什么场景需要使用爬虫程序进行模拟登陆需求呢 ?
所以接下来会对 人人网 进行模拟登陆,那么和此前的验证码识别有什么关联;
人人网的登陆验证码为 当连续失败登陆超过 3次以后就会弹出验证码登陆;
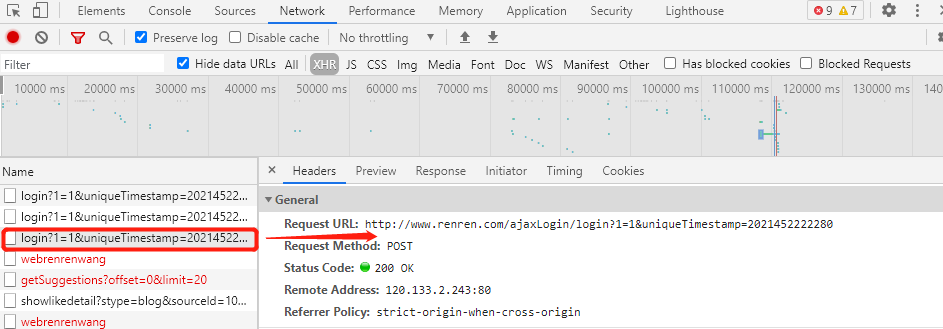
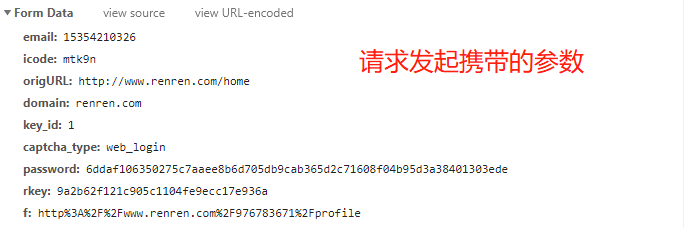
2、Post请求对ajaxLogin接口请求参数分析
# 用户名
email: 15354210326
# 验证码
icode: mtk9n
origURL: http://www.renren.com/home
domain: renren.com
key_id: 1
captcha_type: web_login
# 密码
password: 6ddaf106350275c7aaee8b6d705db9cab365d2c71608f04b95d3a38401303ede
rkey: 9a2b62f121c905c1104fe9ecc17e936a
f: http%3A%2F%2Fwww.renren.com%2F976783671%2Fprofile
3、根据上述分析,如果我们想实现对人人网的模拟登陆,只需要对ajaxLogin接口发起请求,并携带正确登陆参数;
4、验证码 :每次请求都会动态变化,所以我们在模拟登陆前,需要对登陆页的验证码数据进行识别,识别的结果需要作为 对登陆接口 POST请求时一个参数;
1、验证码识别,获取验证码图片的文字数据 :对当前登陆页面进行请求,将验证码进行解析,对验证码地址发起请求,就可以获取验证码图片并保存到本地,然后使用超级鹰提供的图片识别功能进行识别解析;
2、对POST请求发起请求,处理请求参数;
3、对响应数据进行持久化存储;
# _*_coding : UTF-8_*_
# 开发时间 : 2021/5/7 22:11
import requests
from lxml import etree
# 1、对验证码图片进行捕获和识别
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36‘
}
url = "http://www.renren.com/SysHome.do"
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
code_image_src = tree.xpath(‘//*[@id="verifyPic_login"]/@src‘)[0]
code_imag_data = requests.get(url=code_image_src, headers=headers).content # 二进制
with open(‘./code.jpg‘, ‘wb‘) as fp:
fp.write(code_image_src)
# 使用超级鹰提供的示例代码对验证码图片进行识别
原文:https://www.cnblogs.com/dai-zhe/p/14743009.html