摘要:Gremlin是图数据库查询使用最普遍的基础查询语言。Gremlin的图灵完备性,使其能够编写非常复杂的查询语句。对于复杂的问题,我们该如何编写一个复杂的查询?以及我们该如何理解已有的复杂查询?本文带你逐步抽丝剥茧,完成复杂查询的调试。
Gremlin是Apache TinkerPop 框架下的图遍历语言。Gremlin是一种函数式数据流语言,可以使得用户使用简洁的方式表述复杂的属性图(property graph)的遍历或查询。每个Gremlin遍历由一系列步骤(可以存在嵌套)组成,每一步都在数据流(data stream)上执行一个原子操作。
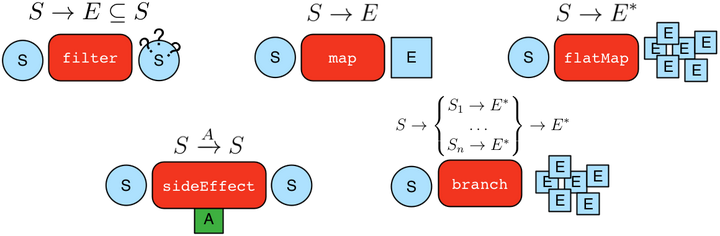
Gremlin是一种用于描述属性图中行走的语言。图形遍历分两个步骤进行。
开始节点选择(Start node selection)。所有遍历都从数据库中选择一组节点开始,这些节点充当图中行走的起点。Gremlin中的遍历是从TraversalSource开始的。 GraphTraversalSource提供了两种遍历方法。
走图(Walking the graph)。从上一步中选择的节点开始,遍历会沿着图形的边行进,以根据节点和边的属性和类型到达相邻的节点。遍历的最终目标是确定遍历可以到达的所有节点。您可以将图遍历视为子图描述,必须执行该子图描述才能返回节点。
V()和E()的返回类型是GraphTraversal。 GraphTraversal维护许多返回GraphTraversal的方法。GraphTraversal支持功能组合。 GraphTraversal的每种方法都称为一个步骤(step),并且每个步骤都以五种常规方式之一调制(modulates)前一步骤的结果。
gremlin> g.V().has(‘name‘,‘marko‘).out(‘knows‘).values(‘name‘) ==>vadas ==>josh
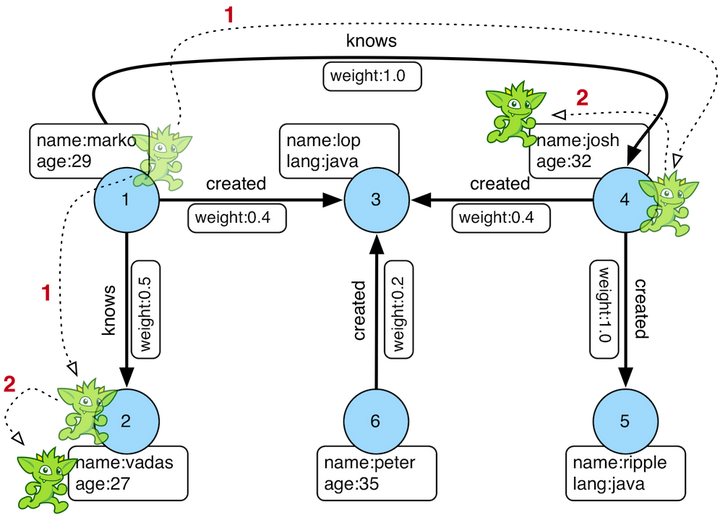
这也就时说任何复杂的问题,都可以用Gremlin描述。
下面就调试和编写复杂的gremlin查询,给出指导思路和方法论。
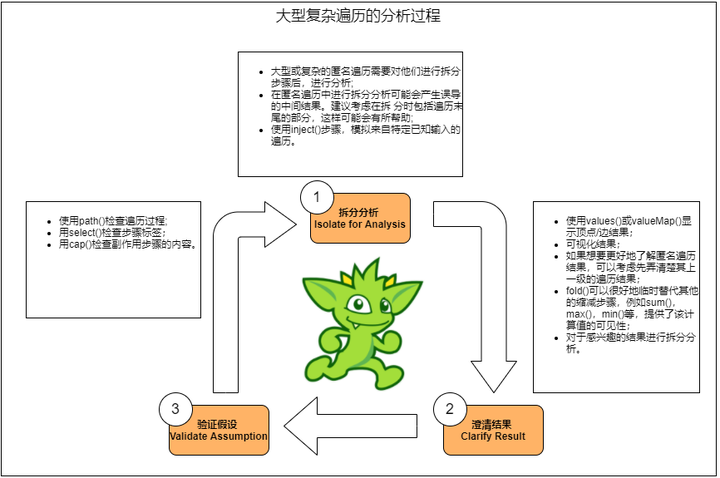
Gremlin的查询都是由简单的查询组合成复杂的查询。所以对于复杂Gremlin查询可以分为以下三个步骤,并逐步迭代完成所有语句的验证,此方法同样适用编写复杂的Gremlin查询。
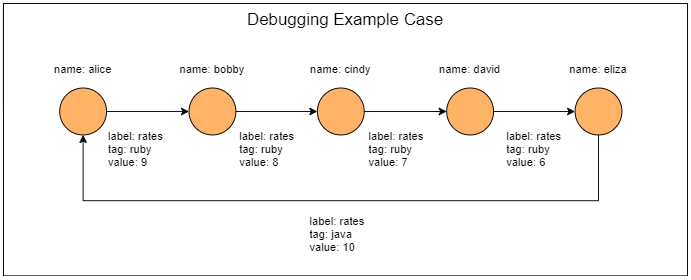
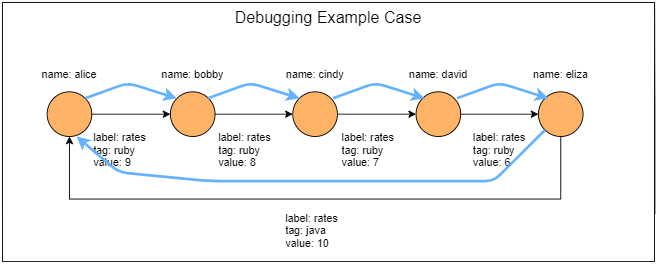
gremlin> graph = TinkerGraph.open() ==>tinkergraph[vertices:0 edges:0] gremlin> g = graph.traversal() ==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard] gremlin>g.addV().property(‘name‘,‘alice‘).as(‘a‘). addV().property(‘name‘,‘bobby‘).as(‘b‘). addV().property(‘name‘,‘cindy‘).as(‘c‘). addV().property(‘name‘,‘david‘).as(‘d‘). addV().property(‘name‘,‘eliza‘).as(‘e‘). addE(‘rates‘).from(‘a‘).to(‘b‘).property(‘tag‘,‘ruby‘).property(‘value‘,9). addE(‘rates‘).from(‘b‘).to(‘c‘).property(‘tag‘,‘ruby‘).property(‘value‘,8). addE(‘rates‘).from(‘c‘).to(‘d‘).property(‘tag‘,‘ruby‘).property(‘value‘,7). addE(‘rates‘).from(‘d‘).to(‘e‘).property(‘tag‘,‘ruby‘).property(‘value‘,6). addE(‘rates‘).from(‘e‘).to(‘a‘).property(‘tag‘,‘java‘).property(‘value‘,10). iterate() gremlin> graph ==>tinkergraph[vertices:5 edges:5]
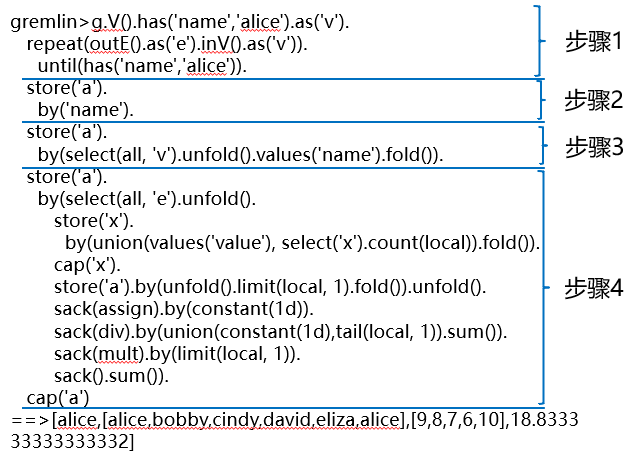
gremlin>g.V().has(‘name‘,‘alice‘).as(‘v‘). repeat(outE().as(‘e‘).inV().as(‘v‘)). until(has(‘name‘,‘alice‘)). store(‘a‘). by(‘name‘). store(‘a‘). by(select(all, ‘v‘).unfold().values(‘name‘).fold()). store(‘a‘). by(select(all, ‘e‘).unfold(). store(‘x‘). by(union(values(‘value‘), select(‘x‘).count(local)).fold()). cap(‘x‘). store(‘a‘).by(unfold().limit(local, 1).fold()).unfold(). sack(assign).by(constant(1d)). sack(div).by(union(constant(1d),tail(local, 1)).sum()). sack(mult).by(limit(local, 1)). sack().sum()). cap(‘a‘) ==>[alice,[alice,bobby,cindy,david,eliza,alice],[9,8,7,6,10],18.833333333333332]
好长,好复杂!头大!
看我如何抽丝剥茧,一步步验证结果。
按执行步骤,拆分成小的查询,如下图:
gremlin> g.V().has(‘name‘,‘alice‘).as(‘v‘). ......1> repeat(outE().as(‘e‘).inV().as(‘v‘)). ......2> until(has(‘name‘,‘alice‘)) ==>v[0]
这里通过valueMap()输出节点信息。
gremlin> g.V().has(‘name‘,‘alice‘).as(‘v‘). ......1> repeat(outE().as(‘e‘).inV().as(‘v‘)). ......2> until(has(‘name‘,‘alice‘)).valueMap() ==>[name:[alice]]
根据执行语句的语义推导查询过程,如下:
使用path(), 验证推导过程
g.V().has(‘name‘,‘alice‘).as(‘v‘). ......1> repeat(outE().as(‘e‘).inV().as(‘v‘)). ......2> until(has(‘name‘,‘alice‘)).path().next() ==>v[0] ==>e[10][0-rates->2] ==>v[2] ==>e[11][2-rates->4] ==>v[4] ==>e[12][4-rates->6] ==>v[6] ==>e[13][6-rates->8] ==>v[8] ==>e[14][8-rates->0] ==>v[0]
gremlin> g.V().has(‘name‘,‘alice‘).as(‘v‘). ......1> repeat(outE().as(‘e‘).inV().as(‘v‘)). ......2> until(has(‘name‘,‘alice‘)). ......3> store(‘a‘).by(‘name‘) ==>v[0]
大家可以自己去细细的剥下笋,此处略去3000字。
本文分享自华为云社区《复杂Gremlin查询的调试方法》,原文作者:Uncle_Tom。
原文:https://www.cnblogs.com/huaweiyun/p/14734204.html