为了系统性能的提升,我们一般都会将部分数据放入缓存中,加速访问。而传统数据库只是作为数据的持久化存储。
哪些数据适合放入缓存?
例如:电商类应用,商品分类,商品列表等适合缓存并加一个失效时间(根据数据更新频率
来定),后台如果发布一个商品,买家需要 5 分钟才能看到新的商品一般还是可以接受的。
注意:在开发中,凡是放入缓存中的数据我们都应该指定过期时间,使其可以在系统即使没
有主动更新数据也能自动触发数据加载进缓存的流程。避免业务崩溃导致的数据永久不一致
问题。
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中,将去查询数据库,但是数据库也无此记录,我们没有将这次查询的 null 写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
缺陷:
? 在流量大时,可能 DB 就挂掉了,要是有人利用不存在的 key 频繁攻击我们的应用,这就是漏洞。
解决:
缓存空结果并且设置短的过期时间。
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到 DB,DB 瞬时压力过重导致雪崩。
解决:
原有的失效时间基础上增加一个随机值,比如 1-5 分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
对于一些设置了过期时间的 key,如果这些 key 可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:如果这个 key 在大量请求同时进来前正好失效,那么所有对这个 key 的数据查询都落到 db,我们称为缓存击穿。
解决:
加锁,大量并发请求只让一个请求去查询,其他请求等待,查询完成后释放锁,其他请求获取到锁之后就去查询缓存,就不会再去访问db了
本地锁、分布式锁:
本地锁的意义
在单进程的系统中,当存在多个线程可以同时改变某个变量(可变共享变量)时,就需要对变量或代码块做同步,使其在修改这种变量时能够线性执行,以防止并发修改变量带来数据不一致或者数据污染的现象。
?而为了实现多个线程在一个时刻同一个代码块只能有一个线程可执行,那么需要在某个地方做个标记,这个标记必须每个线程都能看到,当标记不存在时可以设置该标记,其余后续线程发现已经有标记了则等待拥有标记的线程结束同步代码块取消标记后再去尝试设置标记。这个标记可以理解为锁。分布式锁的意义
如果是单机情况下(单服务),线程之间共享内存,只要使用线程锁就可以解决并发问题。但如果是分布式情况下(多服务),线程A和线程B很可能不是在同一JVM中,这样线程锁就无法起到作用了,这时候就要用到分布式锁来解决。
分布式锁是控制分布式系统同步访问共享资源的一种方式。
分布式锁基本原理:
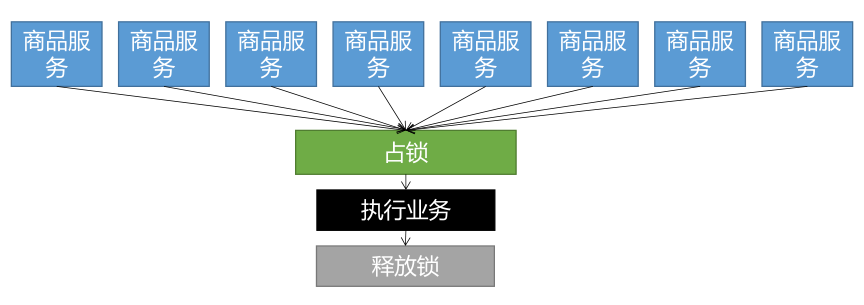
我们可以同时去一个地方“占坑”,如果占到,就执行逻辑。否则就必须等待,直到释放锁。
“占坑”可以去redis,可以去数据库,可以去任何大家都能访问的地方。
等待可以自旋的方式。
Redisson 是架设在 Redis 基础上的一个 Java 驻内存数据网格(In-Memory Data Grid)。充分的利用了 Redis 键值数据库提供的一系列优势,基于 Java 实用工具包中常用接口,为使用者提供了一系列具有分布式特性的常用工具类。使得原本作为协调单机多线程并发程序的工具包获得了协调分布式多机多线程并发系统的能力,大大降低了设计和研发大规模分布式系统的难度。同时结合各富特色的分布式服务,更进一步简化了分布式环境中程序相互之间的协作。
官方文档
整合:
引入依赖
<!--引入redisson依赖-->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.15.4</version>
</dependency>
创建Redisson的配置类
@Configuration
public class RedissonConfig {
@Bean(destroyMethod="shutdown")
RedissonClient redisson() throws IOException {
Config config = new Config();
config.useSingleServer().setAddress("redis://59.110.235.239:6379");
return Redisson.create(config);
}
}
然后就可以使用RedissonClient来操作redis了
使用分布式锁我们可以避免一系列缓存失效问题,但是问题来了,我们怎么保证数据在修改之后我们还能读取到最新的数据呢?
这就是我们要解决的缓存一致性问题
我们在修改数据库的数据后,又往缓存里重新写入新数据
该模式下读到的最新数据有延迟,但是如果缓存数据加了过期时间,那么能够保证最终缓存中的数据一定是一致的
我们在修改数据库的数据后,又去删除缓存里的旧数据
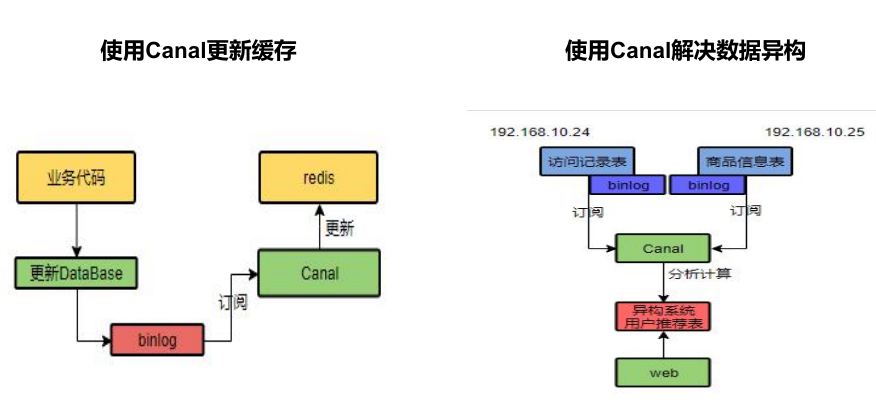
canal,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
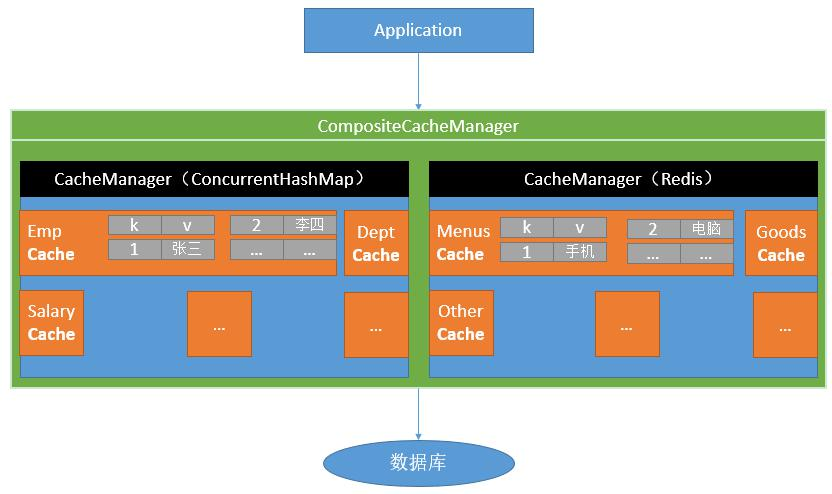
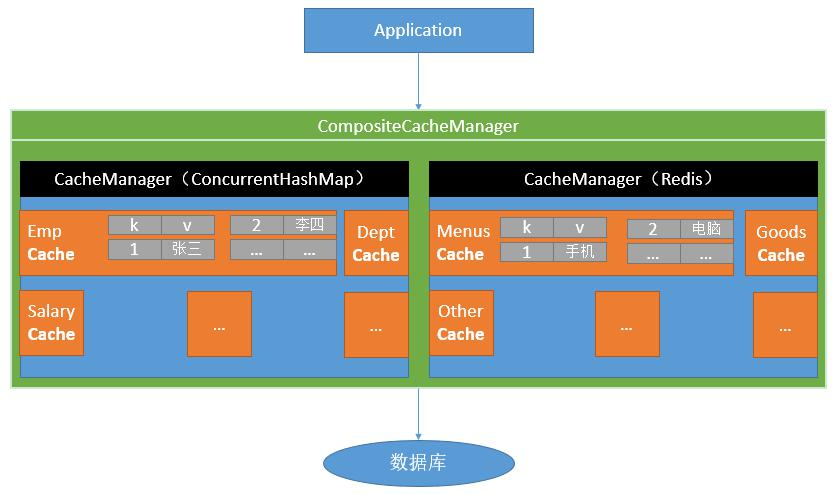
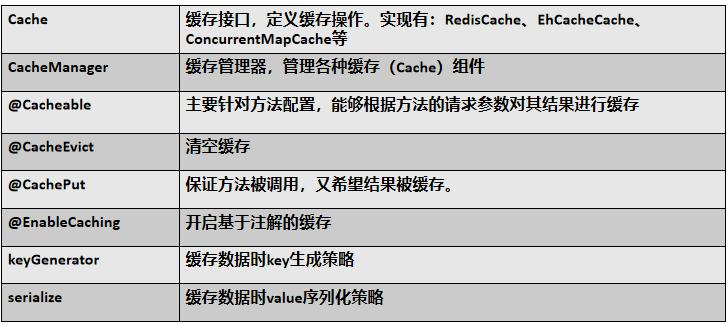
Spring从3.1开始定义了org.springframework.cache.Cache和org.springframework.cache.CacheManager接口来统一不同的缓存技术;并支持使用 JCache(JSR-107)注解简化我们开发;
Cache接口为缓存的组件规范定义,包含缓存的各种操作集合;
Cache接口下Spring提供了各种xxxCache的实现;如RedisCache,EhCacheCache,ConcurrentMapCache 等;
每次调用需要缓存功能的方法时,Spring会检查检查指定参数的指定的目标方法是否已经被调用过;如果有就直接从缓存中获取方法调用后的结果,如果没有就调用方法并缓存结果后返回给用户。下次调用直接从缓存中获取。
使用Spring缓存抽象时我们需要关注以下两点:
引入依赖(使用redis作为缓存的话还要引入spring-boot-starter-data-redis)
<!--引入spring cache-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
写配置
springboot自动配置
配置使用redis作为缓存(在这之前你的redis配置要配好)

相关注解
测试使用缓存@Cacheable
启动类上添加注解开启缓存功能@EnableCaching
在需要进行数据缓存的方法处添加上@Cacheable注解,代表当前方法的结果需要缓存,如果缓存中有,方法不用调用,如果没有,会调用方法,最后将结果缓存
每一个需要缓存的数据我们都来指定要放到哪个名字的缓存下【缓存的分区,推荐按照业务类型分】
我们在一个原本只是一直查询数据库的方法上添加上该注解

执行该方法后查看redis,发现多了一个category的分区并且存有分类数据
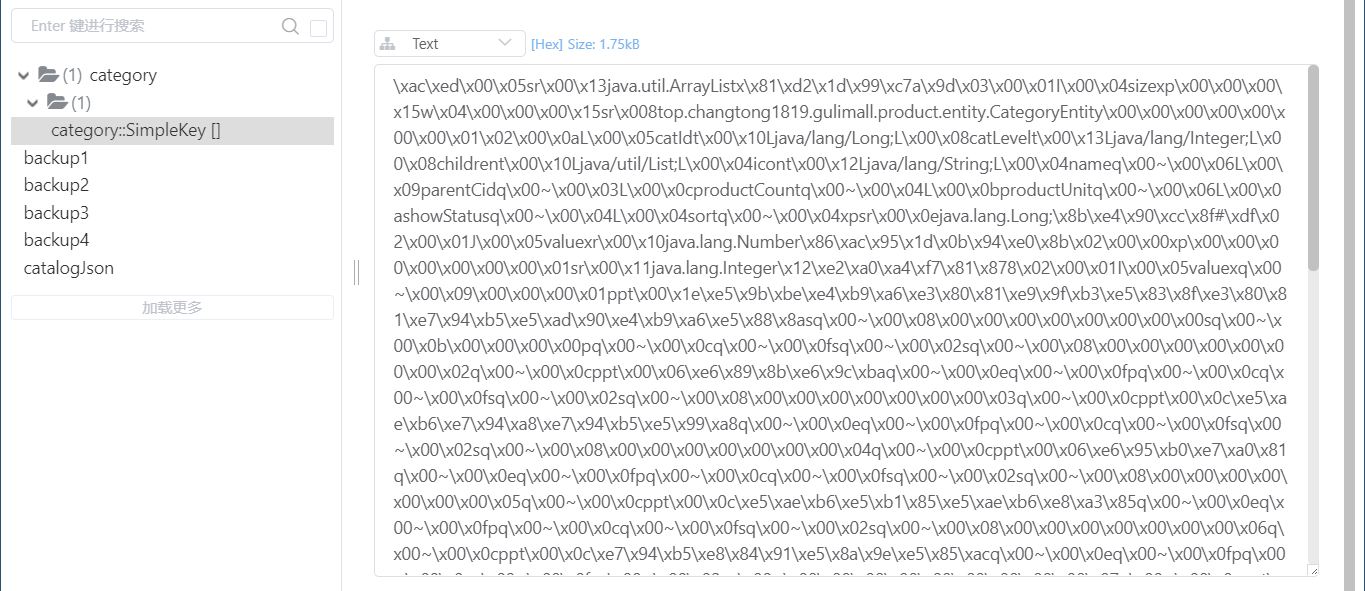
即第一次访问到该接口会往缓存里存入数据,后面会直接使用缓存里的数据
使用该注解@Cacheable("***")的默认行为:
缓存的名字::SimpleKey[]因此我们需要自定义:
指定生成的缓存使用的key:key属性指定,接收一个spel
@Cacheable(value = "category",key = "‘level1Category‘")
Spring表达式语言全称为“Spring Expression Language”,缩写为“SpEL”,类似于Struts2x中使用的OGNL表达式语言,能在运行时构建复杂表达式、存取对象图属性、对象方法调用等等,并且能与Spring功能完美整合,如能用来配置Bean定义。
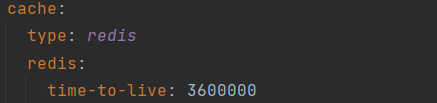
指定缓存的数据的存活时间(以毫秒为单位)
将数据保存为Json格式:使用自定义的序列化工具
添加配置类
@EnableConfigurationProperties(CacheProperties.class)
@Configuration
@EnableCaching
public class MyCacheConfig {
/**
* 配置文件的配置没有用上
* 1. 原来和配置文件绑定的配置类为:@ConfigurationProperties(prefix = "spring.cache")
* public class CacheProperties
* <p>
* 2. 要让他生效,要加上 @EnableConfigurationProperties(CacheProperties.class)
*/
@Bean
public RedisCacheConfiguration redisCacheConfiguration(CacheProperties cacheProperties) {
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig();
// config = config.entryTtl();
config = config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()));
config = config.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));
CacheProperties.Redis redisProperties = cacheProperties.getRedis();
//使用了自定义的配置后,不会再自动读取yml中设置的信息了,因此手动添加,将配置文件中所有的配置都生效
if (redisProperties.getTimeToLive() != null) {
config = config.entryTtl(redisProperties.getTimeToLive());
}
if (redisProperties.getKeyPrefix() != null) {
config = config.prefixKeysWith(redisProperties.getKeyPrefix());
}
if (!redisProperties.isCacheNullValues()) {
config = config.disableCachingNullValues();
}
if (!redisProperties.isUseKeyPrefix()) {
config = config.disableKeyPrefix();
}
return config;
}
}
其它相关配置(前缀、空值设置)

测试删除缓存@CacheEvict:失效模式
我们在分类的更新方法上添加上注解(指明删除哪个分区下的哪个缓存)
@CacheEvict(value = "category",key = "‘getLevel1Categorys‘")
注意SpEl表达式里面我们想要直接表示一个字符串需要在双引号里面再添加上一对单引号
然后调用该方法之后就会删掉对应的缓存
这里指定了删除对应的key,我们也可以删除指定分区下的所有key
@CacheEvict(value = "category",allEntries = true)
使用@Caching()注解组合多种缓存操作

回到之前我们讲的缓存失效问题以及缓存一致性问题,我们使用SpringCache来读写缓存,会不会导致这些问题呢?
读模式:
缓存穿透:
SpringCache可以设置缓存空数据cache-null-values=true来应对该问题
缓存击穿:
上面我们引入分布式锁时说过这个问题的解决方法时加锁,那么我们的SpringCache操作时有加锁吗?
默认情况下SpringCache是时没有加锁的,可以给@Cacheable注解添加上sync = true属性添加上锁,当然,这里不是添加的分布式锁,只是synchronized(this)本地锁,足以解决击穿问题。
缓存雪崩:
SpringCache可以设置过期时间spring-cache-redis.time-to-live
你可能会疑问,不就是因为同时出现大量key过期才导致的雪崩问题吗?我们是不是应该添加的是随机过期时间?
注意,过期时间是一样的,但是设置过期时间的时刻是不一样的,那么这样其实也就和随机时间是差不多的意思。
即读模式对应的一些问题SpringCache都有相应的措施
写模式:
总结:
常规数据(读多写少,即时性、一致性要求不高的数据):完全可以使用SpringCache,对于写模式,只要有缓存数据的过期时间就足够了
特殊数据:特殊设计
原文:https://www.cnblogs.com/changtong1819/p/14730307.html