volatile:解决多线程场景的可见性问题
可见性问题:多线程的情况下,对于共享变量的读取,不一定是最新的值,就是可见性的问题
场景:多核cpu中,每个内核存在自己的高速缓存,线程的读取都是先从高速缓存中直接读取,读取不到才去内存中读取,优化了io开销过大,提升服务器性能,这是cpu的内存模型设计
简单如下图:内存是所有cpu共享的,每个cpu存在自己自身的高速内存
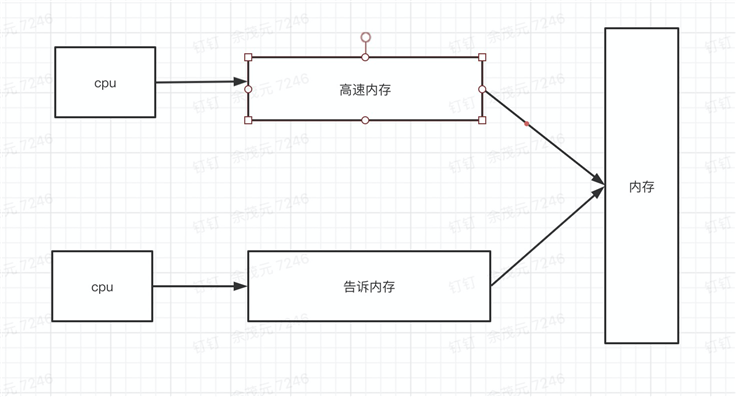
上图中就会存在可见性问题,cpu为了防止这样的问题,设计上做了优化:
缓存锁和总线锁
总线锁直接锁内存,就是对共享变量的操作,内存每次只允许一个线程来执行,这样开销比较大。
缓存锁:对共享变量每个告诉缓存都做了缓存,当共享变量被修改时候,通过缓存锁,报障每个高速缓存中的变量副本一致。
为了达到数据访问的一致,需要各个处理器在访问缓存时遵循一些协议,在读写时根据协议来操作,
常见的协议有MSI,MESI,MOSI等
MESI表示缓存行的四种状态:
M(Modify)表示共享数据只缓存在当前CPU缓存中,并且是被修改状态,也就是缓存的数据和主内存中的数据不一致
E(Exclusive)表示缓存的独占状态,数据只缓存在当前CPU缓存中,并且没有被修改
S(Shared)表示数据可能被多个CPU缓存,并且各个缓存中的数据和主内存数据一致
I(Invalid)表示缓存已经失效
具体实现:一个线程修改共享变量的时候,会先使得其他拥有改共享变量的线程中的变量副本失效,得到ack响应后,再讲内存写入到主内存中,这样的话,就解决了可见性问题。
但是因为ack响应本身是个阻塞操作,于是对MESI缓存一致性原则有了一些优化,续就加入了storeBuffer的概念,其实就是异步,一个线程修改了共享变量,将操作直接丢入到storeBuffer中,然后继续执行后面的指令,而storeBuffer再等到ack响应后,将共享变量写入主内存中,这样大大提升了性能。
但是storeBuffer的使用,又导致了新的问题,指令重排序问题:
线程在等到ack响应的时候,storeBuffer是异步的,于是继续执行了后续的指令,当另一个线程读取共享变量的时候,原本按照顺序执行结果成立的条件,就存在了不成立的可能性,还是存在了可见性问题,这就是指令重排序。
针对这种问题,cpu提供给了高级语言一些方式,就是阻止cpu自生优化导致的指令重排序问题。
volatile关键字,就是阻止指令重排序,是的多线程操作共享变量的时候,一定是对结果可见的。
实现方式,就是通过内存屏障:
Store Memory Barrier(写屏障):告诉处理器在写屏障之前的所有已经存储在存储缓存(storebuferes)中的数据同步到主内存,简单来说就是使得写屏障之前的指令的结果对屏障之后的读或者写是可见的Load Memory Barrier(读屏障):处理器在读屏障之后的读操作,都在读屏障之后执行。配合写屏障,使得写屏障之前的内存更新对于读屏障之后的读操作是可见的
Full Memory Barrier(全屏障):确保屏障前的内存读写操作的结果提交到内存之后,再执行屏障后的读写操作
这里实现了有序性
这就是volatile关键字的用处已经实现原理,主要就是解决高速缓存中的可见性,有序性,保证了这两种也就保证了共享变量的一致性。
JMM
JMM定义了共享内存中多线程程序读写操作的行为规范:在虚拟机中把共享变量存储到内存以及从内存中取出共享变量的底层实现细节。通过这些规则来规范对内存的读写操作从而保证指令的正确性,它解决了CPU多级缓存、处理器优化、指令重排序导致的内存访问问题,保证了并发场景下的可见性。
从抽象的角度来看,JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(Main Memory)中,每个线程都有一个私有的本地内存(Local Memory),本地内存中存储了该线程以读/写共享变量的副本。
解决有序性的方式还有:
Happens-Before:
先行发生原则,就是指令重排序不能影响执行结果,两个指令存在依赖关系,也不允许指令重排序,有了这个原则的约束,多数时候是不需要使用volatile关键字的
先行发生原则存在传递性,a before b b before c a一定before c
synchronized关键字,线程的start(),join(),final关键字都是存在有序性限制
原文:https://www.cnblogs.com/xianyi/p/14731587.html