神经网络与机器学习
第12章 支持向量机
§12.1 绪论
支持向量机(support vector machines, SVM)是二分类模型,定义位特征空间上间隔最大的线性分类器,引入核函数,SVM也包含了非线性分类器,其学习策略是间隔最大化,可以化成一个凸二次规划问题。 SVM更关心的是靠近中间分割线的点,让他们尽可能地远离中间线,而不是在所有点上达到最优。
§12.2 线性可分SVM
二分类问题,输入空间和特征空间是两个不同空间,特征空间可以为欧氏空间或者希尔伯特空间,假设两个空间一一对应。
定义:线性可分支持向量机,给定线性可分数据集
是实向量,而是标签,取值{+1,-1},通过间隔最大或者凸二次规划学习的分离两类的超平面位
分类决策函数
,
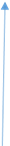
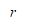
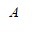
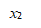

 超平面例子
超平面例子
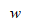


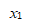
图 12.1 超平面
定义:函数间隔与几何间隔。假定对于一个点A,令其垂直投影到超平面上的对应点为 x0 ,w 是垂直超平面向量,r为样本点A到超平面的距离,如图12.1所示。
几何间隔和函数间隔:那么A点到超平面的垂直距离设为(只是大小),按照方向和几何关心,A点的向量表示
在超平面上,所以肯定满足,那么得到,那么上式同时乘以
得到
而点A可能在正的一侧,也可能在负的一侧,所以几何间隔应该乘以分类,定义为
其中
称为函数间隔,几何间隔与函数间隔就是差范数,这样能够避免成比例改变w和b造成的函数间隔缩扩。
间隔最大化:
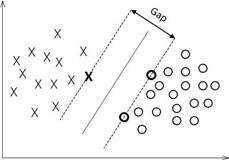
线性可分数据集有很多分离超平面,但是几何间隔最大的超平面是唯一的,又称为硬间隔最大化。因此,可以表示为下面约束最优化问题
求几何间隔最大就是函数间隔最大
注意可以等价为最小化,而把固定,因此成为
这样变成了一个凸二次规划问题,因为是凸函数,约束是仿射函数。
间隔最大分离平面的存在唯一性:
定理: 如训练集线性可分,那么把训练集和中样本点完全正确分开的最大间隔分类超平面存在且唯一。
证明:存在性。凸优化肯定有解,而且w=0不是最优解,因为训练数据有正有负,所以,因此肯定存在。
唯一性:假设存在两个最优解,,显然最小值都满足
因此取等号,必有,负号不是解,所以解唯一。因此,两个最优解,,还有证明偏置相等,设是集合中分别满足,不等式成立两个点,而是集合的两个点,那么有
因此得到
因此得到
又因为
因此,同理,所以。
支持向量和间隔边界:
支持向量:训练数据集中样本点与分离超平面最近的样本点是支持向量,而支持向量是使得约束条件等号成立
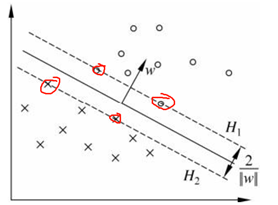
上图H1和H2两个平面上的点就是支持向量,二者距离称为间隔,二者平行,所以间隔大小等于。
支持向量非常少,因此支持向量机由少数重要的训练样本组成的。改变支持向量以外的点不改变解,但是增减支持向量将会改变。
§12.3 线性支持向量机学习的对偶法
例子:如图所示的训练数据集,正样本点,,负样本点。那么构成了如下优化问题
求解得到超平面
下面引用对偶算法,一是对偶算法有时候比上面原优化问题好解决,二是可以自然引入核方法,推广到非线性分类问题。
对偶算法求
首先构建Lagrange函数,对于每一个约束都引入一个Lagrange乘子
根据对偶性,原始问题的对偶问题是
因此首先求最小
将,且由于,得到
其次对于Lagrange乘子求最大
s.t.
也等价于对偶问题
s.t.
定理:设为上面对偶问题的解,则存在下标
求得原始最优化问题的解,KKT条件
至少存在一个,对于此下标
将代入得到
因此超平面为
而且支持向量一定在间隔边界上,所以满足
例子:正样本点,,负样本点。
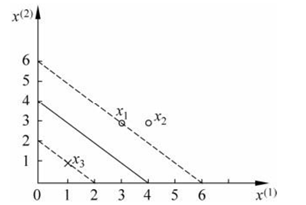
解:根据数据,得到
s.t.
解得,代入
得到解
不满足约束条件,因此寻找边界点。发现解
因此发现
,
是支持向量。
超平面是
§12.4 软间隔最大化
上面的学习算法对应线性不可分问题是不适用的,约束不在成立。这里利用软间隔最大化,则可以解决线性不可分问题。
给定特征空间上的训练数据集
是实向量,而是标签,取值{+1,-1}。数据集中总是有些特异点(outlier),将这些造成线性不可分的问题的特异点去除,则剩下的大部分点是线性可分的。
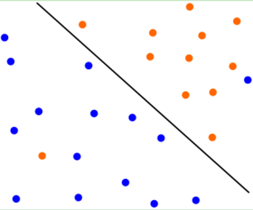
第一种黄蓝各自都有一个数据异常
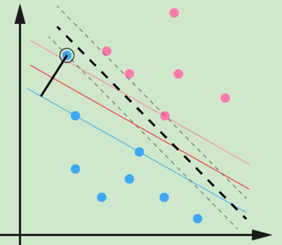
第二种 改变了分离平面的异常点
异常点造成线性不可分,因为异常点不满足函数间隔大于等于1的约束条,为了解决不可分问题,对训练集里面的每个样本引入了一个松弛变量,使函数间隔加上松弛变量大于等于1,约束条件变成
对比硬间隔最大化,可以看到我们对样本到超平面的函数距离的要求放松了,之前是一定要大于等于1,现在只需要加上一个大于等于0的松弛变量能大于等于1就可以了。松弛变量加入有成本的,每一个松弛变量 对应了一个代价,这样优化目标函数从,变成了
C>0为惩罚参数,可以理解为分类问题正则化时候的参数。C越大,对误分类的惩罚越大,C越小,对误分类的惩罚越小。因此目标函数即希望尽量小,间隔最大,同时使得误分类的点尽可能的少,C是协调两者关系的参数。
因此我们把下面的凸二次规划问题称为软间隔最大化:
构建Lagrange函数
根据对偶性,原始问题的对偶问题是
因此首先求最小
上面都代入,因此得到
再对求极大,就是求下面极小
s.t.
利用,,可以写成
s.t.
定理:若存在一个分量,原始问题的解为
证明:由KKT条件
若存在一个分量,则
那么
得到
即
支持向量:在线性不可分的情况下,对偶问题中对应的样本点称为软间隔的支持向量。情况更加复杂,分割平面是实线,边界是虚线。
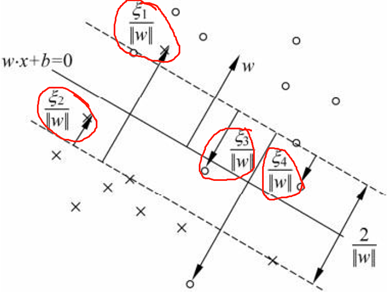
这些支持向量或者在边界上,或者在边界内或外
若,,则正好在边界上,称为支持向量,
若,, 此时分类正确,在边界之间,
若,, 此时在超平面上
若,, 此时位于超平面的另一侧,误分的一侧
上面解释的线性支持向量机,学习策略是软间隔最大化,分离超平面是,学习算法是凸二次规划。
线性支持向量机另外一个解释就是最小化目标函数
第一项是经验风险函数,又称为合页损失函数,下标+表示取正值
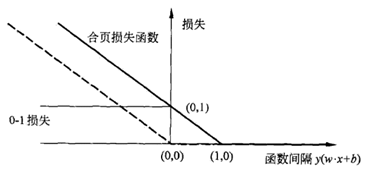
也就是说当样本点被正确分类,且函数间隔时,损失为0,否则损失就是。而第二项就是正则化项。
定理:线性支持向量机优化问题
等价于
证明:令
因此当
当
所以约束条件成立
这和原问题的约束条件是一致的,优化问题等价于
0-1损失函数是真正的二分类损失函数,合页损失函数是其上界,但是0-1损失函数不是连续可导的,直接优化困难,所以选择优化0-1损失上界--合页损失函数。合页损失函数不仅要求分类正确,还要确信度足够高损失才是0,对于学习要求更加高。
§12.5 非线性支持向量机与核函数
线性可分问题,支持向量机非常有效,但是非线性分类问题则需要引入核函数。如下图
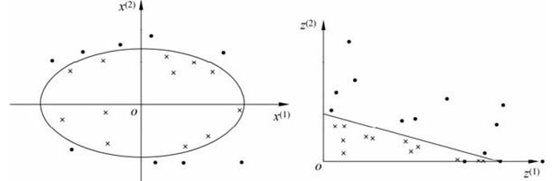
非线性分类问题是指通过利用非线性模型才能很好地进行分类的问题。如左图,是一个分类问题,图中"·"表示正实例点,"×"表示负实例点。由图可见,
无法用直线(线性模型)将正负实例正确分开,但可以用一条椭圆曲线(非线性模型)将它们正确分开。非线性问题往往不好求解,所以希望能用解线性分类问题的方法解决这个问题。所采取的方法是进行一个非线性变换,将非线性问题变换为线性问题,通过解变换后的线性问题的方法求解原来的非线性问题。对图中所示的例子,通过变换,将左图中椭圆变换成右图中的直线,将非线性分类问题变换为线性分类问题。
设原空间为,,新空间为,,定义从原空间到新空间的变换(映射):
经过变换,原空间变换为新空间,原空间中的点相应地变换为新空间中的点,原空间中的椭圆变换成为新空间中的直线。在变换后的新空间里,直线可以将变换后的正负实例点正确分开。这样,原空间的非线性可分问题就变成了新空间的线性可分问题。
上面的例子说明,用线性分类方法求解非线性分类问题分为两步:首先使用一个变换将原空间的数据映射到新空间;然后在新空间里用线性分类学习方法从训练数据中学习分类模型。核技巧就属于这样的方法。
核技巧应用到支持向量机:基本想法就是通过一个非线性变换将输入空间(欧氏空间或离散集合)对应于一个特征空间(希尔伯特空间),使得在输入空间中的超曲面模型对应于特征空间中的超平面模型(支持向量机)。这样,分类问题的学习任务通过在特征空间中求解线性支持向量机就可以完成。
核函数:设欧式空间或离散集合,有特征空间(希尔伯特空间),存在一个映射
对于所有的, 函数满足
则称为核函数,是映射函数,是二者内积。
核技巧的想法是,在学习与预测中只定义核函数,而不显式地定义映射函数。通常,直接计算比较容易,而通过和计算并不容易。注意,是输入空间到特征空间的映射,特征空间一般是高维的,甚至是无穷维的。可以看到,对于给定的核,特征空间和映射函数的取法并不唯一,可以取不同的特征空间,即便是在同一特征空间里也可以取不同的映射。下面举一个简单的例子来说明核函数和映射函数的关系。
例子:设输入空间为,核函数
如果取特征空间, 由于
所以映射可以选取
如果取特征空间, 映射可以选取
核函数的应用:
我们注意到在线性支持向量机的对偶问题中,无论是目标函数还是决策函数(分离超平面)都只涉及输入实例与实例之间的内积。在对偶问题的目标函数中的内积可以用核函数
来代替。此时对偶问题的目标函数成为
分类决策函数中的内积也可以用核函数代替,而分类决策函数式成为
这等价于经过映射函数将原来的输入空间变换到一个新的特征空间,将输入空间中的内积变换为特征空间中的内积,在新的特征空间里从训练样本中学习线性支持向量机。当映射函数是非线性函数时,学习到的含有核函数的支持向量机是非线性分类模型。也就是说,在核函数给定的条件下,可以利用解线性分类问题的方法求解非线性分类问题的支持向量机。学习是隐式地在特征空间进行的,不需要显式地定义特征空间和映射函数。这样的技巧称为核技巧,它是巧妙地利用线性分类学习方法与核函数解决非线性问题的技术。在实际应用中,往往依赖领域知识直接选择核函数,核函数选择的有效性需要通过实验验证。
正定核
已知映射函数的内积求得核函数不用构造映射能否直接判断一个给定的函数是不是核函数?或者说,函数满足什么条件才能成为核函数?
本节叙述正定核的充要条件。通常所说的核函数就是正定核函数(positive definite kernel function)。为证明此定理先介绍有关的预备知识。
假设是对称函数,并且对任意的,关于的Gram矩阵是半正定的。可以依据函数,构成一个希尔伯特空间(Hilbert space),其步骤是:首先定义映射并构成向量空间;然后在上定义内积构成内积空间;最后将完备化构成希尔伯特空间。
1.定义映射,构成向量空间
先定义映射
根据这一映射,对任意,, i=1,2,…,m,定义线性组合
考虑由线性组合为元素的集合S。由于集合S对加法和数乘运算是封闭的,所以构成一个向量空间。
2.在S上定义内积,使其成为内积空间
比如
Gram矩阵是半正定的。
3.将内积空间完备化为希尔伯特空间
现在将内积空间完备化。由式内积可以得到范数
因此, 是一个赋范向量空间。根据泛函分析理论,对于不完备的赋范向量空间,一定可以使之完备化,得到完备的赋范向量空间。一个内积空间,当作为一个赋范向量空间是完备的时候,就是希尔伯特空间。这一希尔伯特空间称为再生核希尔伯特空间(reproducing kernel Hilbert space,RKHS)。这是由于核具有再生性,即满足
及
称为再生核。
4.正定核的充要条件
定理7.5(正定核的充要条件) 设K: X→R是对称函数,则为正定核函数的充要条件是对任意,关于的Gram矩阵是半正定的。对应的Gram矩阵
这一定义在构造核函数时很有用。但对于一个具体函数来说,检验它是否为正定核函数并不容易,因为要求对任意有限输入集验证对应的Gram矩阵是否为半正定的。在实际问题中往往应用已有的核函数。下面介绍一些常用的核函数。
多项式核函数:
高斯核函数:
字符核函数:还可以定义在离散数据集合,在文本分类、信息检索方面应用广泛。
https://www.cnblogs.com/yifanrensheng/p/12354948.html
《统计学习》,李航
§12.6 非线性支持向量机的序列最小优化算法
我们知道,支持向量机的学习问题可以形式化为求解凸二次规划问题。这样的凸二次规划问题具有全局最优解,并且有许多最优化算法可以用于这一问题的求解。但是当训练样本容量很大时,这些算法往往变得非常低效,以致无法使用。所以,如何高效地实现支持向量机学习就成为一个重要的问题。目前人们已提出许多快速实现算法。本节讲述其中的序列最小最优化(sequential minimaloptimization,SMO)算法,这种算法1998年由Platt提出。
SMO算法就是求解凸二次规划的对偶问题
s.t.
是拉格朗日乘子,每个对应一个样本点。
SMO算法是启发式算法,,其基本思路是:如果所有变量的解都满足此最优化问题的KKT条件,那么这个最优化问题的解就得到了。因为KKT条件是该最优化问题的充分必要条件。否则,选择两个变量,固定其他变量,针对这两个变量构建一个二次规划问题。这个二次规划问题关于这两个变量的解应该更接近原始二次规划问题的解,因为这会使得原始二次规划问题的目标函数值变得更小。重要的是,这时子问题可以通过解析方法求解,这样就可以大大提高整个算法的计算速度。子问题有两个变量,一个是违反KKT条件最严重的那一个,另一个由约束条件自动确定。如此,SMO算法将原问题不断分解为子问题并对子问题求解,进而达到求解原问题的目的。
注意,子问题的两个变量中只有一个是自由变量。假设为两个变量,其他乘子固定,那么由等式约束可知
所以子问题中同时更新两个变量。整个SMO算法包括两个部分:求解两个变量二次规划的解析方法和选择变量的启发式方法。
两个变量二次规划的求解方法不失一般性,假设选择的两个变量是其他变量是固定的。于是SMO的最优化问题的子问题可以写成:
s.t.
是个常数。省掉很多不含的常数项。
由于只有两个变量,所以约束可以表示为平面区域
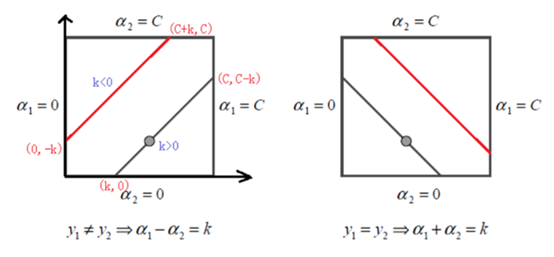
约束限制了目标函数在平行对角线的直线上寻优,所以实质是单变量优化问题,那么
当时,,所以给定一组旧的可行解,和新的可行解都满足
那么
得出
也是
因此所在对角线端点的界为
同理,当时,,所以给定一组旧的可行解,和新的可行解,所在对角线端点的界为
定理:记
令
表示输入的预测值和标签的差。
利用
代入,则只是成了的二次函数优化问题了,那么利用
得到
又注意到边界,所以
SMO算法在每个子问题中选择两个变量优化,其中至少一个变量是违反KKT条件的。
1.第1个变量的选择
SMO称选择第1个变量的过程为外层循环。外层循环在训练样本中选取违反KKT条件最严重的样本点,并将其对应的变量作为第1个变量。
2.第2个变量的选择
SMO称选择第2个变量的过程为内层循环。第2个变量选择的标准是希望能使有足够大的变化。
Matlab 二分类支持项
>> load fisheriris
inds = ~strcmp(species,‘setosa‘);
X = meas(inds,3:4);
y = species(inds);
>> SVMModel = fitcsvm(X,y)
SVMModel =
ClassificationSVM
ResponseName: ‘Y‘
CategoricalPredictors: []
ClassNames: {‘versicolor‘ ‘virginica‘}
ScoreTransform: ‘none‘
NumObservations: 100
Alpha: [24×1 double]
Bias: -14.4149
KernelParameters: [1×1 struct]
BoxConstraints: [100×1 double]
ConvergenceInfo: [1×1 struct]
IsSupportVector: [100×1 logical]
Solver: ‘SMO‘
>> sv = SVMModel.SupportVectors;
figure
gscatter(X(:,1),X(:,2),y)
hold on
plot(sv(:,1),sv(:,2),‘ko‘,‘MarkerSize‘,10)
legend(‘versicolor‘,‘virginica‘,‘Support Vector‘)
hold off
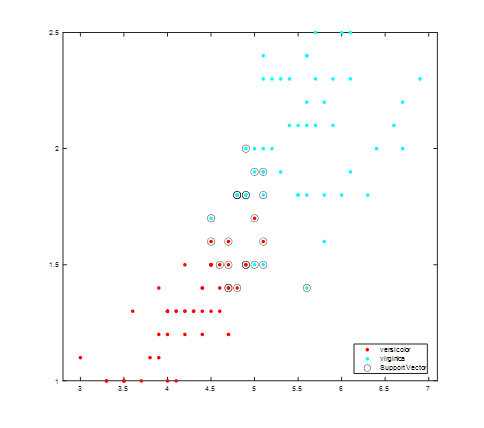
支持向量
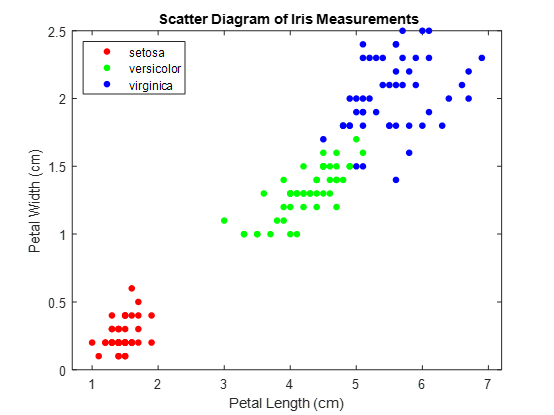
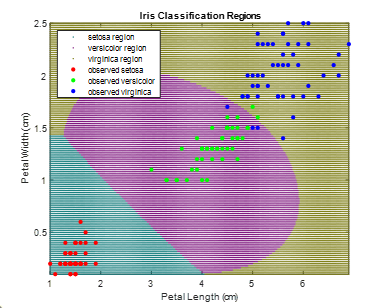
load fisheriris
X = meas(:,3:4);
Y = species;
figure
gscatter(X(:,1),X(:,2),Y);
h = gca;
lims = [h.XLim h.YLim]; % Extract the x and y axis limits
title(‘{\bf Scatter Diagram of Iris Measurements}‘);
xlabel(‘Petal Length (cm)‘);
ylabel(‘Petal Width (cm)‘);
legend(‘Location‘,‘Northwest‘);
SVMModels = cell(3,1);
classes = unique(Y);
rng(1); % For reproducibility
for j = 1:numel(classes)
indx = strcmp(Y,classes(j)); % Create binary classes for each classifier
SVMModels{j} = fitcsvm(X,indx,‘ClassNames‘,[false true],‘Standardize‘,true,...
‘KernelFunction‘,‘rbf‘,‘BoxConstraint‘,1);
end
d = 0.02;
[x1Grid,x2Grid] = meshgrid(min(X(:,1)):d:max(X(:,1)),...
min(X(:,2)):d:max(X(:,2)));
xGrid = [x1Grid(:),x2Grid(:)];
N = size(xGrid,1);
Scores = zeros(N,numel(classes));
for j = 1:numel(classes)
[~,score] = predict(SVMModels{j},xGrid);
Scores(:,j) = score(:,2); % Second column contains positive-class scores
end
[~,maxScore] = max(Scores,[],2);
figure
h(1:3) = gscatter(xGrid(:,1),xGrid(:,2),maxScore,...
[0.1 0.5 0.5; 0.5 0.1 0.5; 0.5 0.5 0.1]);
hold on
h(4:6) = gscatter(X(:,1),X(:,2),Y);
title(‘{\bf Iris Classification Regions}‘);
xlabel(‘Petal Length (cm)‘);
ylabel(‘Petal Width (cm)‘);
legend(h,{‘setosa region‘,‘versicolor region‘,‘virginica region‘,...
‘observed setosa‘,‘observed versicolor‘,‘observed virginica‘},...
‘Location‘,‘Northwest‘);
axis tight
hold off
fitcecoc
Fit multiclass models for support vector machines or other classifiers
原文:https://www.cnblogs.com/Prof-Loser/p/14728070.html