在过去的几年里,我们已经看到了关于系统架构的一系列想法。它们包括:
Alistair Cockburn的《六边形架构》(又名《端口和适配器》)被Steve Freeman和Nat Pryce在他们的书《面向对象的软件增长》中采用
Jeffrey Palermo 的洋葱架构
令人尖叫的架构,来自我去年的一篇博客
DCI来自James Coplien 与 Trygve Reenskaug。
Ivar Jacobso的BCE来自他的书面向对象的软件工程:一个用例驱动的方法
尽管这些架构在细节上有所不同,但它们非常相似。
它们都有一个相同的目标,即关注点分离。
它们都是通过划分层来实现这种分离。
每个系统至少有一层用于业务规则,另一层用于接口。
这些架构中的每一个都产生如下的系统:
独立的框架。他的体系结构不依赖于某些特性负载的软件库的存在。
这允许您使用这些框架作为工具,而不必将系统塞进它们有限的约束中。
可测试的。业务规则可以在没有UI、数据库、Web服务器或任何其他外部元素的情况下进行测试。
独立的UI。UI可以很容易地更改,而不需要更改系统的其余部分。例如,Web UI可以用控制台UI替换,而不需要更改业务规则。
与数据库无关。您可以将Oracle或SQL Server替换为Mongo、BigTable、CouchDB或其他内容。您的业务规则没有绑定到数据库。
独立于任何外部机构的。事实上,您的业务规则根本不了解外部世界。
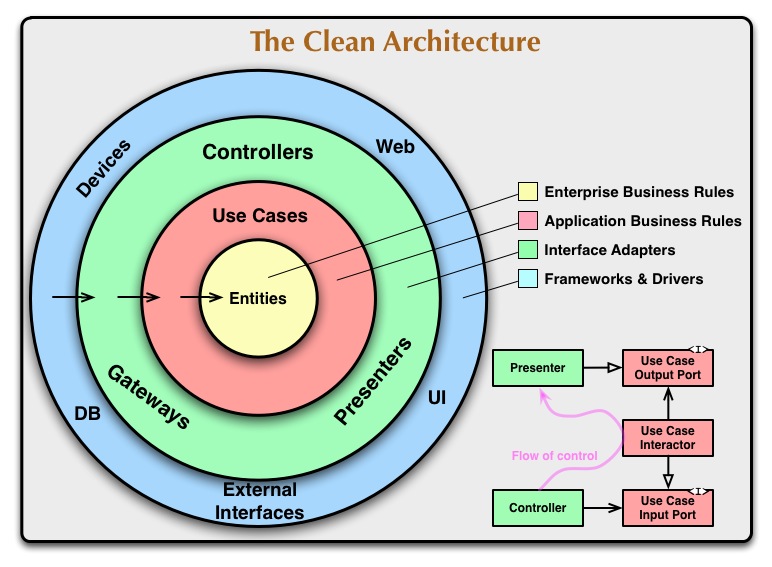
本文顶部的图试图将所有这些架构集成到一个可操作的想法中。
同心圆代表软件不同的区域。
一般来说,越深入,软件的级别就越高。
外层是机械装置。
核心是政策。
使这个体系结构工作的覆盖规则是依赖规则。
该规则指出,源代码依赖项只能指向内部。内部圈子里的任何东西都不可能了解外部圈子里的任何东西。
同样的,外圈使用的数据格式不应被内圈使用,特别是如果这些格式是由外部循环中的框架生成的。
特别是如果这些格式是由外部循环中的框架生成的。
实体封装了企业范围内的业务规则。实体可以是一个带有方法的对象,也可以是一组数据结构和函数。
只要实体可以被企业中许多不同的应用程序使用,就没有关系。
如果你没有一个企业,仅仅是写一个简单的应用,这些实体就是应用的业务对象。
它们封装了最通用的高级规则。当外部事物发生变化时,它们最不可能发生变化。
例如,您不会期望这些对象会受到页面导航或安全性更改的影响。
任何特定应用程序的操作更改都不会影响实体层。
这一层的软件包含特定的业务规则。
它封装并且实现了所有的系统用例。
这些用例编排进出实体的数据流,
并且指导这些实体用它们企业范围的业务规则来实现用例的目标。
我们不希望这层的变更影响到实体。
我们也不希望这一层收到外部因素(比如数据库、UI或者通用框架)的影响。
这一层与这些关注点隔离开来。
然而,我们确实希望对应用程序操作的更改将影响用例,从而影响这一层中的软件。
如果用例的细节发生变化,那么这个层中的一些代码肯定会受到影响。
这一层中的软件是一组适配器,它们将数据从对用例和实体最方便的格式转换为,
到一些外部机构(如数据库或Web)最方便的格式。例如,这一层将完全包含GUI的MVC架构。
演示者,视图和控制器都属于这里。
模型很可能只是从控制器传递到用例,然后从用例返回到演示者和视图的数据结构。
类似地,在这层,数据转换,从形式上最方便实体和用例,
转换成最方便使用的任何持久性框架的形式。例如数据库。
这个圈内的任何代码都不应该对数据库有任何了解。
如果数据库是SQL数据库,那么所有SQL都应该限制在这一层,特别是这一层中与数据库有关的部分。
在这一层中还需要任何其他适配器来将数据从某些外部形式(如外部服务)转换为用例和实体使用的内部形式。
最外层通常由框架和工具组成,如数据库、Web框架等。
通常情况下,除了向内与下一个循环通信的粘合代码外,您不会在这个层中编写太多代码。
这一层是所有细节的所在。网络是一个细节。
数据库是一个细节。我们把这些东西放在外面,它们不会造成什么伤害。
不,这些圈知识原理图。你可能会发现你需要的不仅仅是这四个。
没有规定说你必须只拥有这四种。
然而,依赖规则总是适用的。源代码依赖关系总是指向内部。
当您向内移动时,抽象级别会增加。最外面的圆圈是低层次的具体细节。
当您向内移动时,软件会变得更加抽象,并封装更高级别的策略。最里面的圈子是最一般的。
在图的右下角是一个我们如何跨越圆边界的例子。
它显示了控制器和呈现器在下一层与用例的通信。注意控制流程。
它从控制器开始,在用例中移动,然后在演示器中执行。
还要注意源代码依赖关系。每一个都指向用例的内部。
我们通常使用依赖倒置原理来解决这个明显的矛盾。
例如,在Java这样的语言中,我们会安排接口和继承关系,使源代码依赖关系恰好在边界上的正确点与控制流相对。
例如,考虑用例需要调用演示者。
但是,这个调用不能是直接的,因为这样会违反依赖规则:外圈的名字不能被内圈提到。
因此,我们让用例调用内圈中的接口(在这里显示为用例输出端口),并让外圈中的演示者实现它。
使用相同的技术来跨越架构中的所有边界。
我们利用动态多态性来创建与控制流相反的源代码依赖,这样无论控制流往哪个方向走,我们都可以遵循依赖规则。
通常,跨越边界的数据是简单的数据结构。如果愿意,您可以使用基本的结构或简单的数据传输对象。
或者数据可以只是函数调用中的参数。或者,您可以将其打包到一个散列表中,或者将其构造成一个对象。
重要的是,隔离的、简单的数据结构是跨边界传递的。我们不想欺骗和传递实体或数据库行。
我们不希望数据结构有任何违反依赖规则的依赖。
例如,许多数据库框架返回一种方便的数据格式来响应查询。
我们可以称之为RowStructure。我们不想让这个行结构通过边界向内传递。
这将违反从属规则,因为它将迫使内圆知道外圆的一些事情。
因此,当我们跨越边界传递数据时,它总是以对内圈最方便的形式传递。
遵循这些简单的规则并不难,而且会为你以后省去很多麻烦。
通过将软件划分为多个层,并遵循依赖规则,您将创建一个具有内在可测试性的系统,并具有它所暗示的所有好处。
当系统的任何外部部分过时时,如数据库或web框架,您可以用最少的麻烦替换这些过时的元素。
原文链接:http://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html
原文:https://www.cnblogs.com/w3liu/p/14749143.html