推理卡的Codename是GOYA
计算:
3类计算引擎,TPC,GEMM,DMA,第一个进行向量计算,是主要的引擎,第二个进行矩阵运算,第三个是DMA;
最高支持FP32的计算;
采用TSMC 16 nm制程;
应该是标卡的形态;FHFL-2S,TDP200W;
内存:
2 Channel DDR4 @2667MB/s,合计是16GB显存
那么内存带宽是:2*2667MB/s*64bit/8/1000=42GB/s;
并没有采用GDDR;
互联:
host interface是X16 PCIe Gen4
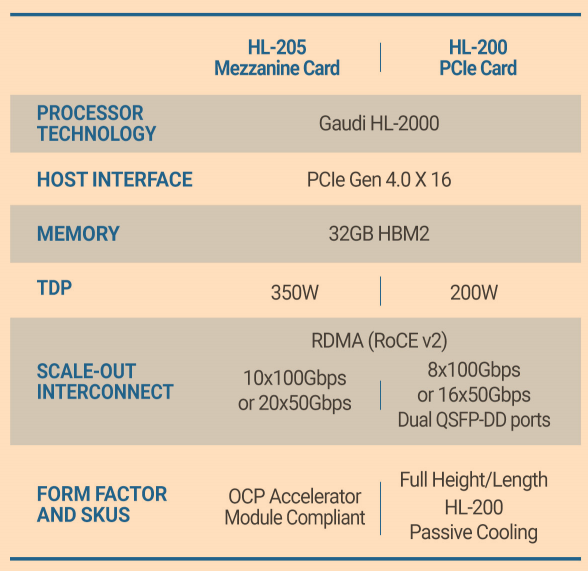
训练卡的codename是GAUDI
计算:
计算引擎和GOYA类似;
OAM形态的卡是350W TDP;
PCie形态的卡,应该是双宽的,直接带以太网出端口;TDP是200W;并且只支持8个100GbE;
内存:
4 HBM Stack 合计是32GB @2GT/s
因此内存的带宽是:4Stack*2GT/s*1024bit/8/1000=1TB/s;
互联:
Host Interface也还是X16 PCie Gen4
但是片上集成了10个100Gb的Ethernet口,支持RoCE V2;(也可以用作20*50GbE),相当于集成了网络和计算,降低了网卡的成本,但是有一部分的接口是需要用于G2G的互联的;
内部还是20个56Gb的SerDes;
形态上是OAM 0.9 SPEC的;
互联接口的使用上例如,每个卡:7个100GbE用户和另外7个OAM实现All2All 互联,3个100GbE用于节点之间互联;相当于1个3U的module出8*3=24个100GbE的端口;
G2G带宽是700Gb=87.5GB/s,并不是非常快;
当然针对模型模型的场景,也可以将10个100GbE全部连出去,到TOR上,以提高模型worker之间的带宽;
Habana的Logo不错,这个是GAUDI Datasheet中总结的三个特性的icon也是非常不错的:
参考文献:
Hot Chip 2019 :https://old.hotchips.org/hc31/HC31_1.14_HabanaLabs.Eitan_Medina.v9.pdf
Understanding Habana Labs's GPU
原文:https://www.cnblogs.com/kongchung/p/14745663.html