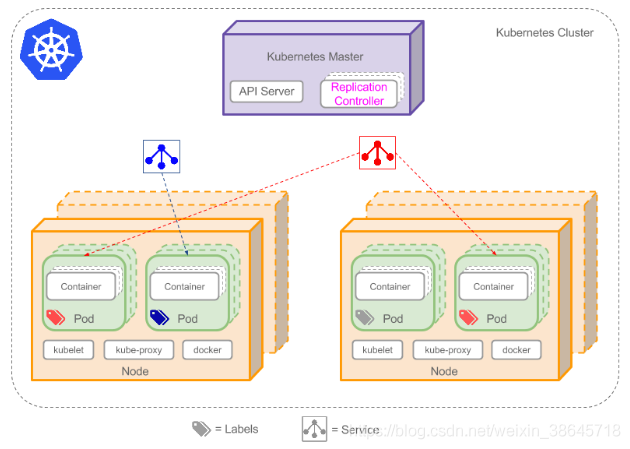
抽象后的架构为:
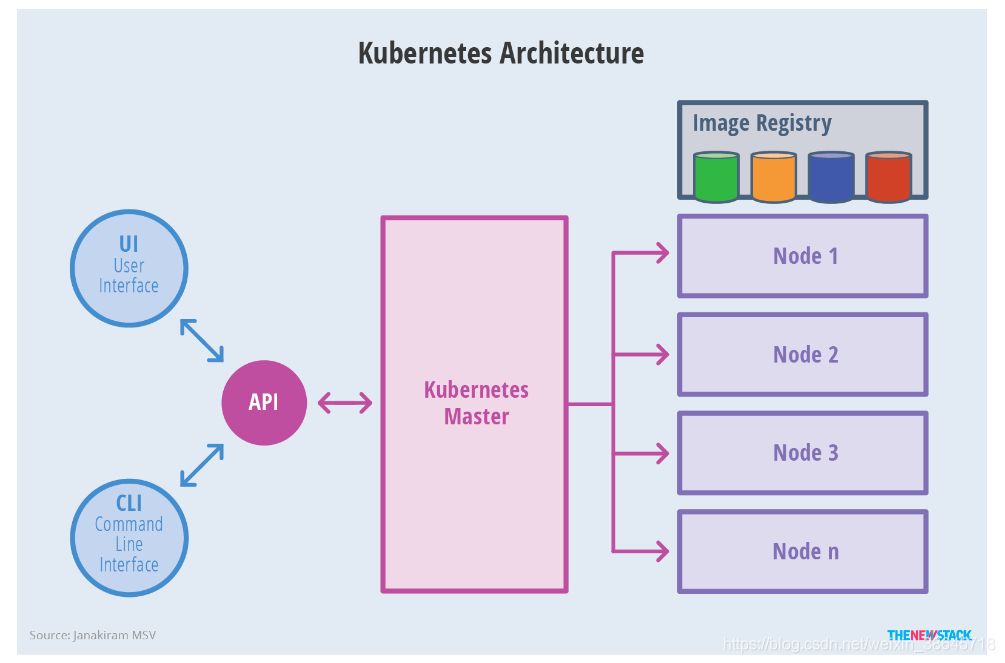
除了核心组件,还有一些推荐的Add-ons:
原文:https://www.cnblogs.com/neteagles/p/14723569.html