主要作用是:训练深层神经网络是十分困难的,特别是在较短的时间内使他们收敛更加棘手,可持续加速深层网络的收敛速度。
怎么达到加速深层网络的收敛速度:
1、数据的预处理影响收敛速度和调参难度,比较明显的例子是线性回归,如果特征量纲差别特别大,他的斜率可能近视90度或者0度,收敛速度和调参是比较困难的。BN就可以更好的配置优化器使用,因为它将参数的量级进行统一。
2、更深层的网络很复杂,容易过拟合,而BN可以起到正则化作用,防止过拟合
3、批量归一化利用小批量的均值和标准差,不断调整神经网络的中间输出,使整个神经网络各层的中间输出值更加稳定(由于在训练过程中,中间层的变化幅度不能过于剧烈,而批量归一化将每一层主动居中,并将它们重新调整为给定的平均值和大小(通过 μ^Bμ^B 和 σ^Bσ^B))
怎么做的:
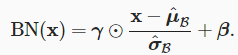
分2步,首先通过 μ^B 是样本均值, 是小批量 BB 的样本标准差。 应用标准化后,生成的小批量的平均值为 0 和单位方差为 1
由于单位方差(与其他一些魔法数)是一个任意的选择,变换之后丢失了原始数据信息, 因此我们通常包含 拉伸参数(scale) γγ 和 偏移参数(shift) ββ,它们的形状与 xx 相同。 请注意,γ和 β 是需要与其他模型参数一起学习的参数。
怎么用的:
既可以用于全连接层,也可以用于卷积层
全连接层:常用于全连接层和激活函数之间
h=?(BN(Wx+b)).
卷积层:常用于卷积层之后和非线性激活函数之前应用批量归一化,多输出为多个Channel时,针对每个Channel分析计算BN
训练和预测时,BN计算行为通常不同,当训练时,均值和方差为该一批次的均值和方差(不使用全局样本的均值和方差的原因是使用局部的鲁棒性更强);当预测时,是一个样本一个样本训练的,所有BN计算使用的均值和方差是训练时保存下来的(移动平均估算整个训练数据集的样本均值和方差)
原文:https://www.cnblogs.com/pyclq/p/14735974.html