内容概要
一、直接寻址表
二、哈希函数与哈希表
三、哈希冲突问题与解决
四、哈希的应用
1、直接寻址表
直接寻址表就是一种唯一的对应关系,它常用于字典中
存在一个全域U,它存储所有可能出现的键的名称;并且存在一个用于存储实际值的列表,全域U中存在的每一个键都与这个列表的下标唯一对应
比如
dic = { ‘1‘: ‘zhangsan‘, ‘2‘: 18, ‘3‘: ‘man‘, }
上面的字典对应的图解如下
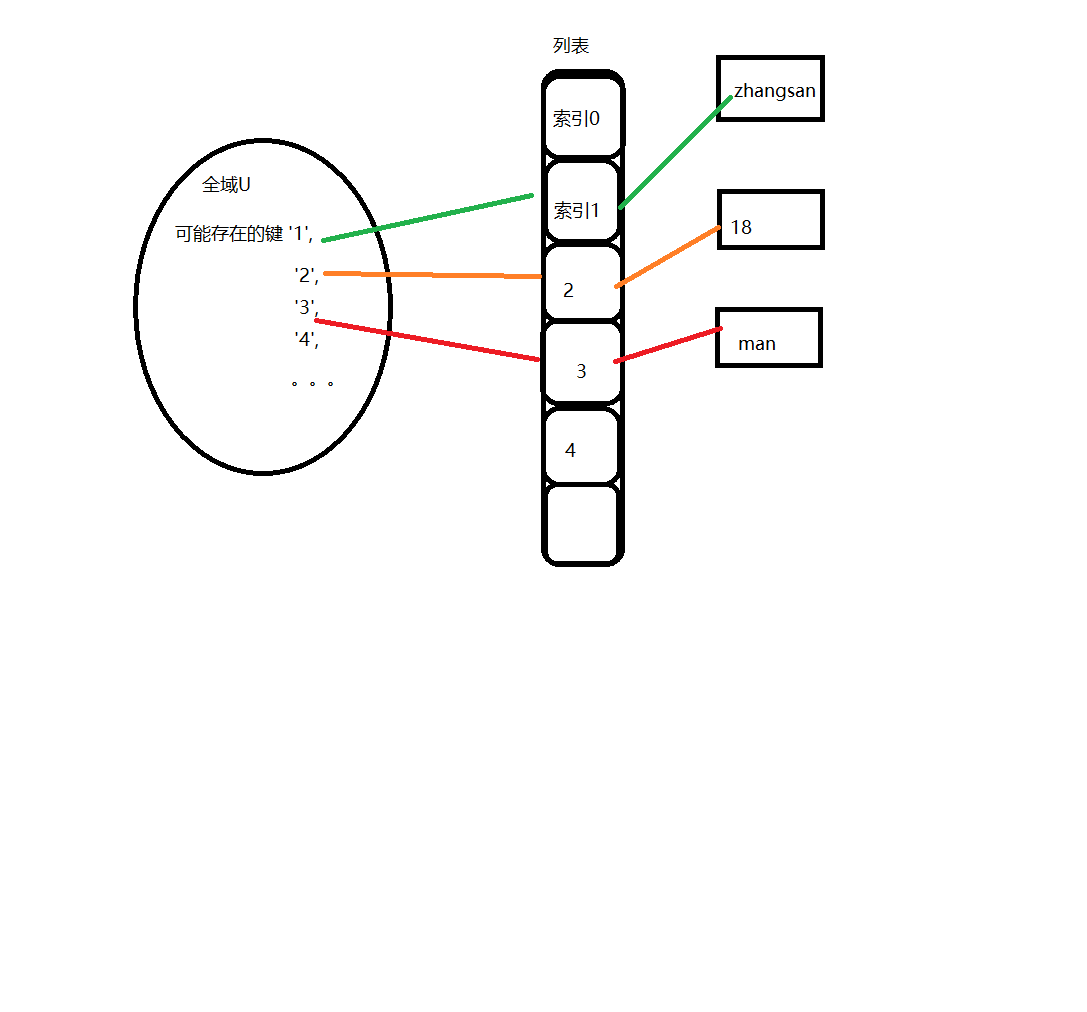
直接寻址表可以理解为在列表的基础上,再套上一层键对应索引的关系
这种对应关系可以实现键对应值(通过索引间接实现),它查找的效率也能快
但是也存在几个问题
(1)可能存在的键数量极大,全域U不可能包含所有的键
(2)"1" 可以对应索引1, 但是 "name" 的键如何对应列表索引
2、哈希函数和哈希表
为了解决直接寻址表中出现的问题,就出现了哈希函数和哈希表
哈希函数可以理解为一种将键映射为列表索引的对应关系
键 —— 哈希函数 —— 列表对应的索引
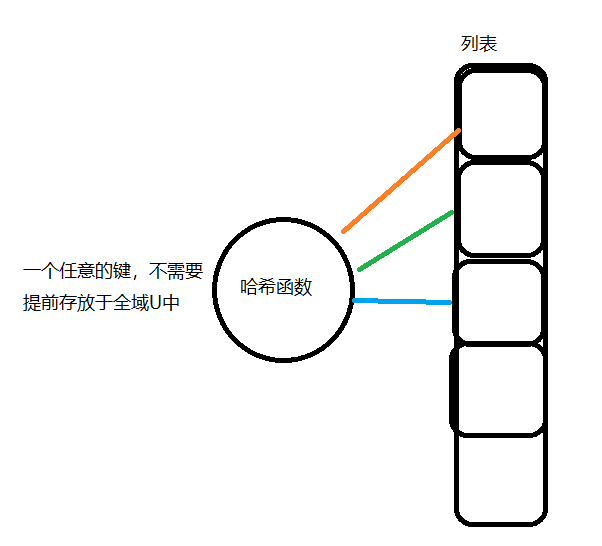
比如取余函数就可以是一个简单的哈希函数
def my_hash(num): return num % 10 # 返回键对应的列表的下标
于是,就可以使用一个长度为10的列表,将所有的数值键对应起来,而无需像直接寻址表那样需要一个很大的列表与全域U中的可能键一一对应
3、哈希冲突问题和解决
哈希冲突问题
在取余函数中可能会出现这样的问题,键"9"与键"19"通过哈希函数映射后的值都为9。列表的一个索引要对应两个键,这里就发生了哈希冲突
任何哈希函数都会发生哈希冲突,这是由于哈希函数将无数的键映射为有限的列表下标,必然会产生冲突
哈希冲突解决
哈希冲突解决有两种思路,一种是开放寻址法解决
如果当一个位值i有键了,那么可以使用
线性探查:依次查找i+1,i+2,i+3的位置是否有键,如果没有,则把键存放到这里(不仅存放时会后移,查找时也要重复存放时的后移过程,效率不高)
二度探查:依次查找i+1**2, i-1**2, i+2**2, i-2**2的位置是否有键,如果没有,则把键存放到这里
二度哈希:如果依次哈希得到的索引已经有键,那么可以使用第二个哈希函数对应一个新的索引地址。如果仍被占用,就再哈希
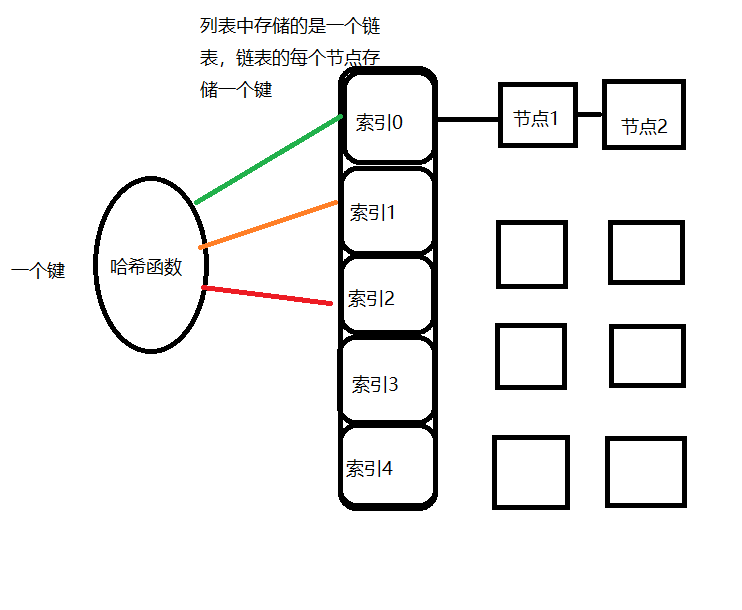
另一种方法是使用拉链法。
使用拉链法,就能做到一个索引对应多个键
copy的大佬的代码
class LinkList: class Node: def __init__(self, key=None): self.key = key self.next = None class LinkListIterator: def __init__(self, node): self.node = node def __next__(self): if self.node: cu_node = self.node self.node = self.node.next return cu_node.key else: raise StopIteration def __iter__(self): return self def __init__(self, iterable=None): self.head = None self.tail = None if iterable: self.extend(iterable) def add(self, key=None): node = self.Node(key) if self.head: self.tail.next = node self.tail = node else: self.head = node self.tail = node def extend(self, iterable): for obj in iterable: self.add(obj) def find(self, k): for i in self: if k == i: return True def __iter__(self): return self.LinkListIterator(self.head) # def __repr__(self): # return "<<" + ",".join(map(str, self)) + ">>" def __str__(self): return "<<" + ",".join(map(str, self)) + ">>" class MyHash: def __init__(self, max_len=100): self.max_len = max_len self.li = [LinkList() for _ in range(self.max_len)] @staticmethod def my_hash(k): return k % 100 def has_element(self, has_v, k): return self.li[has_v].find(k) def add(self, k): hash_v = self.my_hash(k) if self.has_element(hash_v, k): print("已经有这个数了!") else: self.li[hash_v].add(k) obj = MyHash() obj.add(1) obj.add(2) obj.add(101) for link_list in obj.li: print(link_list, end=‘ ‘)
使用拉链法时要注意,不要使得每条拉链的长度过长,否则会拖慢查找时的速度,要达成这个目标,哈希函数就要设计得合理
4、哈希的应用
哈希的最常见应用
首先是实现python自生的字典还有集合
其次是文件校验
最后是密码加密
***待补充***
原文:https://www.cnblogs.com/laijianwei/p/14642791.html