redis最开始使用主从模式做集群,若master宕机需要手动配置slave转为master;后来为了高可用提出哨兵模式,该模式下有一个哨兵监视master和slave,若master宕机可以自动将slave转为master,但它也有一个问题,就是不能动态扩充;所以3.x提出了cluster集群模式
一、redis-cluster设计
1)redis-cluster采用无中心结构,每个节点保存数据和整个集群状体,每个节点都和其他所有节点连接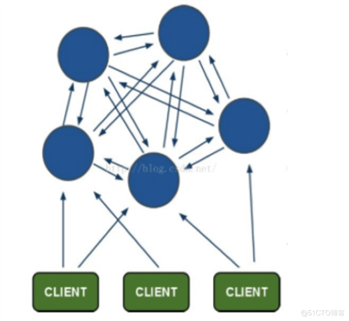
2)结构特点
1?、所有的redis节彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽
2?、节点的fail是通过集群中的超过半数的节点检测失效时才生效
3?、客户端与redis节点直连,不需要中间proxy层,客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
4?、redis-cluster把所有的物理节点映射到[0-16383]slot上(不一定是平均分配),cluster负责维护node<->slot<->value
5?、redis集群预分好16384个桶,当需要在redis集群中放置一个key-value时,根据CRC16(key) mod 16384的值,决定将一个key放在哪一个桶
3)redis-cluster节点分配
我们现在时三个主节点,分别是:A、B、C三个节点,他们可以是一台机器上的三个端口,也可以是三台不同的服务器。那么采用哈希槽(hash slot)的方式来分配16384个slot的话,他们三个节点分别承担的slot区间是:
· 节点A覆盖0-5460
· 节点B覆盖5461-10922
· 节点C覆盖10923-16383
4)获取数据
如果存入一个值,按照redis cluster哈希槽的算法:CRC16(‘key‘)384=6782,那么会把这个key存储分配到B上。同样,当我们连接(A、B、C)任何一个节点想获取‘key’这个key时,也会是这样的算法,然后内部跳转到B节点上获取数据
5)新增一个主节点
新增一个节点D,redis-cluster的这种做法是从各个节点的前面各拿取一部分slot到D上,我们会在接下来的实践中实验。大致会变成这样:
· 节点A覆盖1365-5460
· 节点B覆盖6827-10922
· 节点C覆盖12288-16383
· 节点D覆盖0-1364,5461-6826,10923-12287
同样删除一个节点也是类似,移动完成后就可以删除这个节点
6)redis-cluster主从模式
1?、redis-cluster为了保证数据的高可用性,加入了主从模式,一个主节点对应一个或多个从节点,主节点提供数据存取,从节点则是从主节点拉取数据备份,当这个主节点挂掉后,就会有这个从节点选取一个来充当主节点,从而保证集群不会挂掉
2?、上面那个例子里,集群有A、B、C三个主节点,如果这3个主节点都没有加入从节点,如果B挂掉了,我们就无法访问整个集群。A和C的slot也没法访问
3?、所以我们在集群建立的时候,一定为每个主节点都添加从节点,比如像这样,集群包含主机节点A、B、C,以及从节点A1、B1、C1,那么即使B挂掉系统也可以继续正确工作。
4?、B1节点替代了B节点,所以redis集群将会选择B1节点作为新的主节点,集群将会继续正确的提供服务。当B重新开启后,就会变成B1的从节点
5?、如果B节点和B1节点同时挂了,redis集群就无法继续正确的提供服务了二、redis持久化
1、RDB持久化方式能够在指定时间间隔内对数据进行快照存储
2、AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾,redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大
3、RDB主要用于主从复制
4、AOF保存的数据更为完整,但同时其大小也更大
5、默认采用RDB的方式进行持久化存储三、redis集群的搭建
1、集群至少应该有奇数个节点,所以知道有三个节点,每个节点至少有一个备份节点,所以下面使用6个节点(主节点、备份节点由redis-cluster集群确定)
2、下载redis
https://download.redis.io/releases/redis-6.2.3.tar.gz?_ga=2.177267237.1627183240.1620440357-932383601.1620440357
3、安装redis节点指定端口
1?、解压reids压缩包,编译安装
[root@hadoop02 redis-6.2.3]# tar xf redis-6.2.3.tar
[root@hadoop02 redis-6.2.3]# cd redis-6.2.3
[root@hadoop02 redis-6.2.3]# make
[root@hadoop02 redis-6.2.3]# make install PREFIX=/data/redis
[root@hadoop02 redis-6.2.3]# mkdir -p /data/redis/{7000,7001,7002,7003,7004,7005}
2?、将/data/redis/bin目录移动到700的所有目录下,在7000目录中创建配置文件redis.conf,并复制到其他目录,内容如下:
daemonize yes #后台启动
port 7000 #修改端口号,从7001到7006
cluster-enabled yes #开启cluster,去掉注释
cluster-config-file nodes.conf #自动生成
cluster-node-timeout 15000 #节点通信时间
appendonly yes #持久化方式
4、安装redis-tirb所需的ruby脚本
注意:centos7默认的ruby版本太低,要鞋卸载重装
[root@hadoop02 7005]# yum remove ruby
[root@hadoop02 7005]# yum install -y ruby
[root@hadoop02 7005]# yum install -y rubygems
1?、安装gem
[root@hadoop02 src]# gem install redis
2?、启动redis
3?、查看redis进程启动状态
5、使用redis-cli创建集群
[root@hadoop02 redis]# ./bin/redis-cli --cluster create --cluster-replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 127.0.0.1:7004 to 127.0.0.1:7000
Adding replica 127.0.0.1:7005 to 127.0.0.1:7001
Adding replica 127.0.0.1:7003 to 127.0.0.1:7002
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: 1c5e23b0241cca59b2ab4064401ee4f34b446dc6 127.0.0.1:7000
slots:[0-5460] (5461 slots) master
M: dcad9d24de095fbeff4c6e9d84d7096bcf03bac3 127.0.0.1:7001
slots:[5461-10922] (5462 slots) master
M: 259ea971a034e020fbdcc4a68190b116b163cd9e 127.0.0.1:7002
slots:[10923-16383] (5461 slots) master
S: 92c599203159d1d138621f3c8a73e369c8cbb16b 127.0.0.1:7003
replicates 1c5e23b0241cca59b2ab4064401ee4f34b446dc6
S: 28d73eb1f86f48b8b69969da5679de8bfaa37384 127.0.0.1:7004
replicates dcad9d24de095fbeff4c6e9d84d7096bcf03bac3
S: 9cbd936ff0e92ac58b2513ffbb8d947fce3116b3 127.0.0.1:7005
replicates 259ea971a034e020fbdcc4a68190b116b163cd9e
Can I set the above configuration? (type ‘yes‘ to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join.
>>> Performing Cluster Check (using node 127.0.0.1:7000)
M: 1c5e23b0241cca59b2ab4064401ee4f34b446dc6 127.0.0.1:7000
slots:[0-5460] (5461 slots) master 1 additional replica(s)
S: 28d73eb1f86f48b8b69969da5679de8bfaa37384 127.0.0.1:7004 slots: (0 slots) slave replicates dcad9d24de095fbeff4c6e9d84d7096bcf03bac3
M: 259ea971a034e020fbdcc4a68190b116b163cd9e 127.0.0.1:7002
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 9cbd936ff0e92ac58b2513ffbb8d947fce3116b3 127.0.0.1:7005
slots: (0 slots) slave
replicates 259ea971a034e020fbdcc4a68190b116b163cd9e
S: 92c599203159d1d138621f3c8a73e369c8cbb16b 127.0.0.1:7003
slots: (0 slots) slave
replicates 1c5e23b0241cca59b2ab4064401ee4f34b446dc6
M: dcad9d24de095fbeff4c6e9d84d7096bcf03bac3 127.0.0.1:7001
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.上面显示创建成功,有3个主节点,3个从节点,每个节点都是成功连接状态
四、redis集群测试
1)测试存取值,客户端连接集群redis-cli需要带上-c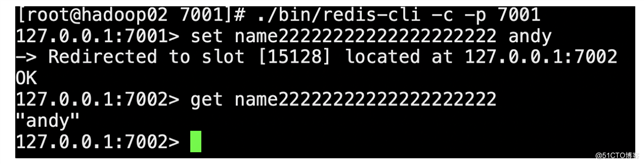
根据redis-cluster的key值分配,name222222222222222应该分配到节点7002,上面显示redis cluster自动从7001跳转到了7002节点
2)测试从7004从节点获取name2222222222值
五、集群节点选举
1)模拟将7002节点挂掉,按照redis-cluster原理会选举将7002的从节点7005选举为主节点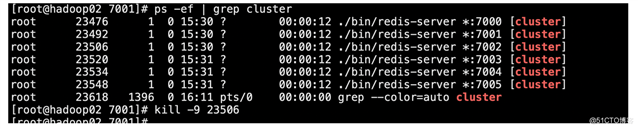
2)查看集群中的7002节点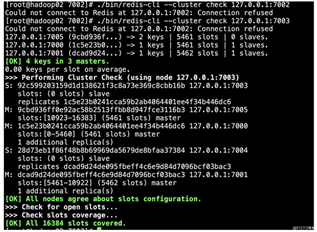
可以看到集群连接不了7002节点,而7005由原来的S转换为M节点,替代了原来的7002节点。
3)将7002节点恢复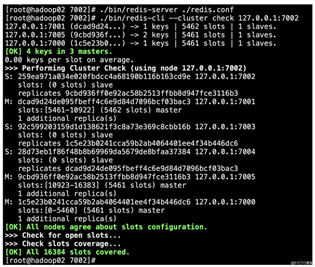
可以看到7002节点变成了7005的从节点原文:https://blog.51cto.com/u_13520761/2762049