因为爬虫代码突然爬取失败了,因此拿来调试;
用pycharm调试scrapy爬虫代码时,代码思路、流程都是ok的,理论来说应该可以按逻辑走,而且以前也是调通过的;
但就是无法debug到 parse() 方法中;
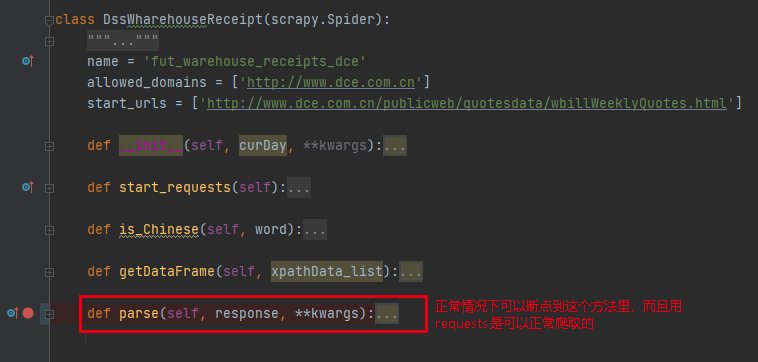

看了下scrapy打印的日志,看到了上图信息;
关键点在这里:robots.txt、Forbidden by robots.txt
目标网站的 robots 协议不允许,爬虫、搜索引擎向目标URL发送POST请求,然而我的操作就是向其发送POST;
(robotst.txt 会告诉爬虫、搜索引擎哪些页面可以抓取,哪些页面不能抓取,进而起到限制的效果。)
解决这个问题应该着眼于 robots.txt,幸运的是scrapy框架可以直接在配置项中解决这个问题;
scrapy 项目目录下有一个 settings.py 文件;
里面有这么个默认配置:
# Obey robots.txt rules ROBOTSTXT_OBEY = True # 默认为True
他的作用是:是否遵守 robots.txt 的规则
Scrapy启动后,会在第一时间访问网站的 robots.txt 文件,然后决定该网站的爬取范围。
我们可以将此项设置为False,拒绝遵守robots协议,进而规避掉一些爬虫失败风险
(拿来实验可以,建议大家还是要遵守人家的robots协议)
# Obey robots.txt rules ROBOTSTXT_OBEY = False # 默认为True
改了之后问题解决,可以debug进parse方法了~

关于如何用pycharm调试scrapy,可以参考:
https://www.cnblogs.com/bigtreei/p/14701520.html
pycharm调试scrapy踩坑记录(debug过程无法走parse)
原文:https://www.cnblogs.com/bigtreei/p/14750429.html