1.Spark SQL出现的 原因是什么?
答:(1)Shark执行计划优化完全依赖于Hive,不便于添加新的优化策略。
(2)Spark是线程级并行,MapReduce是进程级并行,因此,Spark在兼容Hive的实现上存在线程安全问题,导致Shark不得不使用另外一套独立维护的、打了补丁的Hive源码分支。
(3)Shark的实现继承了大量的Hive代码,因而给优化和维护带来了大量的麻烦,特别是基于MapReduce设计的部分,成为整个项目的瓶颈。
2.用spark.read 创建DataFrame
答:(1)代码
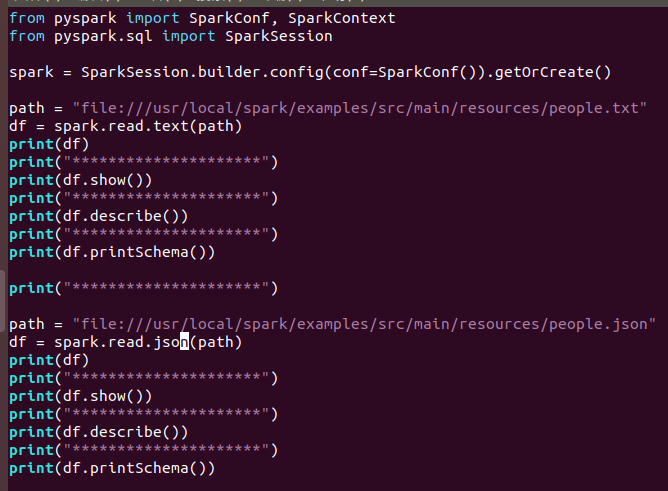
(2)运行结果
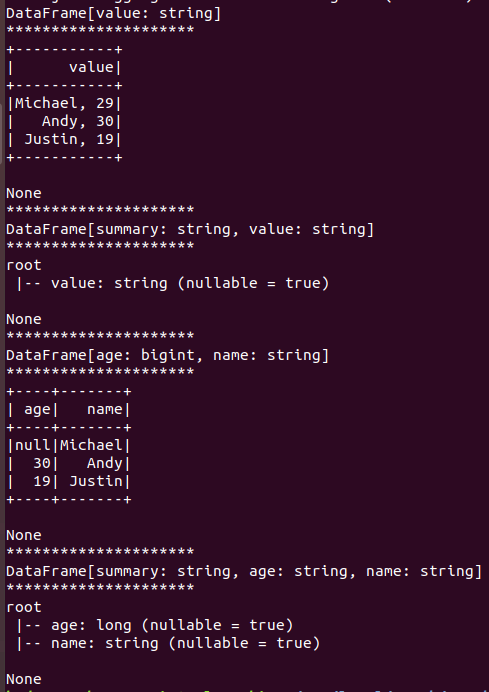
3.观察从不同类型文件创建DataFrame有什么异同?
答:(1)通过txt文本文件创建的DataFrame是一个键值对,键是“value”,值是整个文本文件的内容,类型为string类型;
(2)通过json文件创建的DataFrame可以是若干个键值对,键值对的键值类型与json文件内容一一对应。
4.观察Spark的DataFrame与Python pandas的DataFrame有什么异同?
答:(1)代码
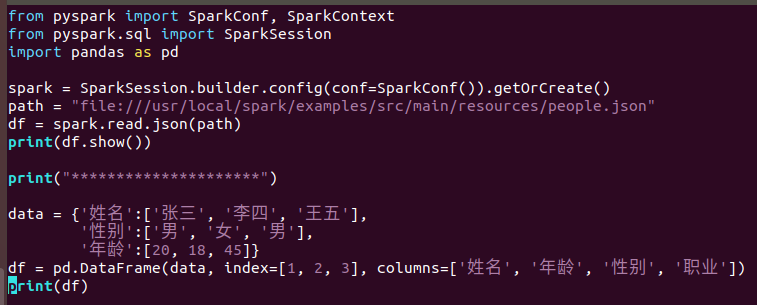
(2)运行结果
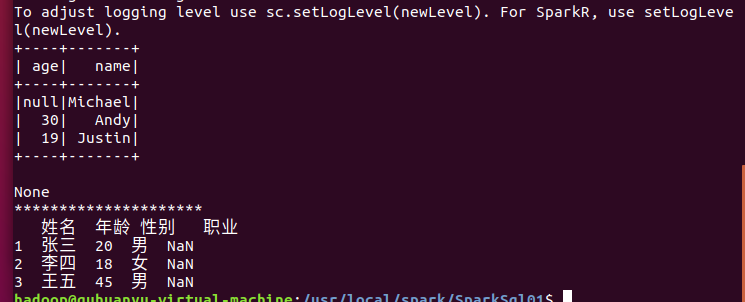
原文:https://www.cnblogs.com/ghy-blog/p/14748806.html