https://github.com/NWU-NISL-Fuzzing/COMFORT
P1: 背景:为了提升效率,应当遵循ECMAScript规范,但是有难度
P2:
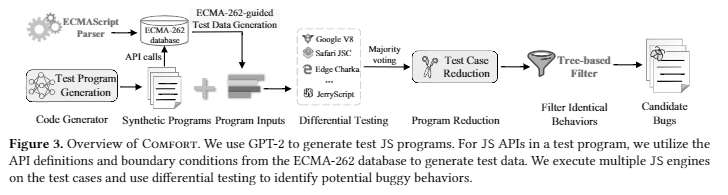
工具: COMFORT
任务:探测偏离ECMAScript规范的JS引擎行为及bugs
主要方法:深度学习来生成JS test code
实验A:
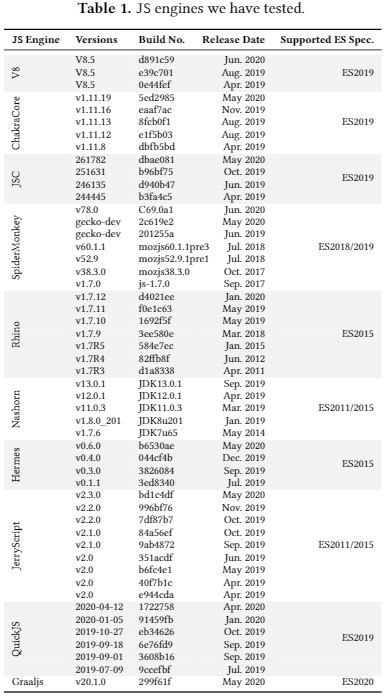
测试对象:10个主流JS引擎
时长200hr
效果:
P1: JS用途广;ECMA规范复杂
P2:
fuzzing常用;
fuzzing常和差分测试合起来用;
test case:在针对JS的fuzzing中,生成的testcase + 输入,二者合起来称为一份test case
潜在的bugs可能来自crash, freeeze, 差分时inconsistent compliation or execution outcomes
P3:
生成test case很难
已有方法:
已有方法的问题:需要人工构建语法,或者需要高质量种子集合
P4:
本文提出COMFORT,生成式fuzzer
集中于性能bugs,
主要方法:使用了GPT-2来生成test case
本文认为GPT-2可以更好地对程序中存在的依赖关系进行建模
P5:
现有的编译器fuzzers一般都要依赖变量的类型信息来生成随机test case中的kernel或者functional parameters,但是js是weakly typed language,同个变量名不仅能够代表任意类型的数据,还能代表多个变量。这点使得input settings的空间变得更大。
为此,就需要一种方法来提高测试效率,这里COMFORT直接用了ECMA规范本身,不过具体利用方法到这里还不明确(似乎就是直接学习了Test262)。

COMFORT draws hints from ECMA-262. It leverages the well-structured specification rules defined in the specification document to narrow down the scope of argument types and boundary values for JS APIs and edge cases that are likely to trigger unusual behavior.
P6: 介绍实际效果
实验A:
测试对象:10个主流JS引擎: Apple Safari的JavaScriptCore, Google Chrome的V8,Edge的ChakraCore, Firefox的SpiderMonkey, 嵌入式的Hermes, QuickJS, Rhino, Nashorn, JerryScript,兼容ECMAScript 2020的Graajs
时长200hr
效果:
介绍了ECMA262以及其测试集合Test262(具有38k test cases)
只要是和规范不同的都称为conformance bug
Given implementations of multiple JS engines J and a version of the ECMA-262 specification E, a conformance bug is an unexpected behavior in J that occurs due to a violation to the specification in E.
感觉不到定义的必要性

COMFORT只测和ECMA262相关的conformance bug,而且会人工检验,确保出现bug的feature被待测JS引擎所支持

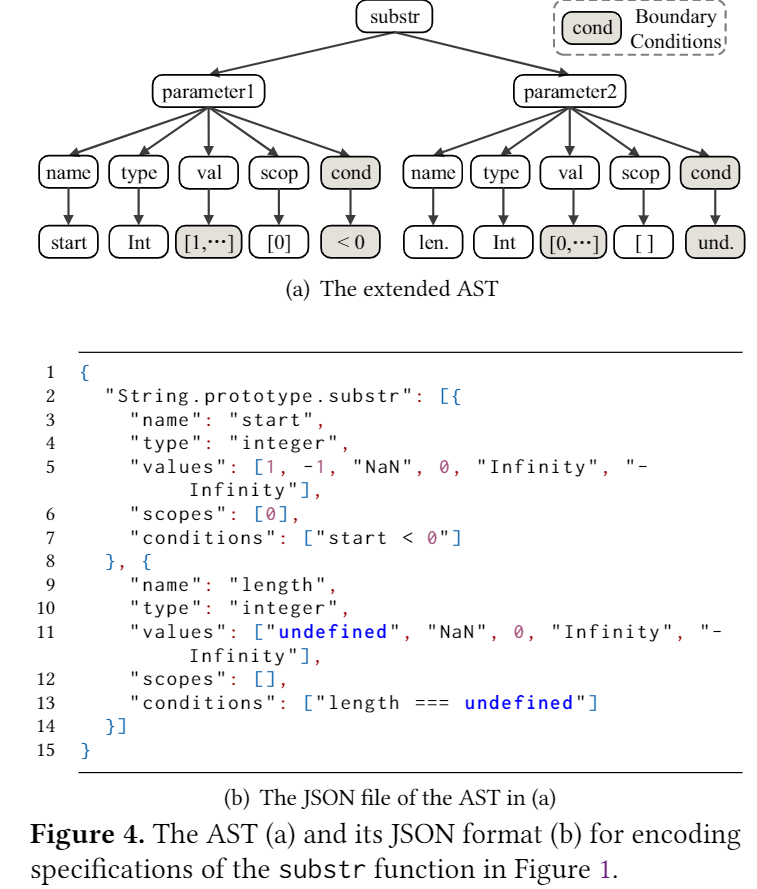
为了产生Fig2所示测试用例,fuzzer需要了解上下文,即,它需要产生一个String对象,并确保在传递给substr之前未定义len变量,本文认为传统fuzzer生成这样的测试用例是比较难的(真的么?)
用了开源提前训练好的GPT-2模型
输入: HTML版本的ECMA262
步骤:
Note: 这一套方案大概覆盖了ECMA262(2019版)的82% API
GPT-2, instruction/constant/variable都有对应vocabulary和编号,vocabulary遵循Byte Pair Encoding
如何构建vocabulary: 目的: 用尽量少的tokens数目将词划分为subwords,再将subwords对应到vocabulary table的序号上
训练语料: 4k个JS项目中,取到14k JS程序
训练层数: GPT-2的最后两层
Adam(0.0001, 10% decay) + 150k iteration each epoch + 100 epochs
GTX 2080Ti 30 hr
每次用随机数从2000个function header中选出一个header(比如 “var a = function(assert) {”) ,然后放入GPT-2中生成剩余的部分
top-10
用JSHint移除掉语法无效的输入

变异:
使用离线提取的ECMA-262规则来确定应将多少个参数传递给一个函数,以及每个参数的类型和值。对于每种参数类型,我们根据(1)根据ECMA-262规范的边界条件(例如,在图1中,参数len设置为undefined)和(2)正常条件(使用随机值)对值进行突变。为了使变量值发生突变,我们通过遍历JS程序的控件和数据流图(第8行),将传递给函数的参数与函数的定义关联起来。
使用多数表决方案,通过比较编译和执行的结果来确定哪个编译器的行为与其他行为有所不同。
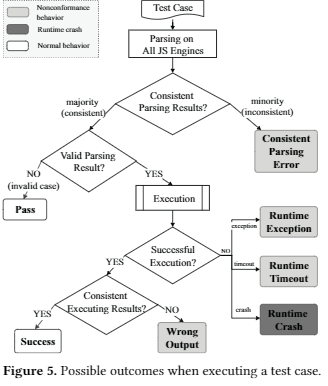
忽略了所有JS引擎都不会在十分钟内终止的测试用例,因为这很可能是由于测试程序中的循环较大或无限循环所致。
遍历AST,不断删掉一些结构
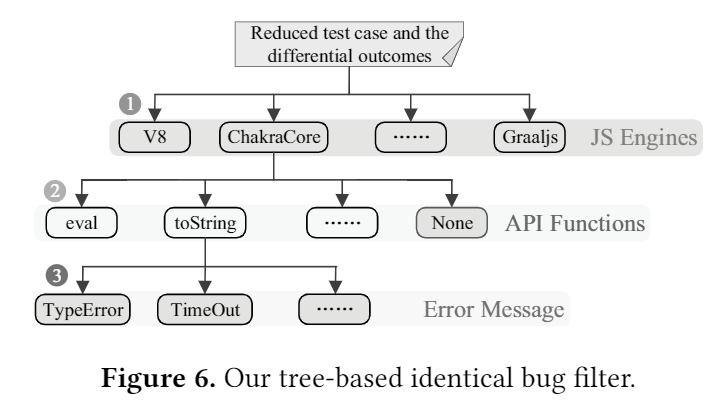
如果已经存在一个路径,该路径给出了相同的信息(被测试用例放置)。如果是,则我们认为找到了以前识别的错误。
目前已经积累了2300个叶节点的知识库
COMPORT首先生成300k测试用例,然后用JSHint,在保留10k语法不正确的test cases的条件下,最后大约拿到250k test cases
Fuzzilli, CodeAlchemist, DIE, Montage
Our evaluation platform is a multi-core server with a 3.6GHz 8-core (16 threads) Intel Core i7 CPU, four NVIDIA GTX 2080Ti GPUs and 64GB of RAM,running Ubuntu 18.04 operating system with Linux kernel 4.15.
P1: 运行参数,比如运行时长
P2: bugs数目分布
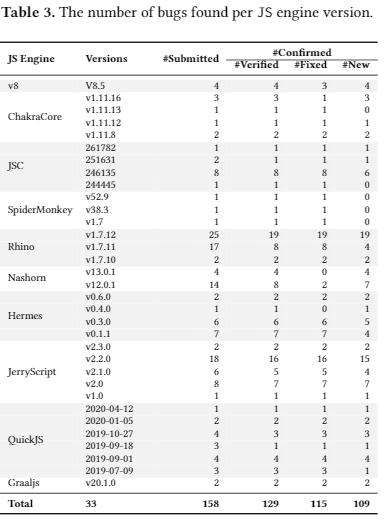
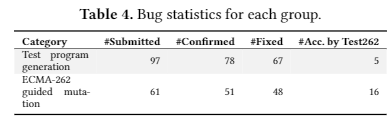
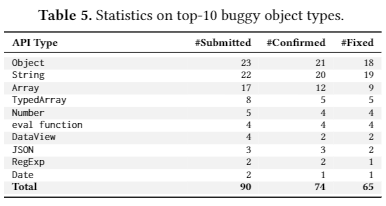
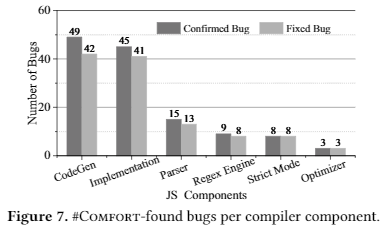
分别在bugs数目分配,类型分布(是通过test program generation的还是利用ECMA规范的),API分布和组件分布来描述了发现的结果









基本会描述

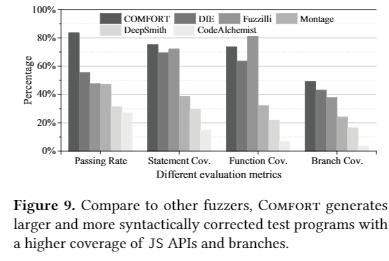
从bug数目(COMFORT发现的错误数目,类别覆盖数目,交并差情况和仅仅由COMFORT发现的错误数目),其他fuzzers生成的但是COMFORT无法生成的test case(包括为甚么,比如训练语料里面没有这个函数,undefined behavior)基本例子,COMFORT自身的test case质量(syntax passing rate, coverage(statement, function, branch))对比
我们报告的大多数错误已被开发人员确认并修复,从而说明了它们的相关性和重要性
jsfunfuzz, Domato, PHOG, CSmith, CLSmith
区别: deep learning
SYMFUZZm Langfuzz, AFL, IFuzzer, DIE, CodeAlchemist
区别: 1. 黑盒,不需要源码
AutoTest
区别: COMFORT只测编译器相关的
DeepSmith, DeepFuzz, Montage
本文: 神经网络更先进复杂
JEST, JISET
JISET基于变异
原文:https://www.cnblogs.com/xuesu/p/14749516.html