摘要:对xgboost论文中的细节进行记录。
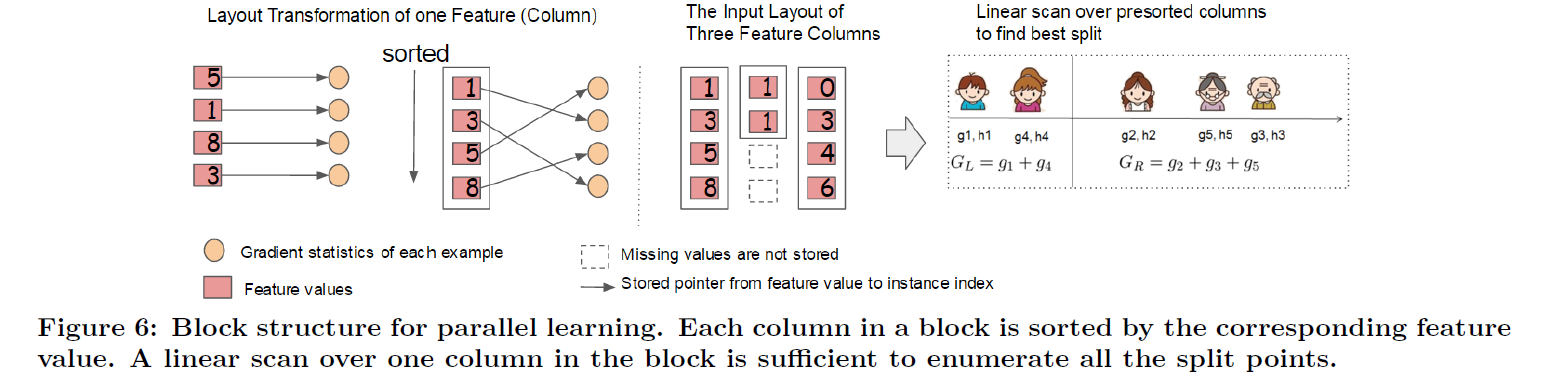
树学习最耗时的部分通常是对数据进行排序,为了降低排序带来的计算负荷,xgb使用基于block的结构对数据进行存储。每个block中的数据以compressed format(CSC)格式存储,每列按照数值大小进行排序。这样的数据结构仅需要在训练前计算一次,在后续的迭代过程中,可以重复使用。
对于精确算法,将所有数据保存在一个block中。建树的过程可以实现特征级别的并行,即每个线程处理一个特征。在单个线程内部,对数据的单次扫描可计算所有叶子节点在该特征上的最优分裂点。
对于近似算法,可以将不同的数据(按行)分布在不同的block中,并可以将不同的block分布到不同的机器。使用排好序的数据,qutile finding算法只需要线性扫描数据即可完成。
利用这样的结构,在对单个特征寻找分裂点时,也可以实现并行化,这也是xgb能够进行分布式并行的关键。
block结构降低了计算的复杂度,但也带来了另外一个问题,那就是对梯度信息的读取是不连续的,如果梯度信息不能全部装进cache,这会导致cpu缓存命中率降低,从而影响性能。
在精确算法中,xgb使用cache-aware prefetch算法缓解这个问题。也就是为每个线程分配一个buffer,将梯度信息读入buffer,并以mini-batch的方式进行梯度累加。
对于近似算法,解决缓存命中失效的方法是选择合适的block size。过小的block size导致单线程的计算负载过小,并行不充分,过大的block size又会导致cache miss,因此需要做一个平衡。论文建议使用的block size为2^16。
为进行核外计算,将数据划分为多个block。计算期间,使用独立线程将磁盘上的block结构数据读进内存,因此计算和IO可以同步进行。然而,这只能解决一部分问题,因为IO占用的时间要远多于计算。因此,xgb使用以下两种方式优化:
数据压缩(block compression):将block按列进行压缩,并使用独立线程解压缩。这样可以对IO和CPU的占用时间进行对冲。
数据分区(block sharding):将数据分散到多个磁盘,每个磁盘使用一个线程读取数据,以此提高磁盘吞吐量。
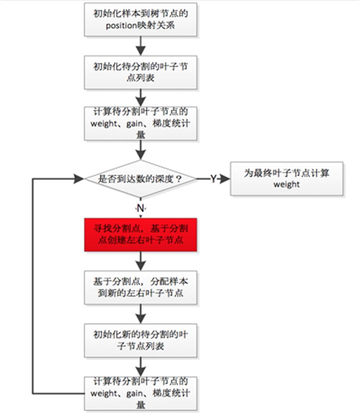
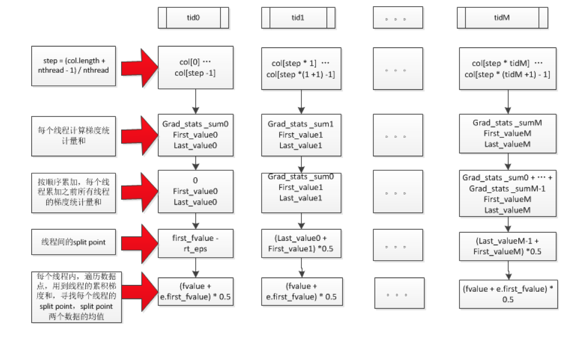
updater_colmaker.cc: ColMaker::Update() -> Builder builder; -> builder.Update() -> InitData() -> InitNewNode() // 为可用于split的树结点(即叶子结点,初始情况下只有一个 // 叶结点,也就是根结点) 计算统计量,包括gain/weight等 -> for (depth = 0; depth < 树的最大深度; ++depth) -> FindSplit() -> for (each feature) // 通过OpenMP获取 // inter-feature parallelism -> UpdateSolution() -> EnumerateSplit() // 每个执行线程处理一个特征, // 选出每个特征的 // 最优split point -> ParallelFindSplit() // 多个执行线程同时处理一个特征,选出该特征 //的最优split point; // 在每个线程里汇总各个线程内分配到的数据样 //本的统计量(grad/hess); // aggregate所有线程的样本统计(grad/hess), //计算出每个线程分配到的样本集合的边界特征值作为 //split point的最优分割点; // 在每个线程分配到的样本集合对应的特征值集合进 //行枚举作为split point,选出最优分割点 -> SyncBestSolution() // 上面的UpdateSolution()/ParallelFindSplit() //会为所有待扩展分割的叶结点找到特征维度的最优split //point,比如对于叶结点A,OpenMP线程1会找到特征F1 //的最优split point,OpenMP线程2会找到特征F2的最 //优split point,所以需要进行全局sync,找到叶结点A //的最优split point。 -> 为需要进行分割的叶结点创建孩子结点 -> ResetPosition() //根据上一步的分割动作,更新样本到树结点的映射关系 // Missing Value(i.e. default)和非Missing Value(i.e. //non-default)分别处理 -> UpdateQueueExpand() // 将待扩展分割的叶子结点用于替换qexpand_,作为下一轮split的 //起始基础 -> InitNewNode() // 为可用于split的树结点计算统计量
https://arxiv.org/pdf/1603.02754.pdf
http://www.ra.ethz.ch/CDstore/www2011/proceedings/p387.pdf
https://www.zhihu.com/question/41354392
https://weibo.com/p/1001603801281637563132
原文:https://www.cnblogs.com/zcsh/p/14752659.html