Flink采用的稳定版本为flink-1.12.1。以往我们所熟知的Map Reduce,Storm,Spark等框架可能在某些场景下已经没法完全地满足用户的需求,或者是实现需求所付出的代价,无论是代码量和架构的复杂程度可能都没法满足预期的需求。新场景的出现催产出新的技术,Flink即为实时流提供了新的选择。Flink相对简单的编程模型加上其高吞吐、低延迟、高性能以及支持exactly-once语义的特性,让它在工业生产中较为出众。
软件配置选择如下:
3台centos7机器如下:
| ip | 主机名 | flink角色 |
| 192.168.1.105 | node1 | StandaloneSessionClusterEntrypoint、TaskManagerRunner |
| 192.168.1.106 | node2 | StandaloneSessionClusterEntrypoint、TaskManagerRunner |
| 192.168.1.107 | node3 | TaskManagerRunner |
StandaloneSessionClusterEntrypoint为jobmnager,taskManagerRunner为taskManager。
在Flink运行时涉及到的进程主要有以下两个:
首先选定一台机器节点,解压flink-1.12.1-bin-scala_2.11.tgz,并进入conf目录修改flink-conf.yaml和master文件,修改完毕之后把flink安装包往其他两台机器复制
jobmanager.rpc.address: node1 jobmanager.rpc.port: 6123 jobmanager.memory.process.size: 1600m taskmanager.memory.process.size: 1728m taskmanager.numberOfTaskSlots: 1 parallelism.default: 1 high-availability: zookeeper high-availability.storageDir: hdfs://node/flink/ha/ high-availability.zookeeper.quorum: node1:2181,node2:2181,node3:2181 high-availability.zookeeper.path.root: /flink state.backend: filesystem state.checkpoints.dir: hdfs://node/flink/checkpoints state.savepoints.dir: hdfs://node/flink/checkpoints jobmanager.execution.failover-strategy: region io.tmp.dirs: /tmp/flink/tmp historyserver.web.address: 0.0.0.0 historyserver.web.port: 8082 historyserver.archive.fs.dir: hdfs://node/flink/completed-jobs/ historyserver.archive.fs.refresh-interval: 10000
注:
红色字体即为需要修改的内容,node1为每台节点的hostname,每台节点需要适应变动。
这里配置node1和node2为高可用节点
[root@node1 conf]# vim masters node1:8081 node2:8082
[root@node1 app]# scp flink-1.12.1/ root@node2:/opt/app [root@node1 app]# scp flink-1.12.1/ root@node2:/opt/app
启动顺序:先启动zk和hdfs,再启动flink
启动集群:
start-cluster.sh
在浏览器输入:http://node1:8081/或http://node1:8082/,即可看到flink任务执行情况
JDK:1.8 (jdk1.8.0_151)
Hadoop:2.7.6 (hadoop-2.7.6.tar.gz)
HBase:2.1.2 (hbase-2.1.1-bin.tar.gz)
这里jdk、hadoop、zookeeper假定均已安装完毕。
high-availability: zookeeper high-availability.storageDir: hdfs://node/flink/ha/ high-availability.zookeeper.quorum: node1:2181,node2:2181,node3:2181 high-availability.zookeeper.path.root: /flink # high-availability.cluster-id: /cluster_one on yarn不配置,配了任务会启动不来
vi /etc/profile 或者 vi /etc/bashrc
export FLINK_HOME=/home/redpeak/app/flink-1.12.3 export PATH=$FLINK_HOME/bin:$PATH export HADOOP_CLASSPATH=`hadoop classpath`
需要在每台flink节点配置FLINK_HOME和HADOOP_CLASSPATH环境变量
Session模式是预分配资源的,也就是提前根据指定的资源参数初始化一个Flink集群,并常驻在YARN系统中,拥有固定数量的JobManager和TaskManager(注意JobManager只有一个)。提交到这个集群的作业可以直接运行,免去每次分配资源的overhead。但是Session的资源总量有限,多个作业之间又不是隔离的,故可能会造成资源的争用;如果有一个TaskManager宕机,它上面承载着的所有作业也都会失败。另外,启动的作业越多,JobManager的负载也就越大。所以,Session模式一般用来部署那些对延迟非常敏感但运行时长较短的作业。
提交任务命令:
./bin/flink run -t yarn-session -Dyarn.application.id=application_XXXX_YY ./examples/streaming/TopSpeedWindowing.jar
再次连接YARN session命令:
./bin/yarn-session.sh -id application_XXXX_YY
顾名思义,在Per-Job模式下,每个提交到YARN上的作业会各自形成单独的Flink集群,拥有专属的JobManager和TaskManager。可见,以Per-Job模式提交作业的启动延迟可能会较高,但是作业之间的资源完全隔离,一个作业的TaskManager失败不会影响其他作业的运行,JobManager的负载也是分散开的,不存在单点问题。当作业运行完成,与它关联的集群也就被销毁,资源被释放。所以,Per-Job模式一般用来部署那些长时间运行的作业。
提交任务命令:
./bin/flink run -t yarn-per-job --detached ./examples/streaming/TopSpeedWindowing.jar
注:--detached,以分离模式运行作业,detached模式在提交完任务后就退出client
任务列表和取消任务命令:
# List running job on the cluster ./bin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY # Cancel running job ./bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY <jobId>
Session模式和Per_Job模式可以用如下简图表示,其中红色、蓝色和绿色的图代表不同的作业。

Deployer表示向YARN集群发起部署请求的节点,一般来讲在生产环境中,也总有这样一个节点作为所有作业的提交入口(即客户端)。在main()方法开始执行直到env.execute()方法之前,客户端也需要做一些工作,即:
只有在这些都完成之后,才会通过env.execute()方法触发Flink运行时真正地开始执行作业。如果所有用户都在Deployer上提交作业,较大的依赖会消耗更多的带宽,而较复杂的作业逻辑翻译成JobGraph也需要吃掉更多的CPU和内存,客户端的资源反而会成为瓶颈。不管Session还是Per-Job模式都存在此问题。为了解决,社区在传统部署模式的基础上实现了Application模式。
此模式的作业提交框图如下:
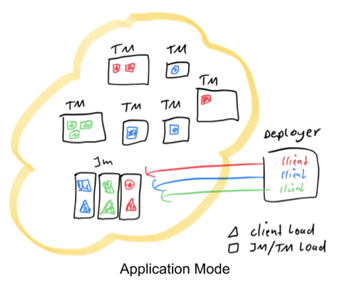
可见,原本需要客户端做的三件事被转移到了JobManager里,也就是说main()方法在集群中执行(入口点位于ApplicationClusterEntryPoint),Deployer只需要负责发起部署请求了。另外如果一个main()方法中有多个env.execute/executeAsync()调用,在Application模式下,这些作业会被视为同一个应用,在同一个集群中执行(如果在Per-Job模式下,就会启动多个集群)。可见,Application模式本质上是Session和Per-Job模式的折衷。
用Application模式提交作业的示例命令如下:
bin/flink run-application -t yarn-application -Djobmanager.memory.process.size=2048m -Dtaskmanager.memory.process.size=4096m -Dtaskmanager.numberOfTaskSlots=2 -Dparallelism.default=10 -Dyarn.application.name="MyFlinkApp" /path/to/my/flink-app/MyFlinkApp.jar
注:-t参数用来指定部署目标,目前支持YARN(yarn-application)和K8S(kubernetes-application)。-D参数则用来指定与作业相关的各项参数。
查看集群的任务Job列表以及取消任务命令,如下:
# List running job on the cluster ./bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY # Cancel running job ./bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>
那么如何解决传输依赖项造成的带宽占用问题呢?Flink作业必须的依赖是发行版flink-dist.jar,还有扩展卡(位于$FLINK_HOME/lib)和插件库(位于$FLINK_HOME/plugin),我们将它们预先上传到像HDFS这样的共享存储,再通过yarn.provided.lib.dirs参数指定存储的路径即可。
-Dyarn.provided.lib.dirs="hdfs://myhdfs/flink-common-deps/lib;hdfs://myhdfs/flink-common-deps/plugins"
这样所有作业就不必各自上传依赖,可以直接从HDFS拉取,并且YARN NodeManager也会缓存这些依赖,进一步加快作业的提交过程。同理,包含Flink作业的用户JAR包也可以上传到HDFS,并指定远程路径进行提交。
./bin/flink run-application -t yarn-application -Dyarn.provided.lib.dirs="hdfs://myhdfs/my-remote-flink-dist-dir" hdfs://myhdfs/jars/my-application.jar
【参考资料】
https://www.sohu.com/a/406387061_100109711
https://zhuanlan.zhihu.com/p/354511839
https://www.jianshu.com/p/90d9f1f24937
原文:https://www.cnblogs.com/swordfall/p/14462486.html